
Abstract
Learning long-term dynamics models is the key to understanding physical common sense. Most existing approaches on learning dynamics from visual input sidestep long-term predictions by resorting to rapid re-planning with short-term models. This not only requires such models to be super accurate but also limits them only to tasks where an agent can continuously obtain feedback and take action at each step until completion. In this paper, we aim to leverage the ideas from success stories in visual recognition tasks to build object representations that can capture inter-object and object-environment interactions over a long-range. To this end, we propose Region Proposal Interaction Networks (RPIN), which reason about each object's trajectory in a latent region-proposal feature space. Thanks to the simple yet effective object representation, our approach outperforms prior methods by a significant margin both in terms of prediction quality and their ability to plan for downstream tasks, and also generalize well to novel environments. We also achieve state-of-the-art performance on PHYRE physical reasoning benchmark.
Method
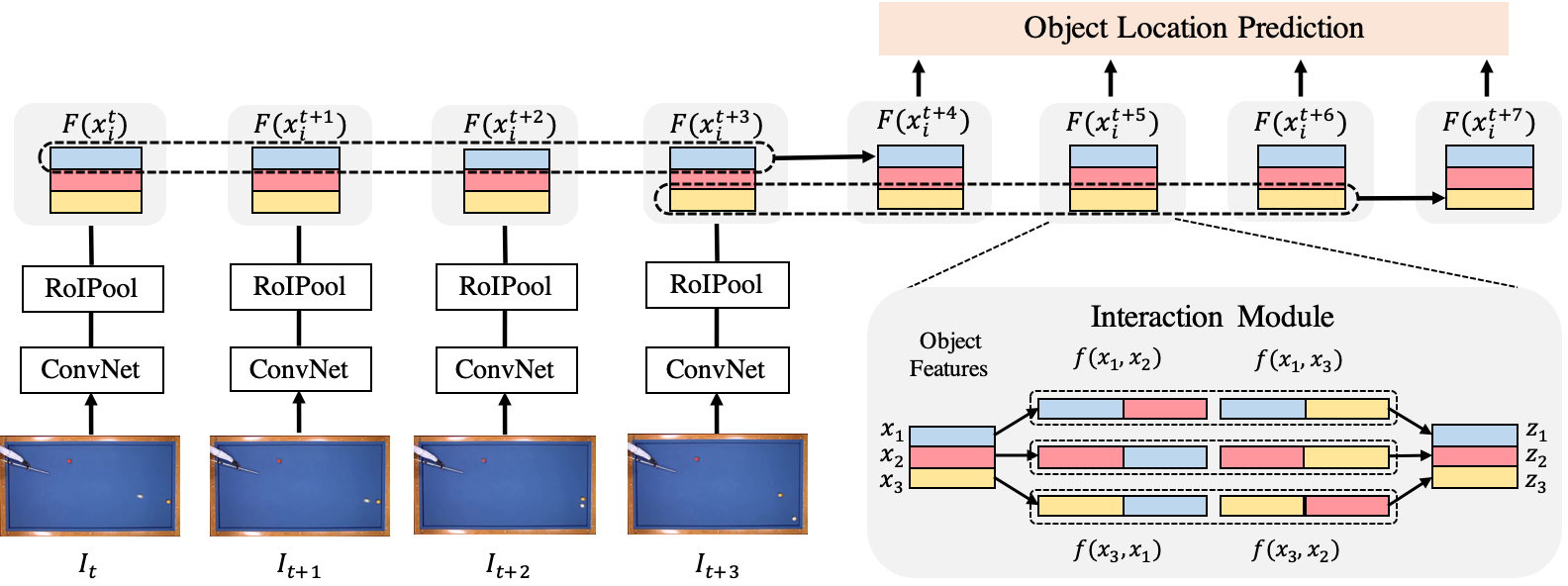
Our model takes N video frames as inputs and predicts the object locations for the future T timesteps, as illustrated above. We first extract the image feature representation using a ConvNet for each frame, and then apply RoI Pooling to obtain object-centric visual features. These object feature representations are forwarded to the interaction modules to perform interaction reasoning and predict future object locations. The whole pipeline is trained end-to-end by minimizing the loss between predicted and the ground-truth object locations. Since the parameters of each interaction module is shared so we can apply this process recurrently over time to an arbitrary T during testing.
Qualitative Results
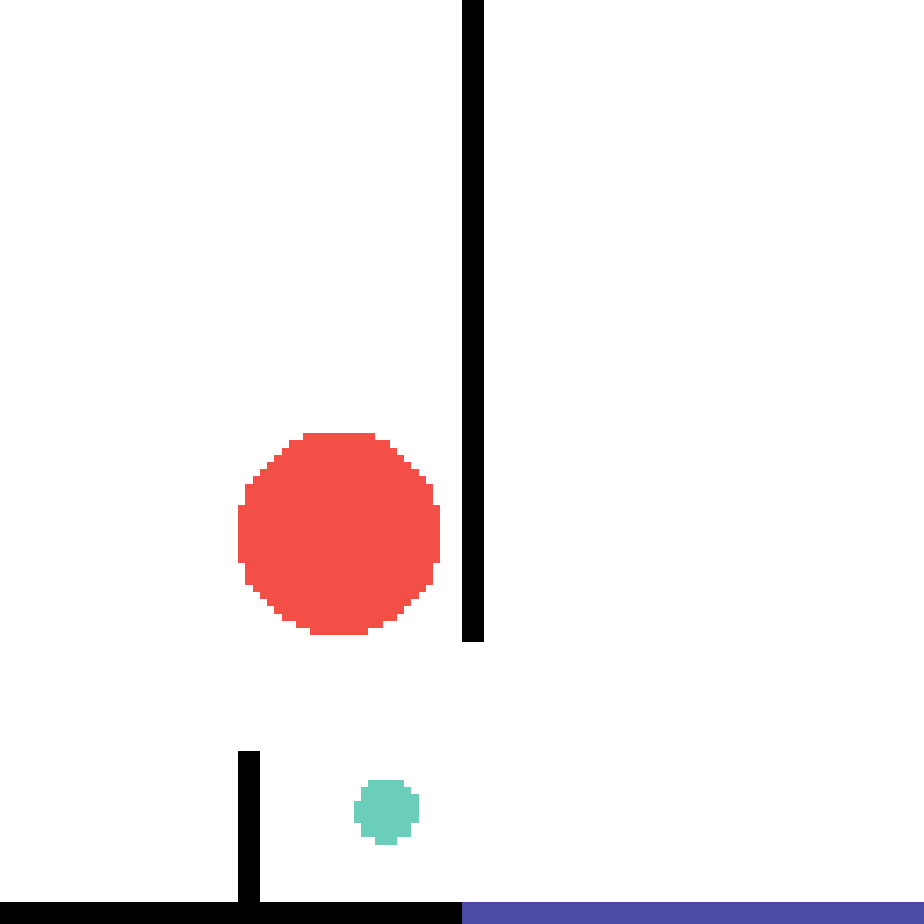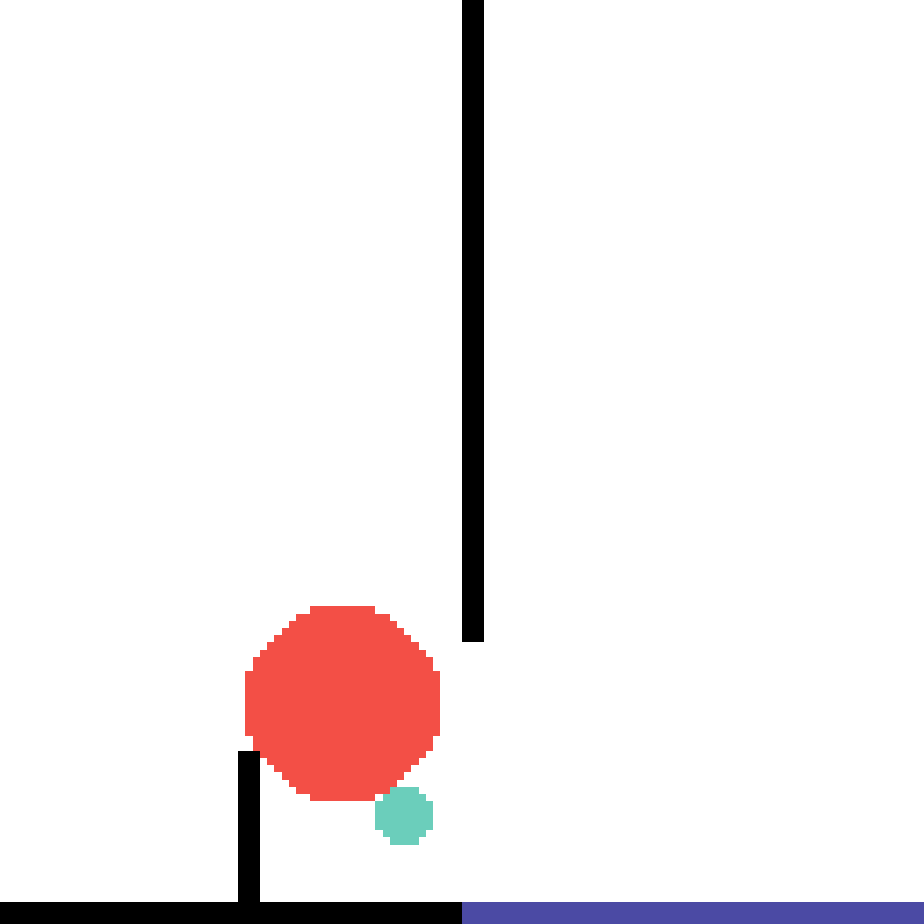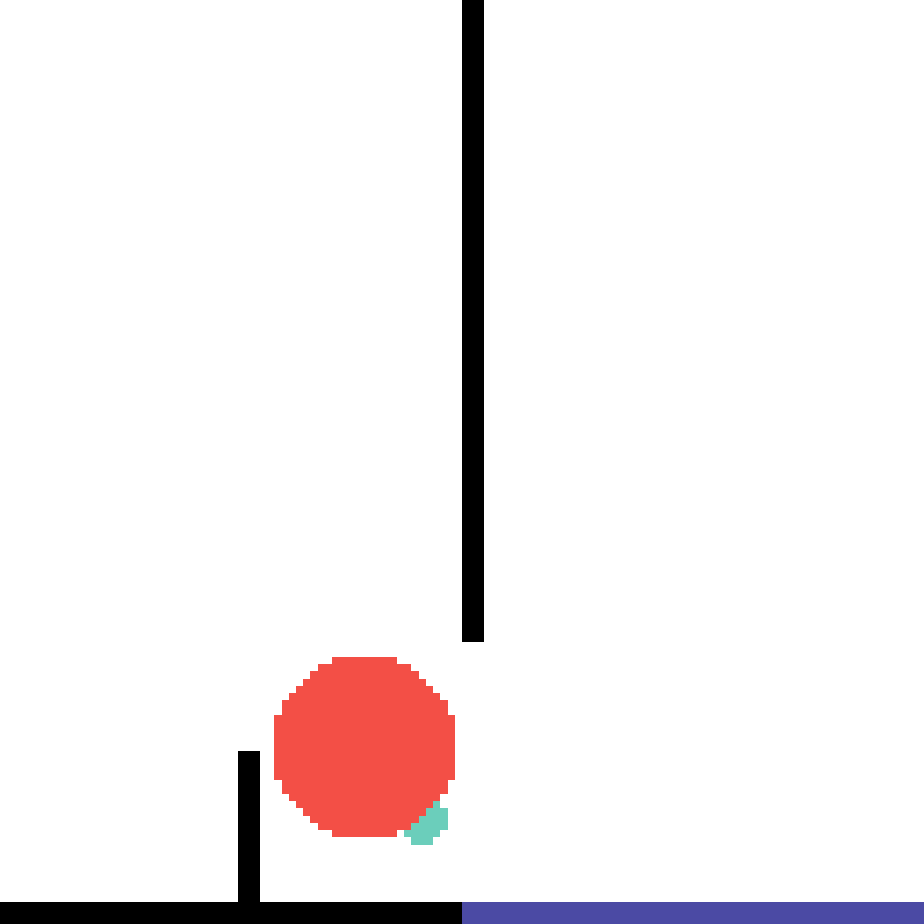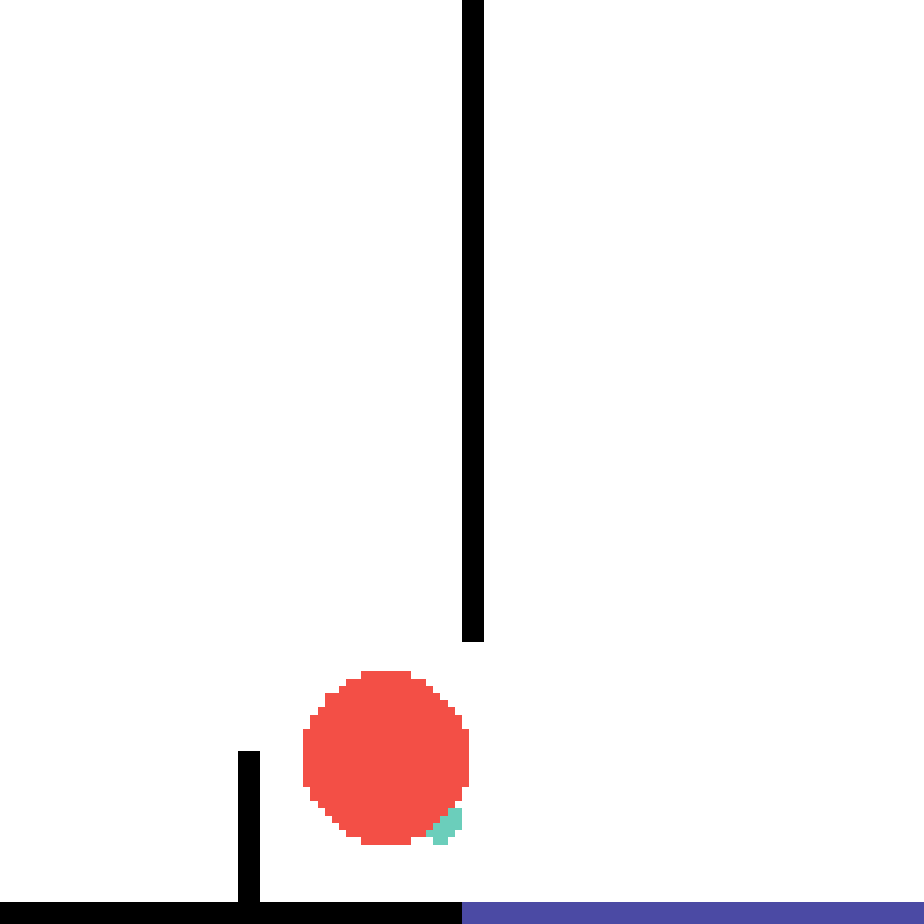
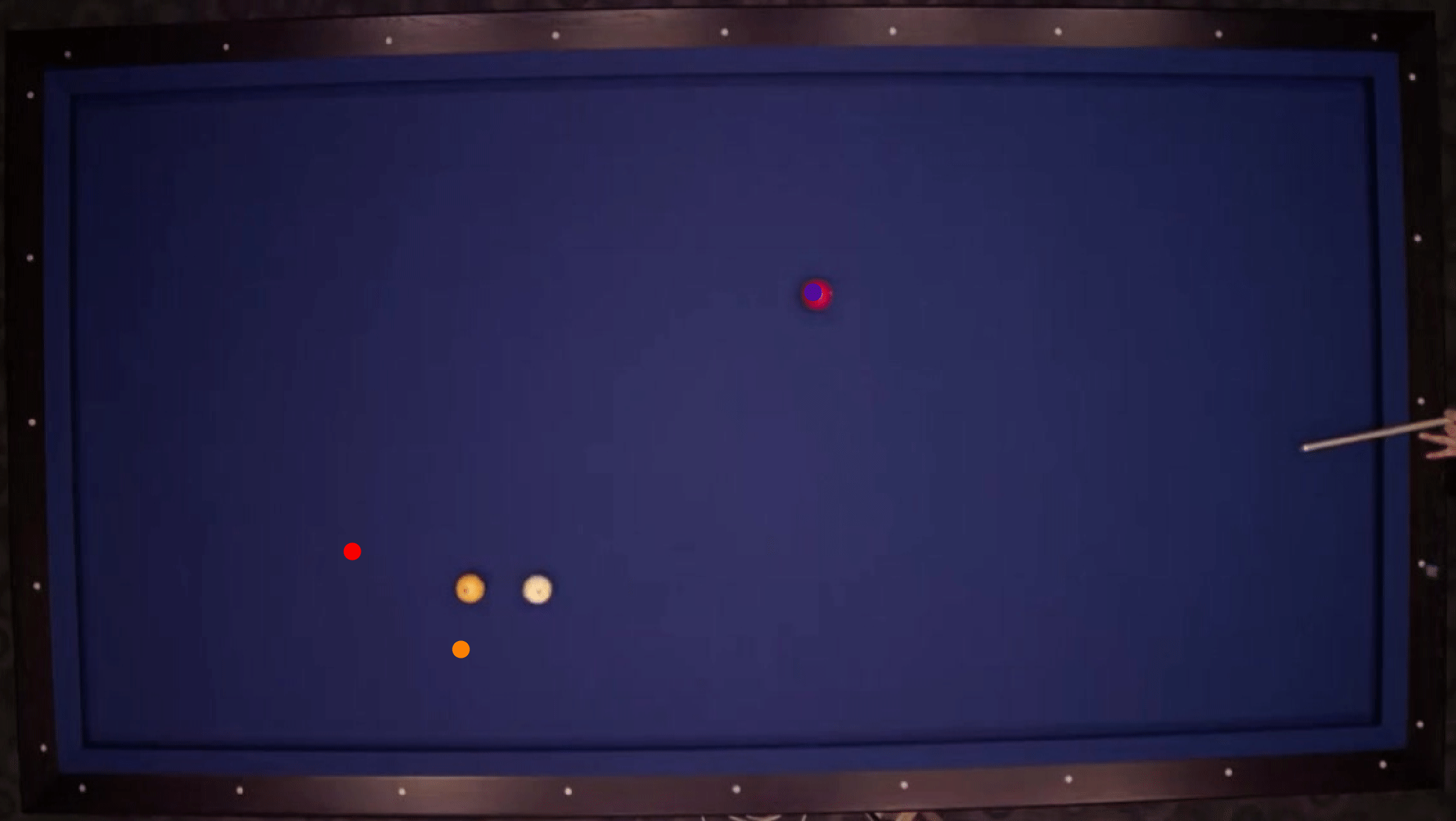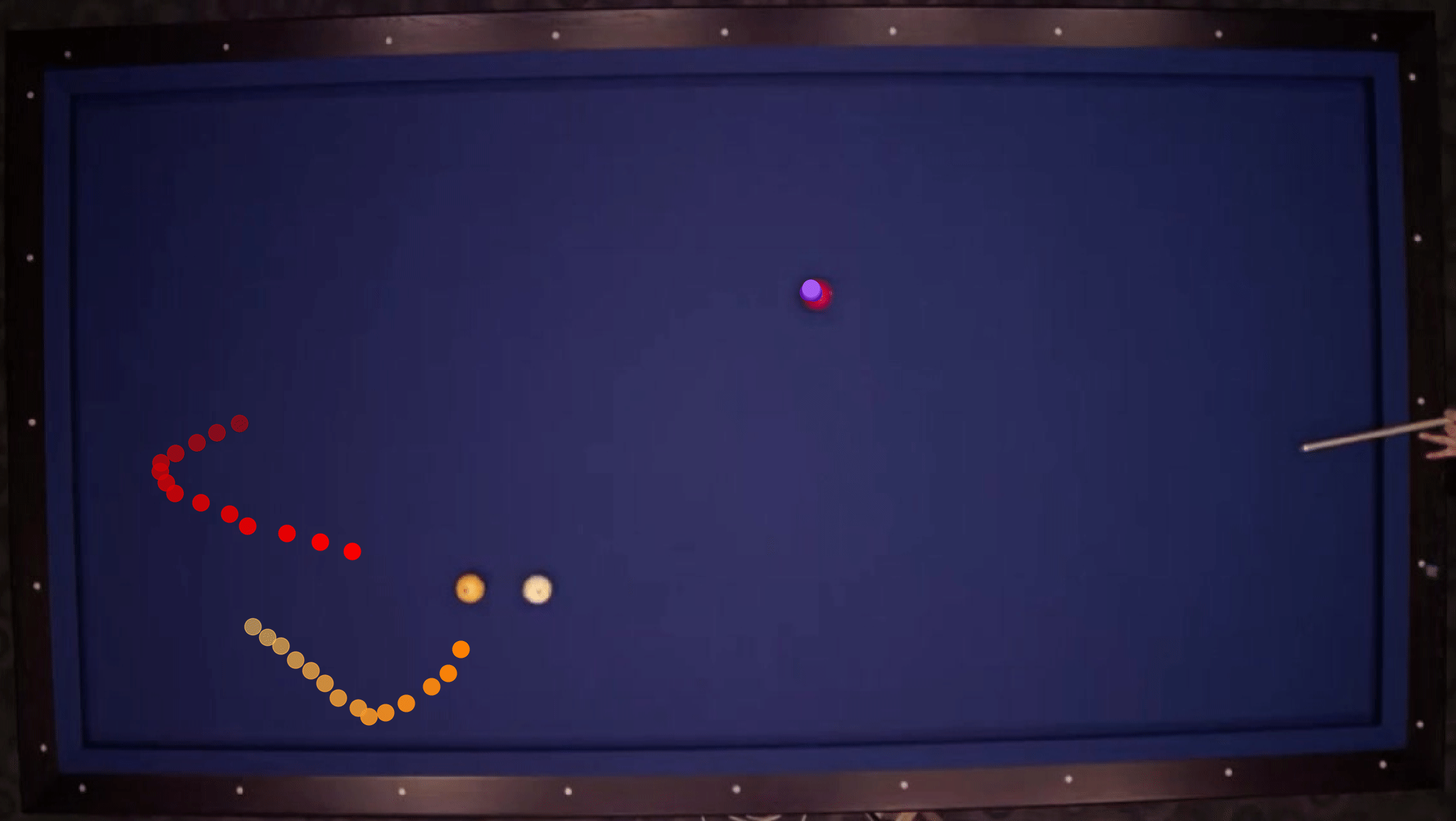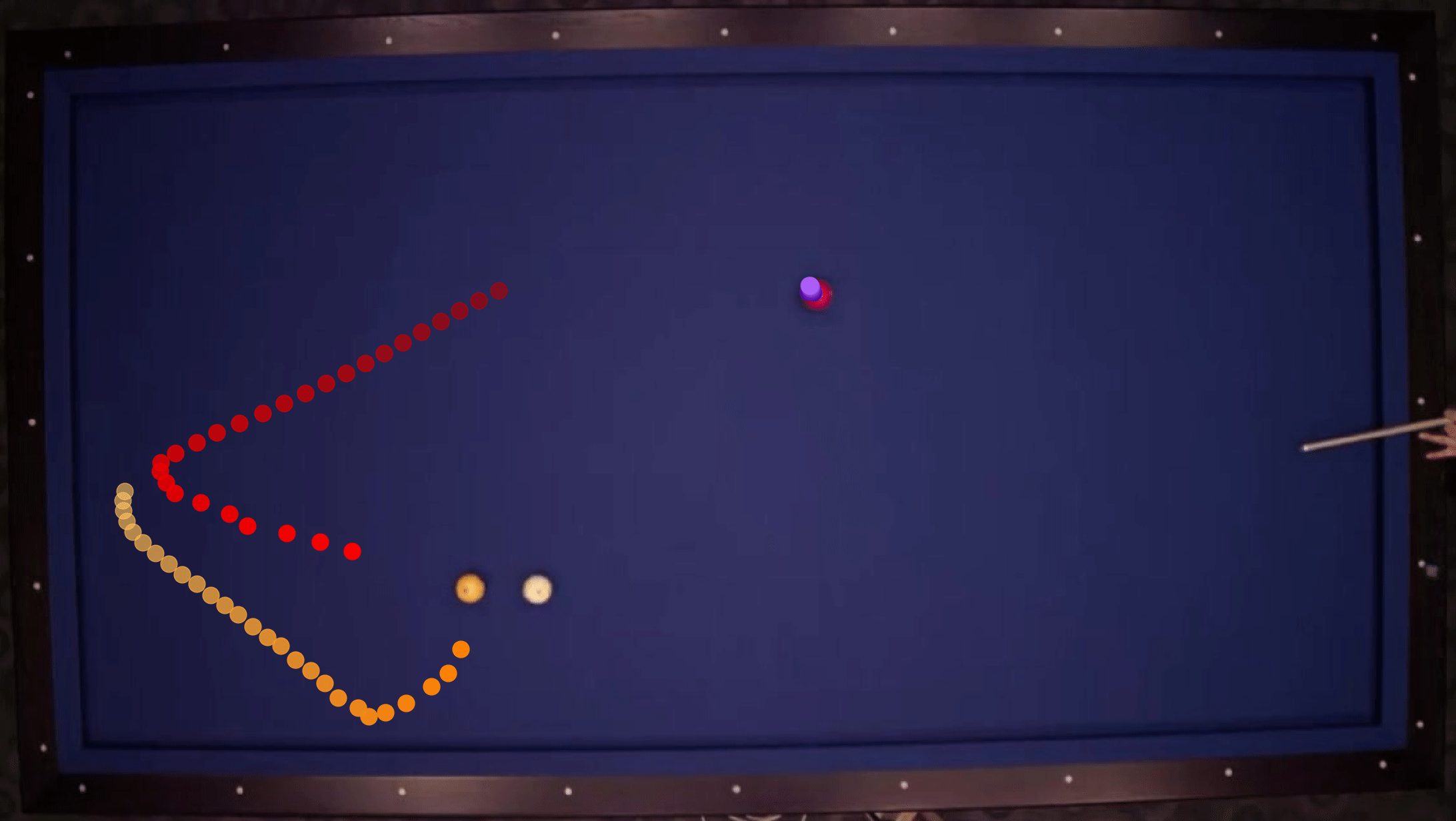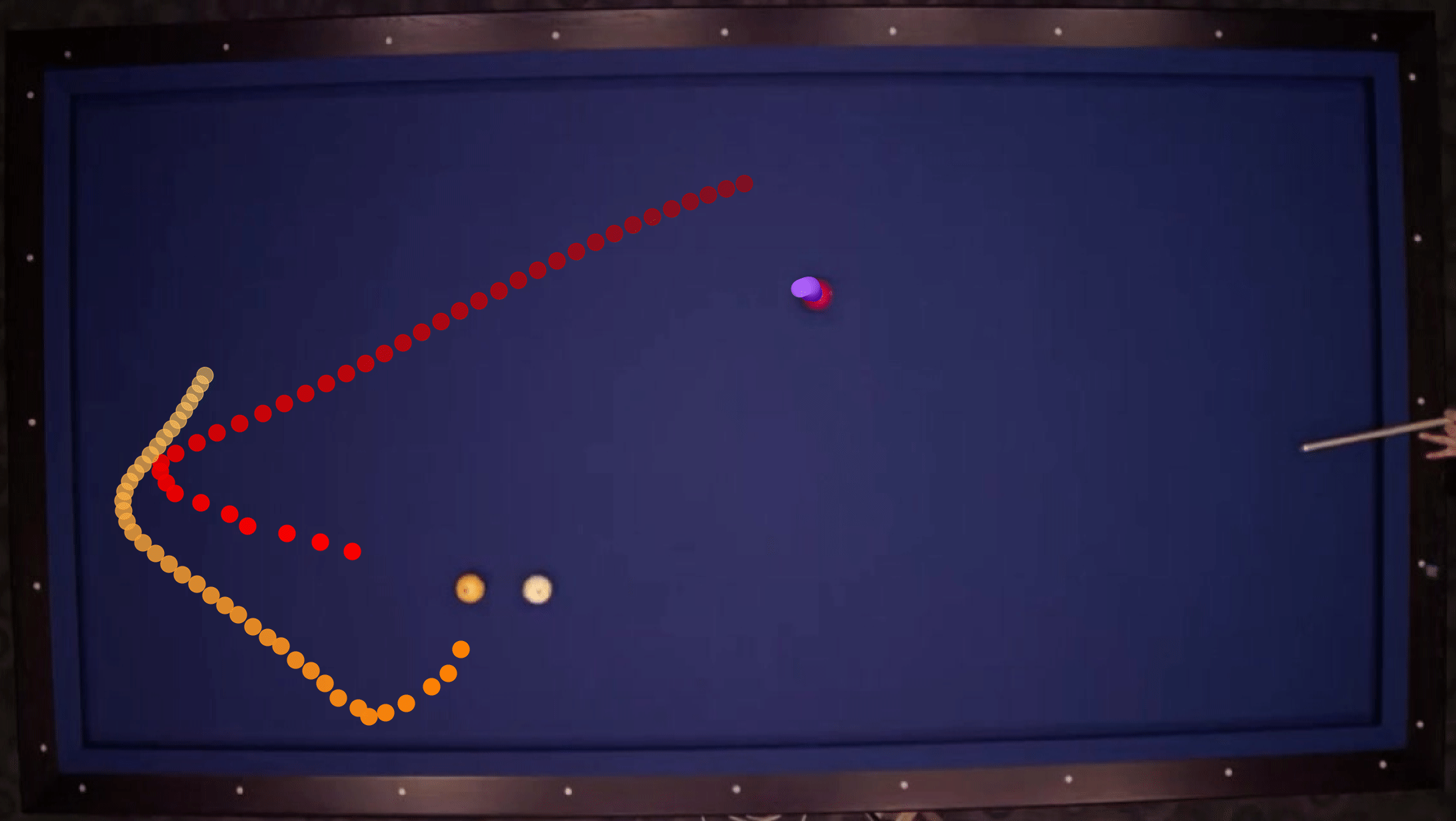
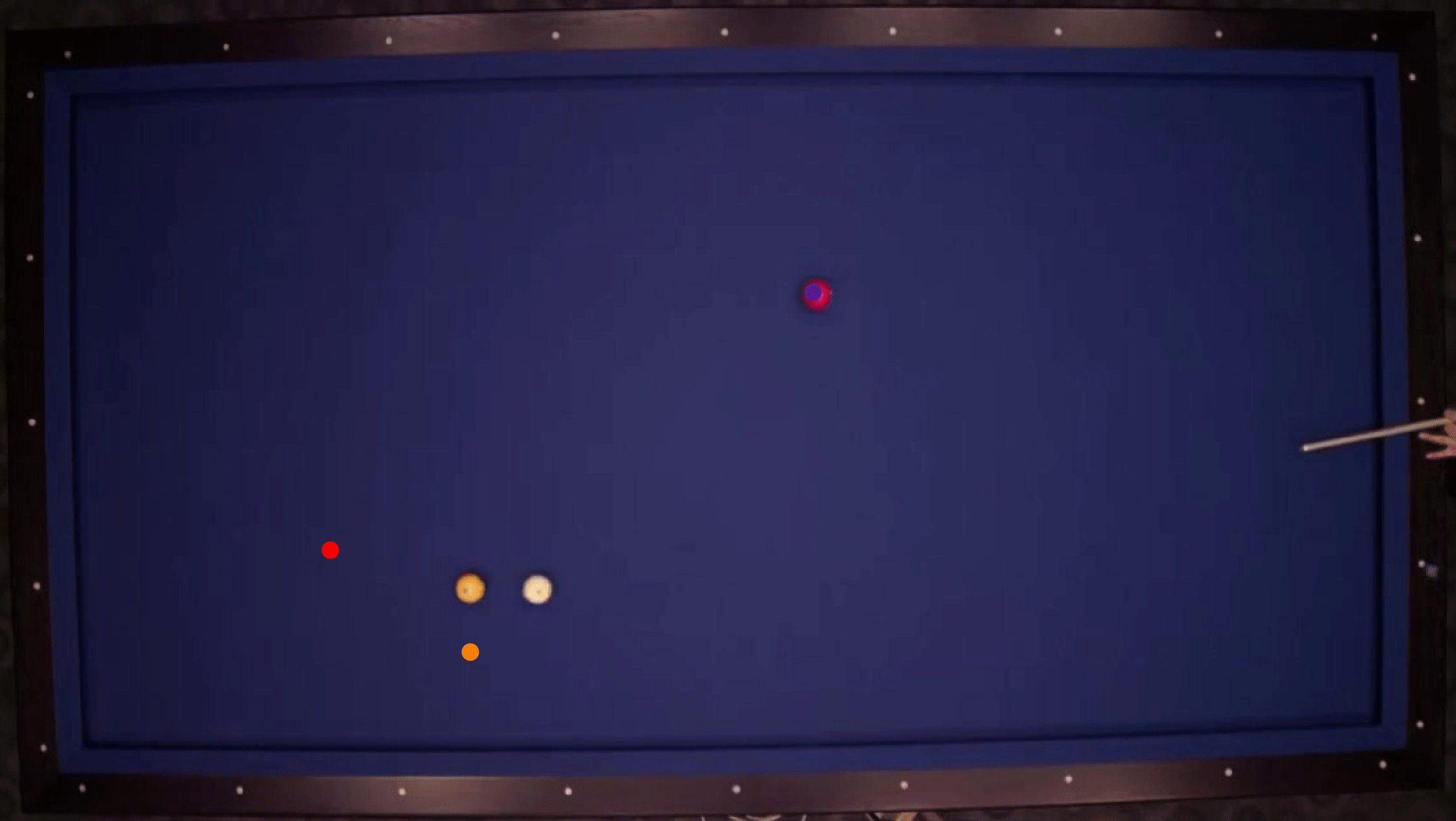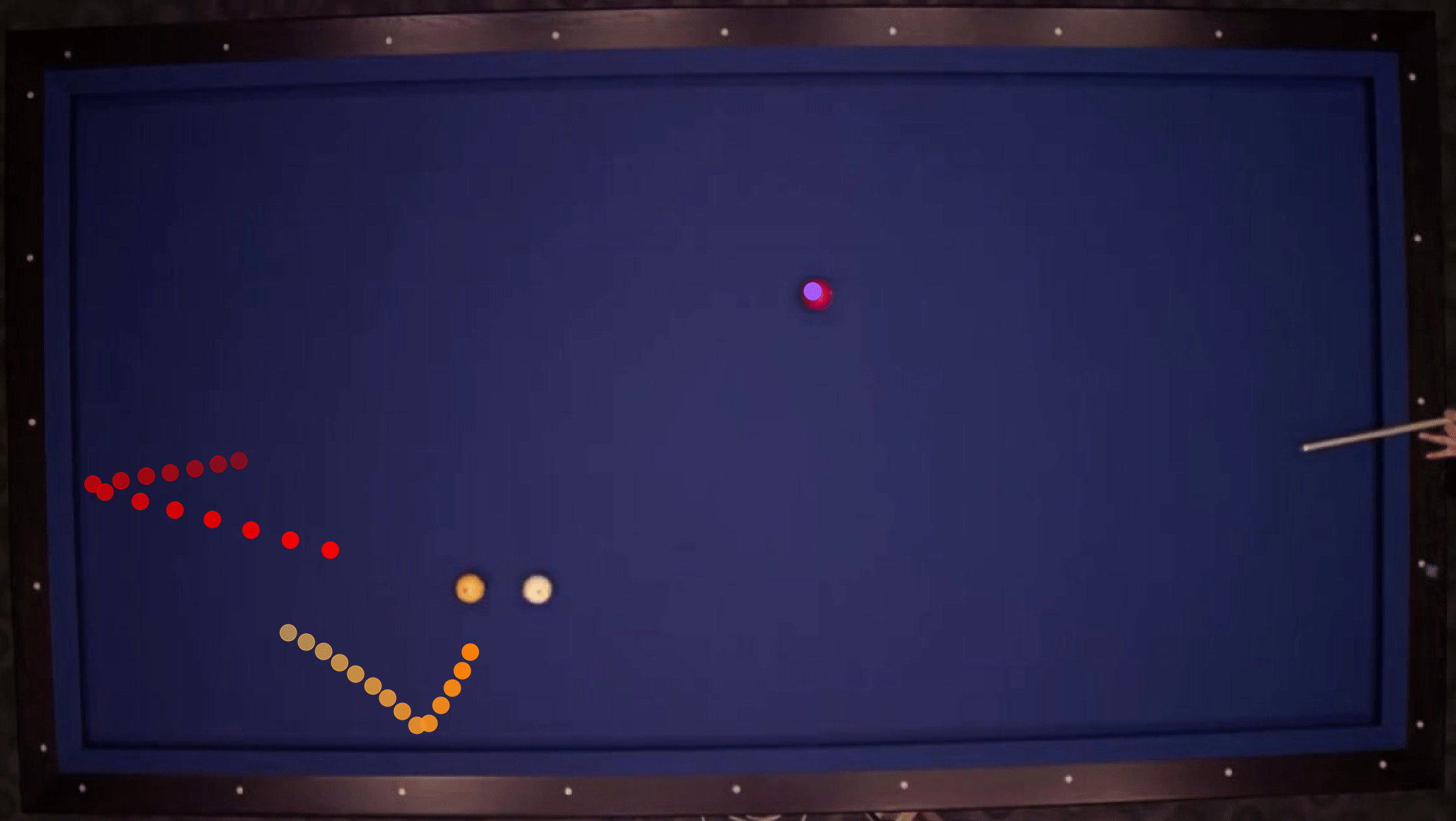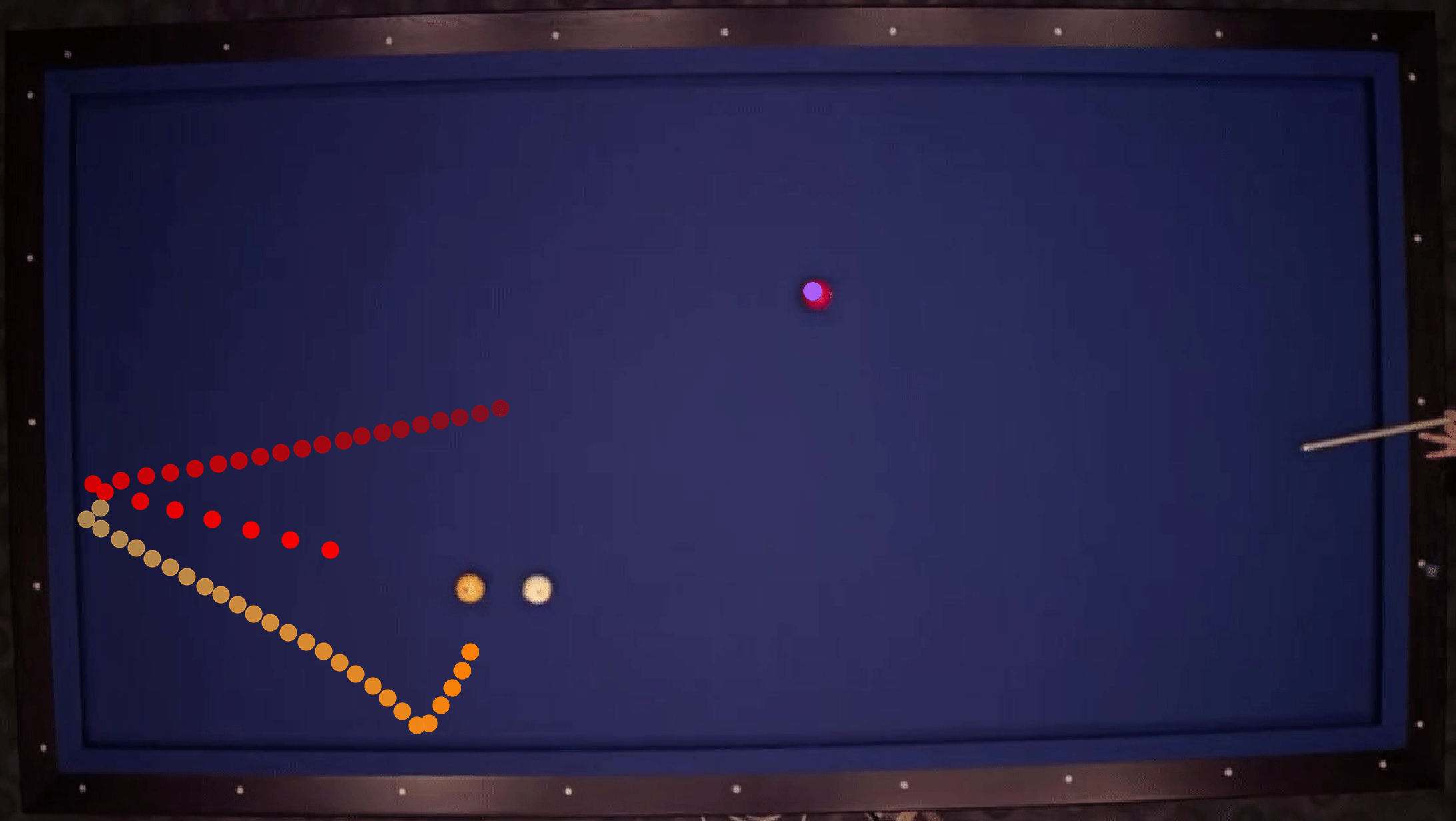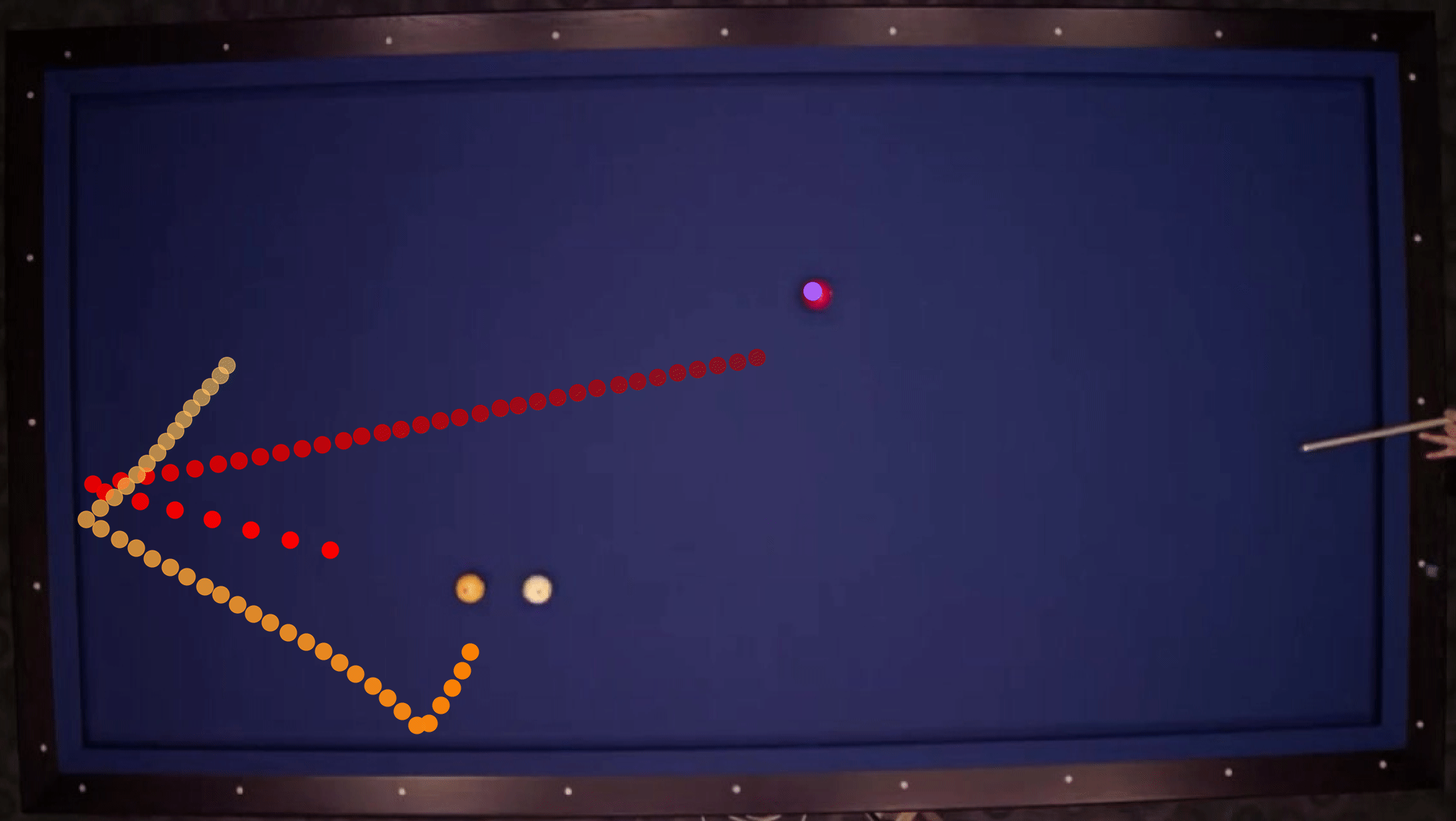
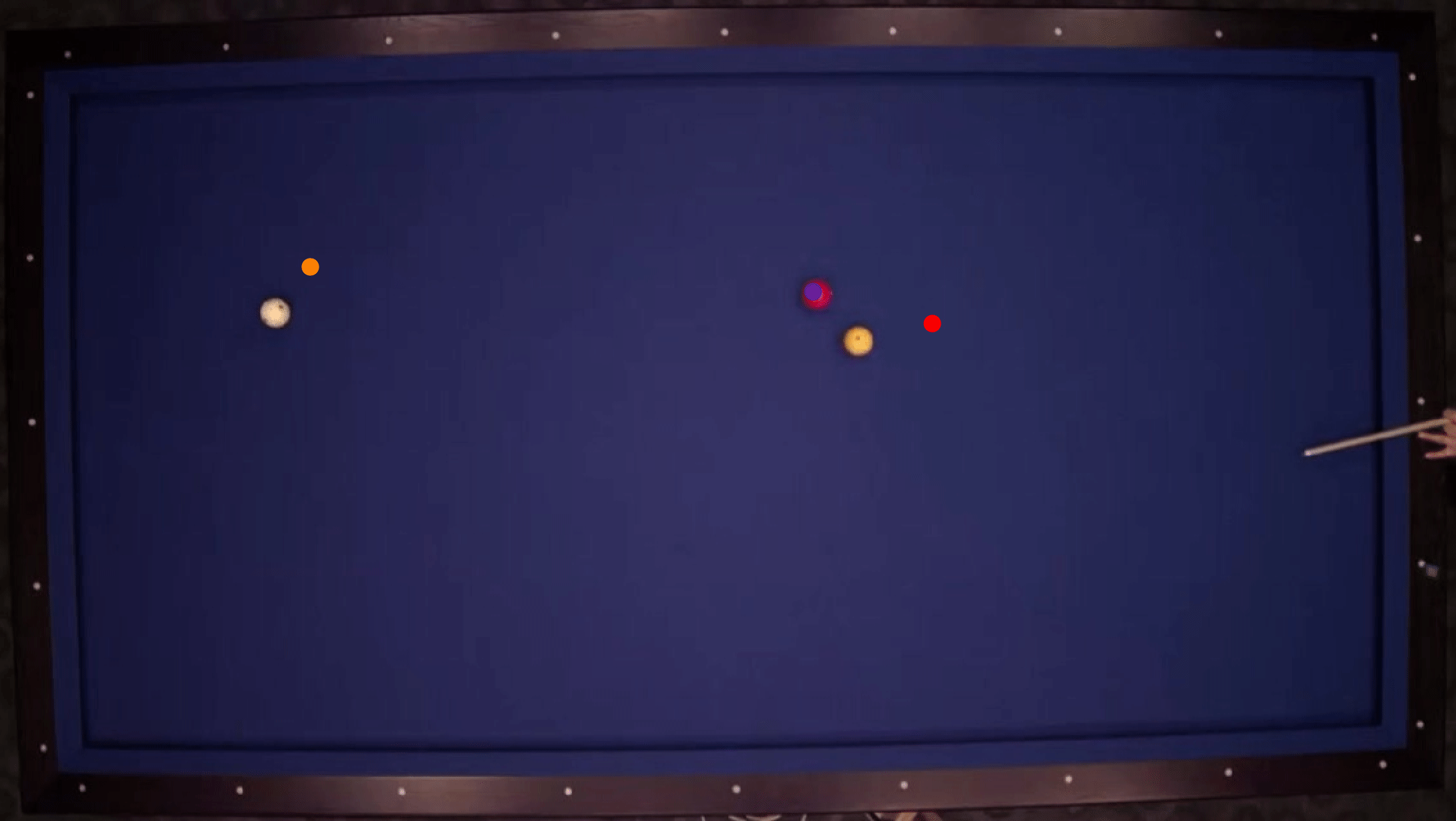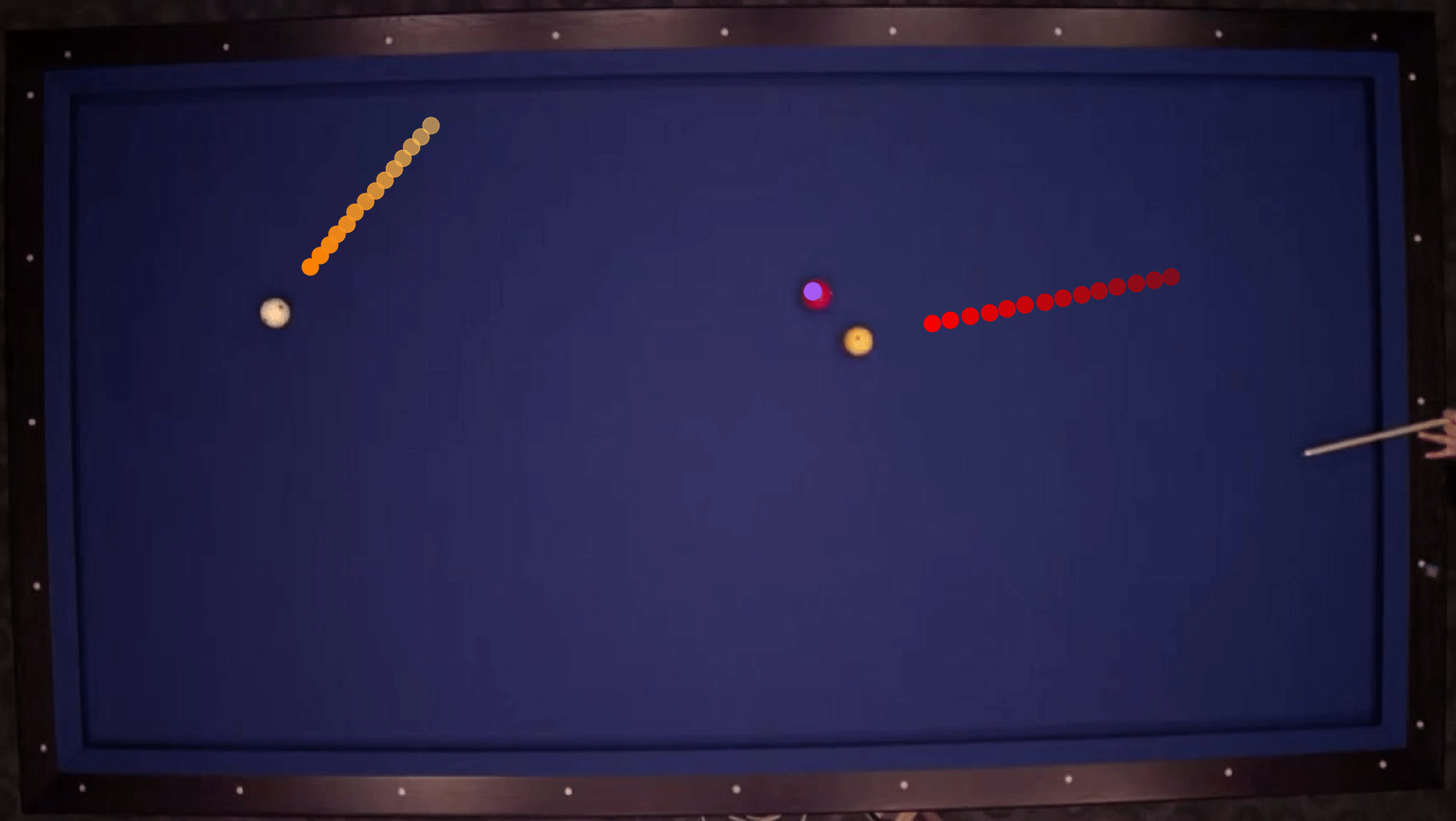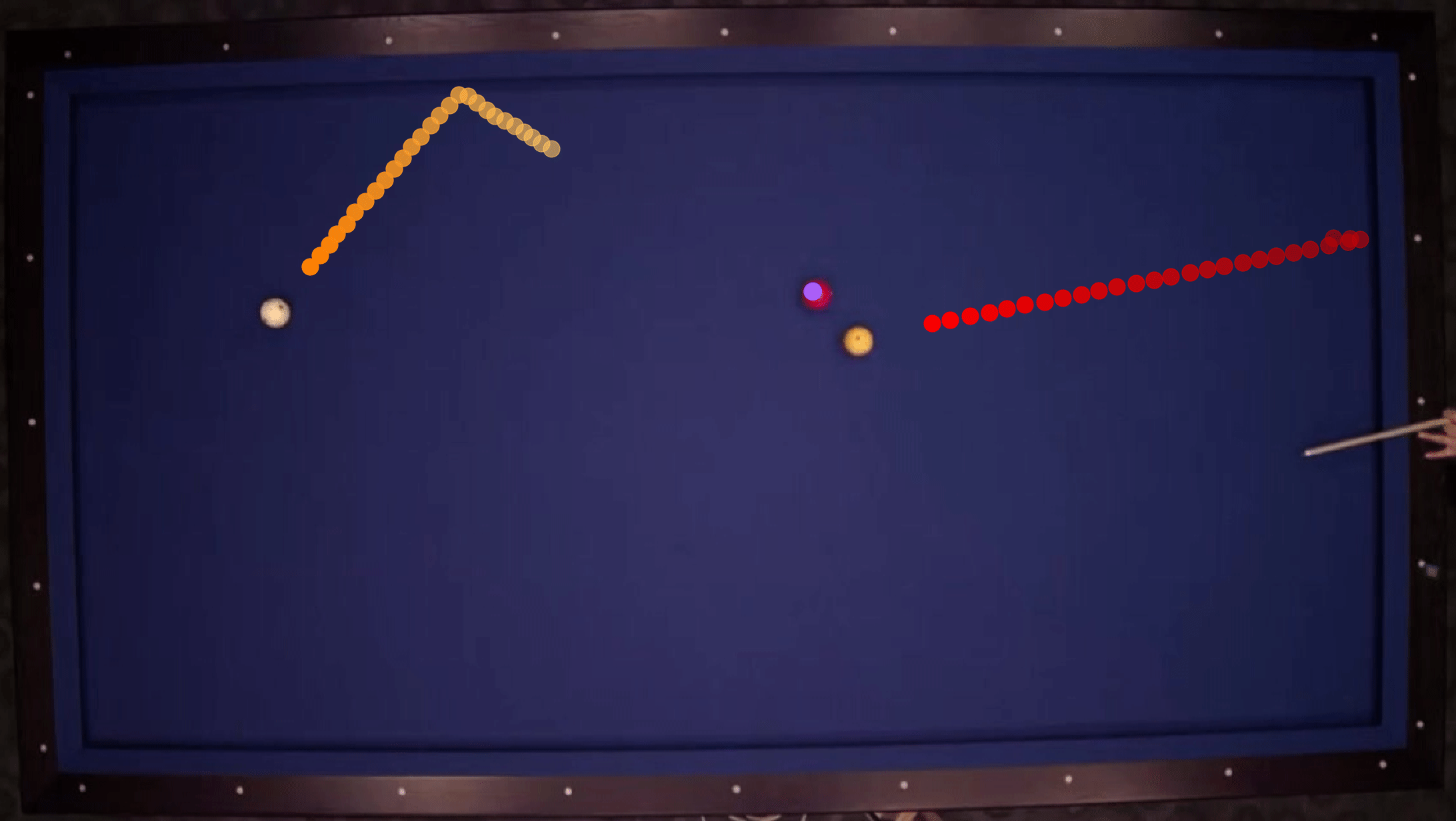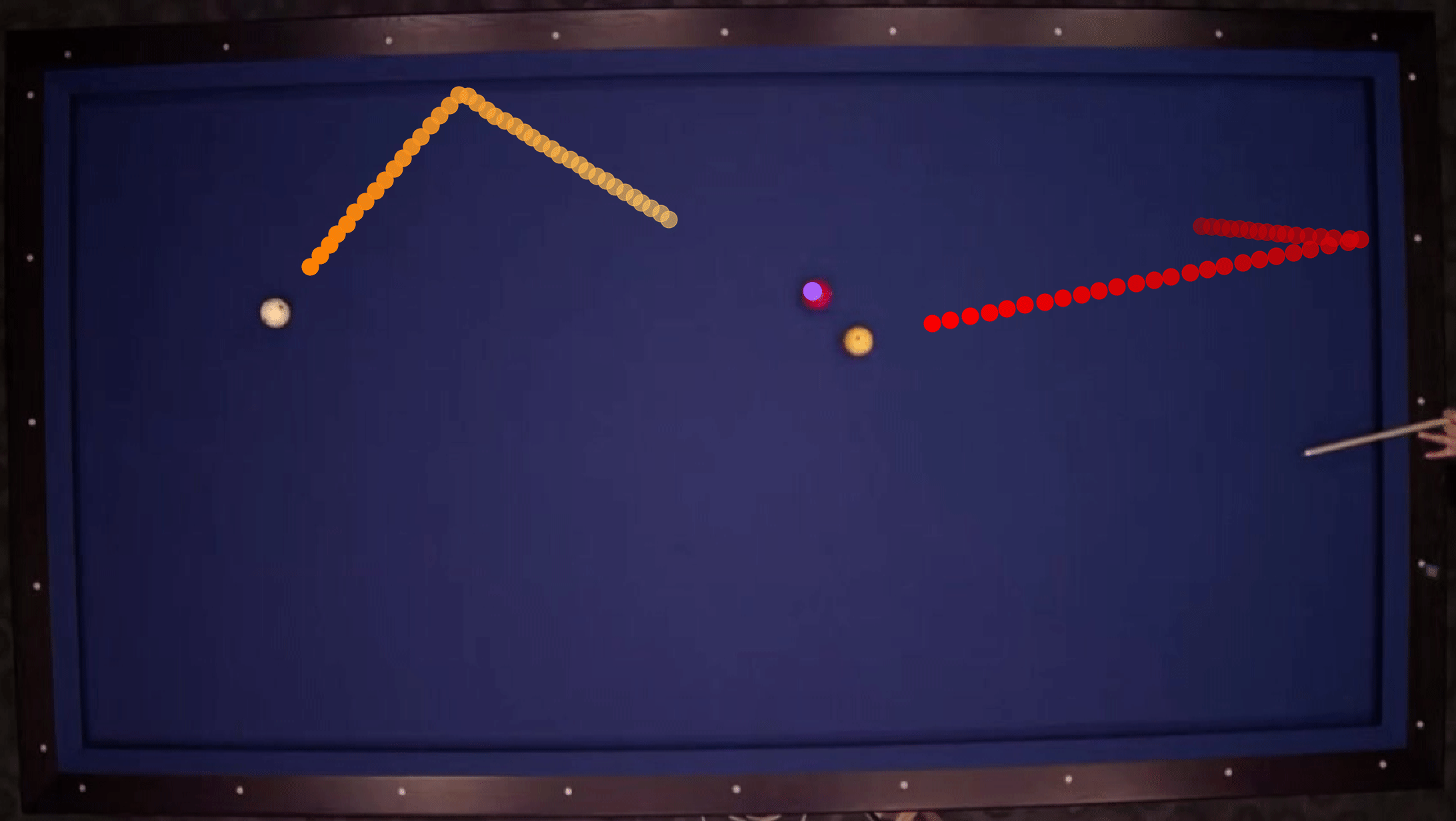
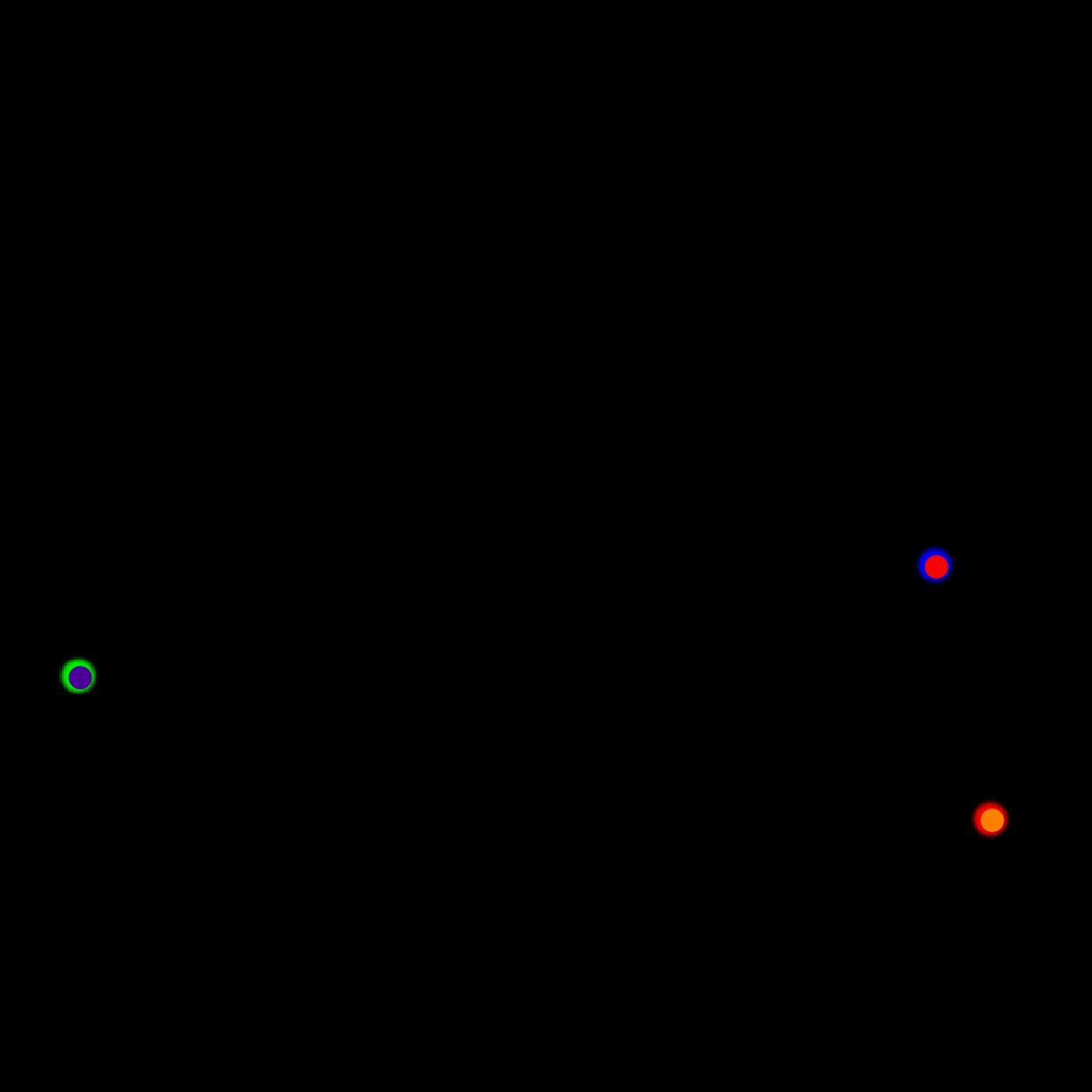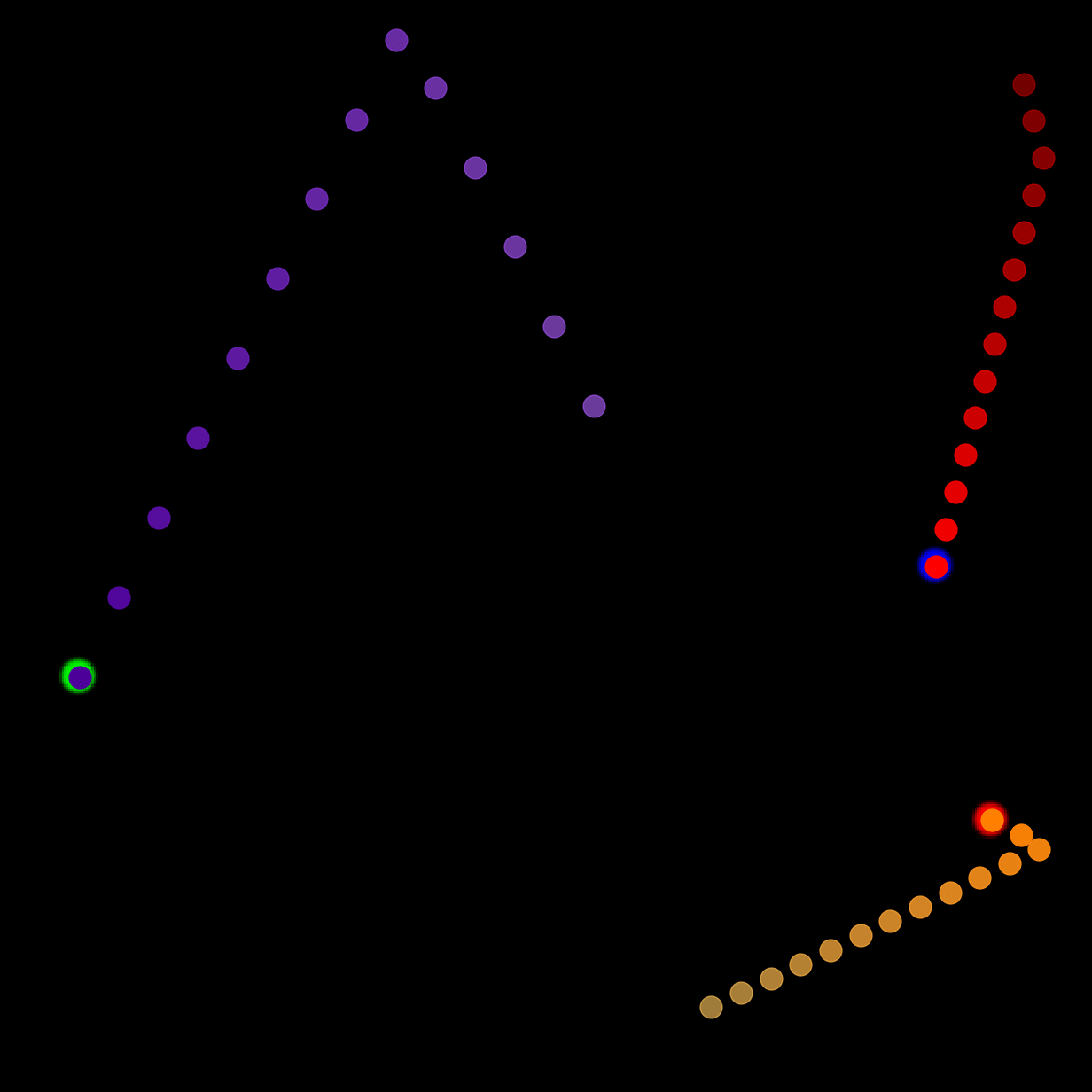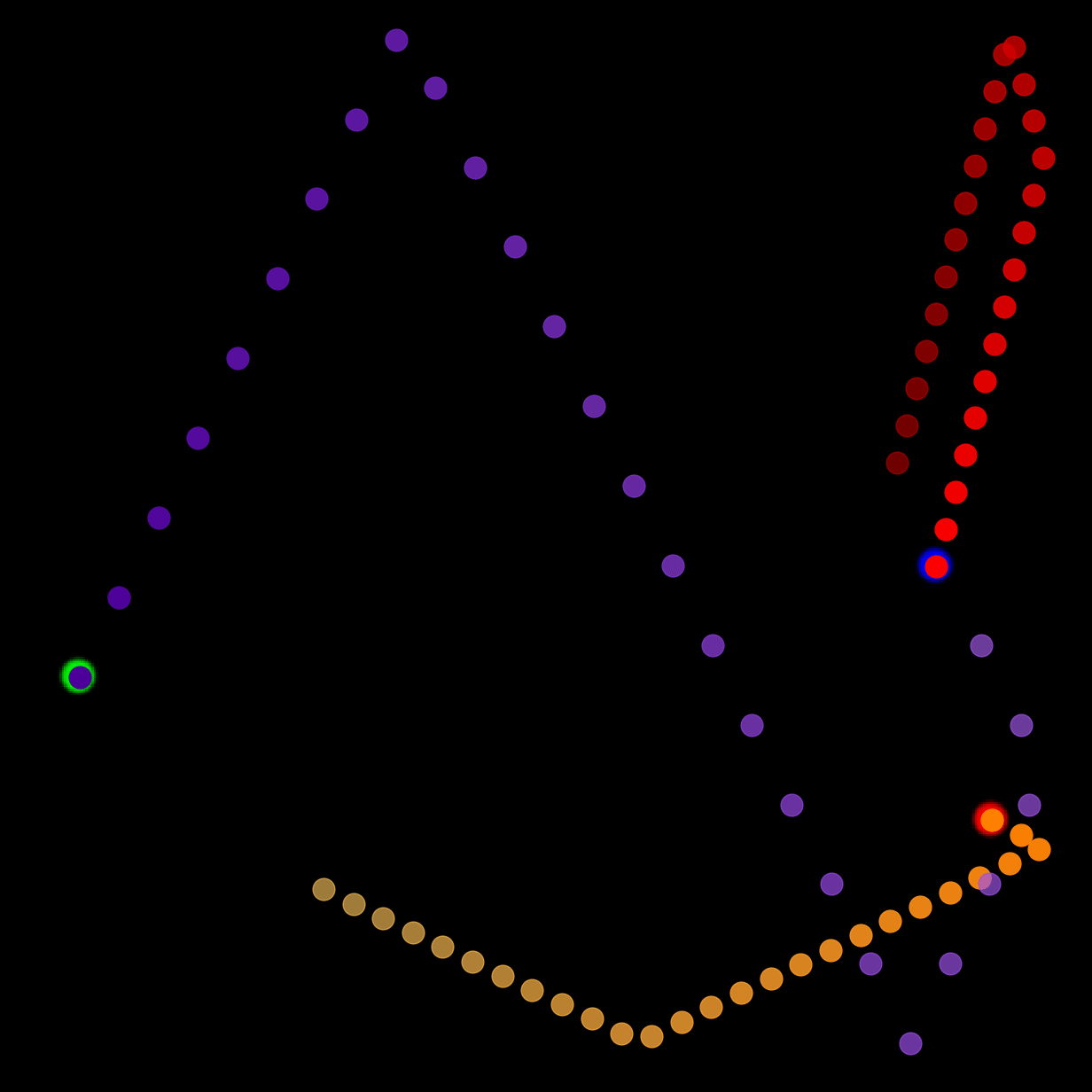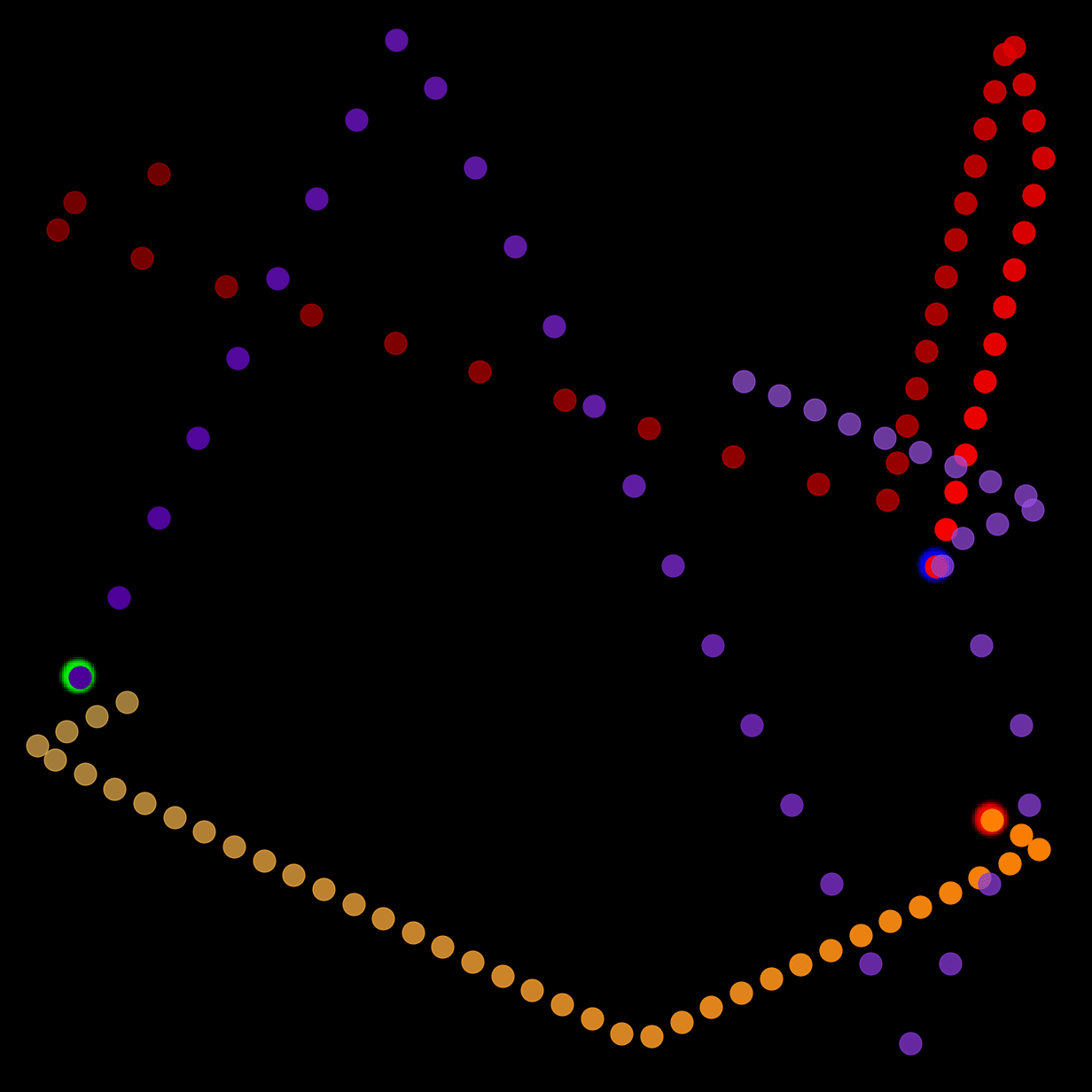
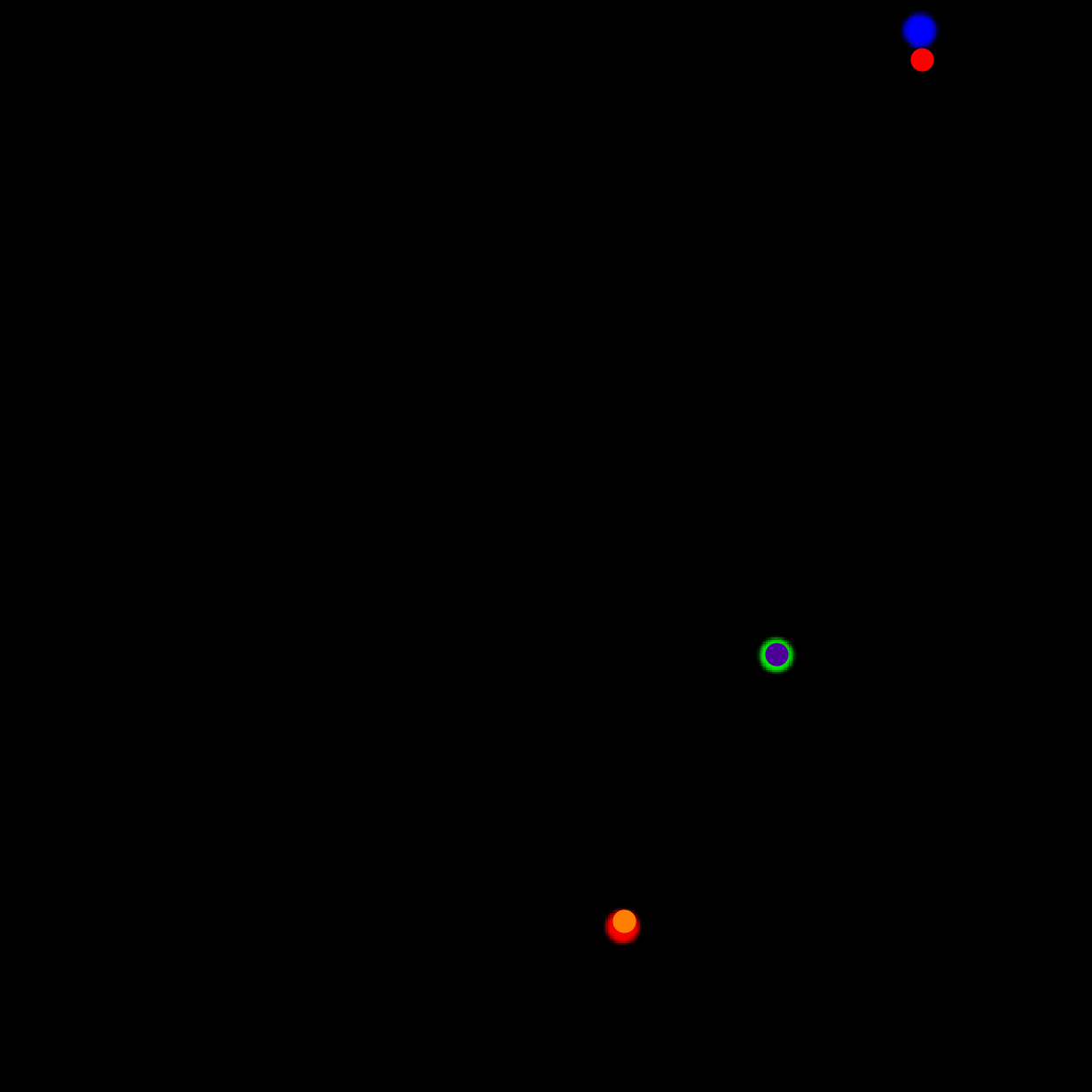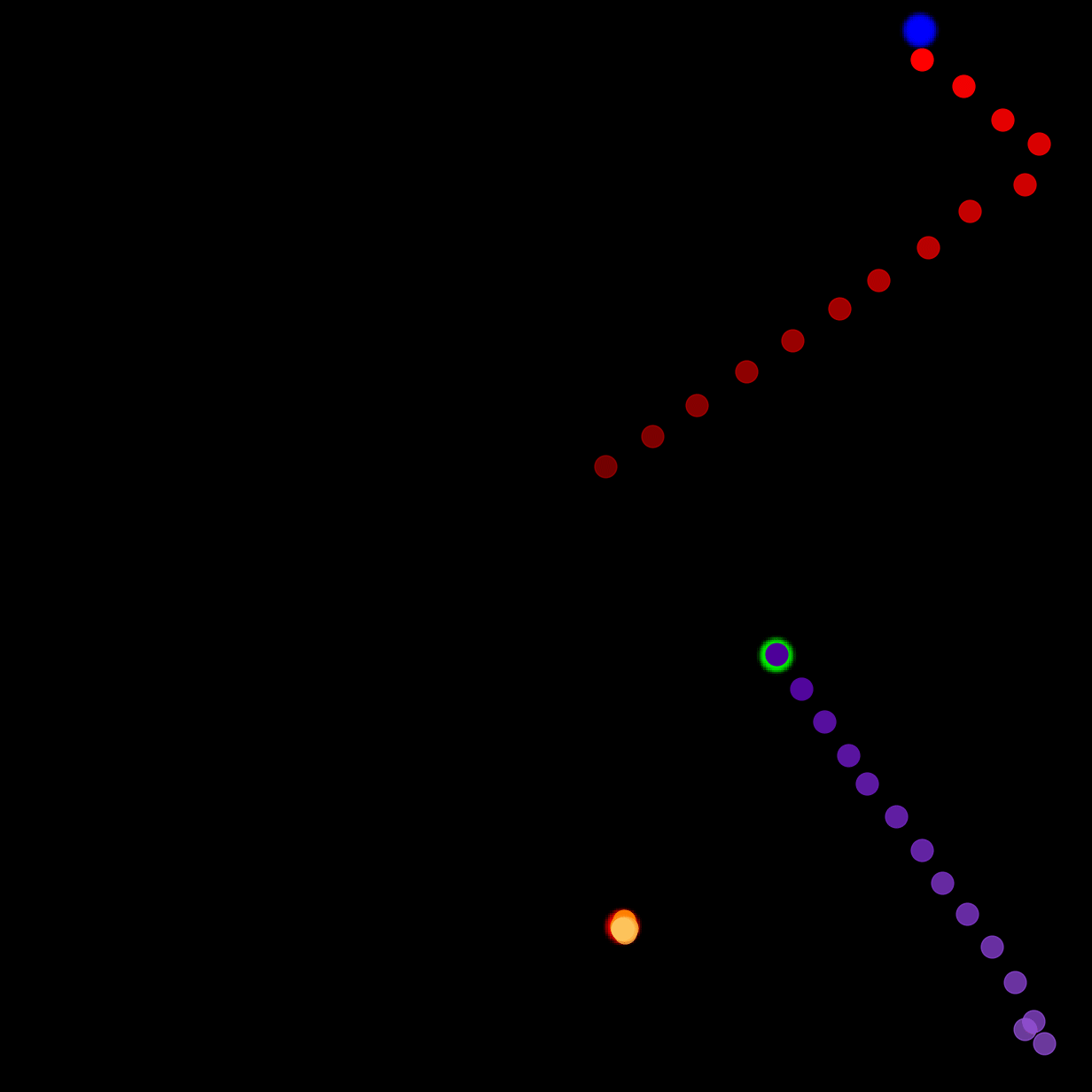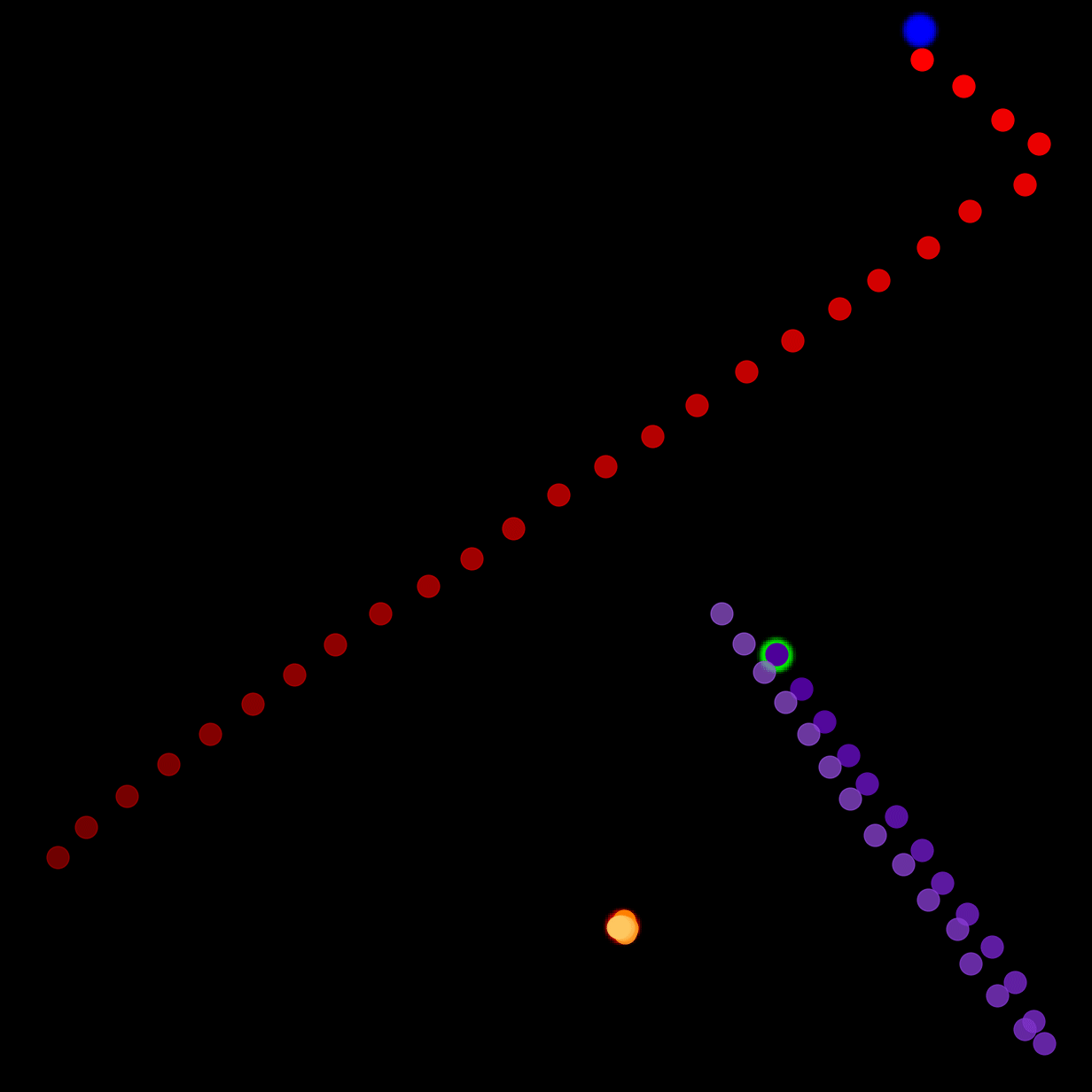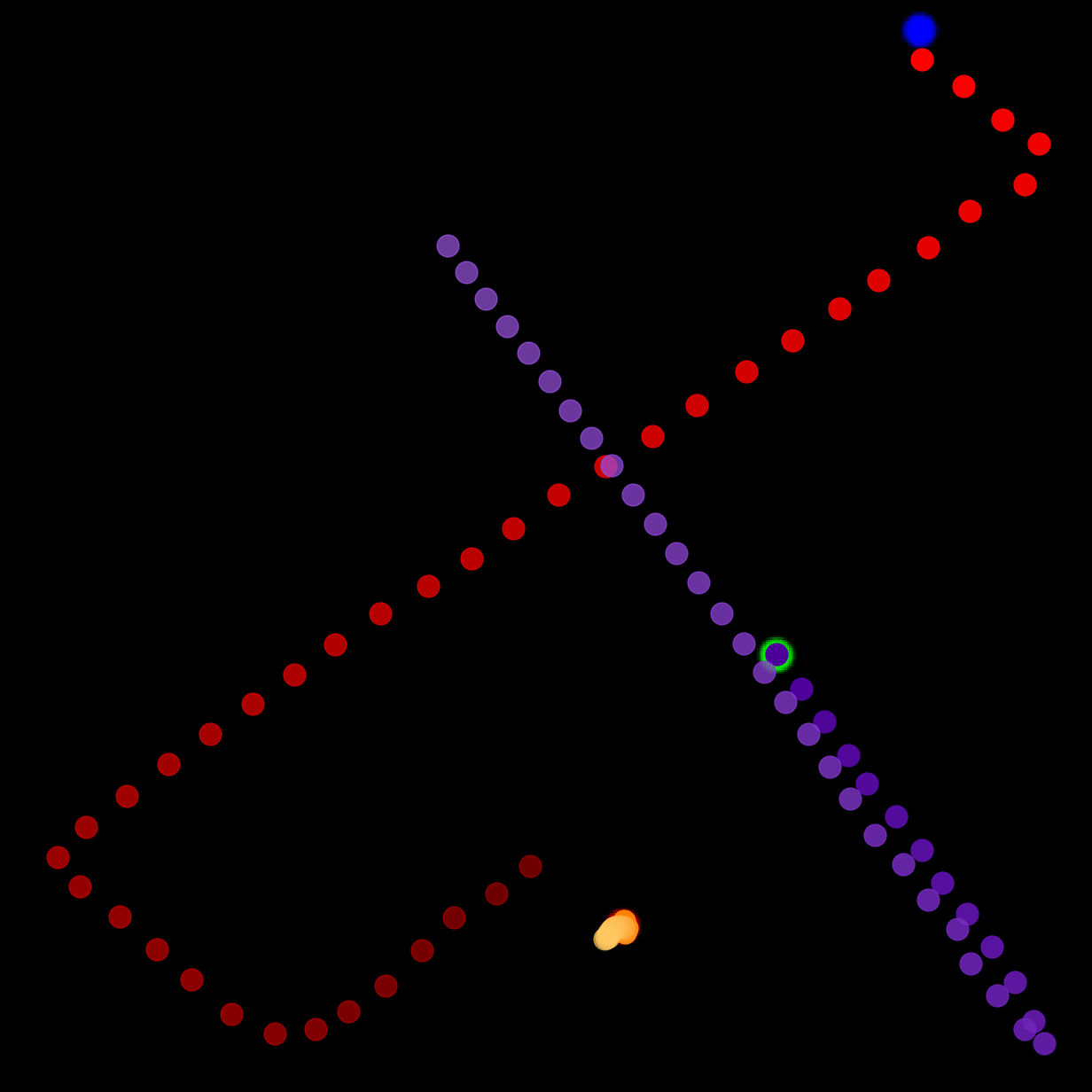
We show our prediction results and baseline prediction results on the test set of PHYRE (within-task generalization, fold 0). Given the first image and the objects' bounding boxes, we predict the future bounding boxes and masks for each moving objects. The backgrounds (colored purple and black) and the color of the objects are taken from the input image.


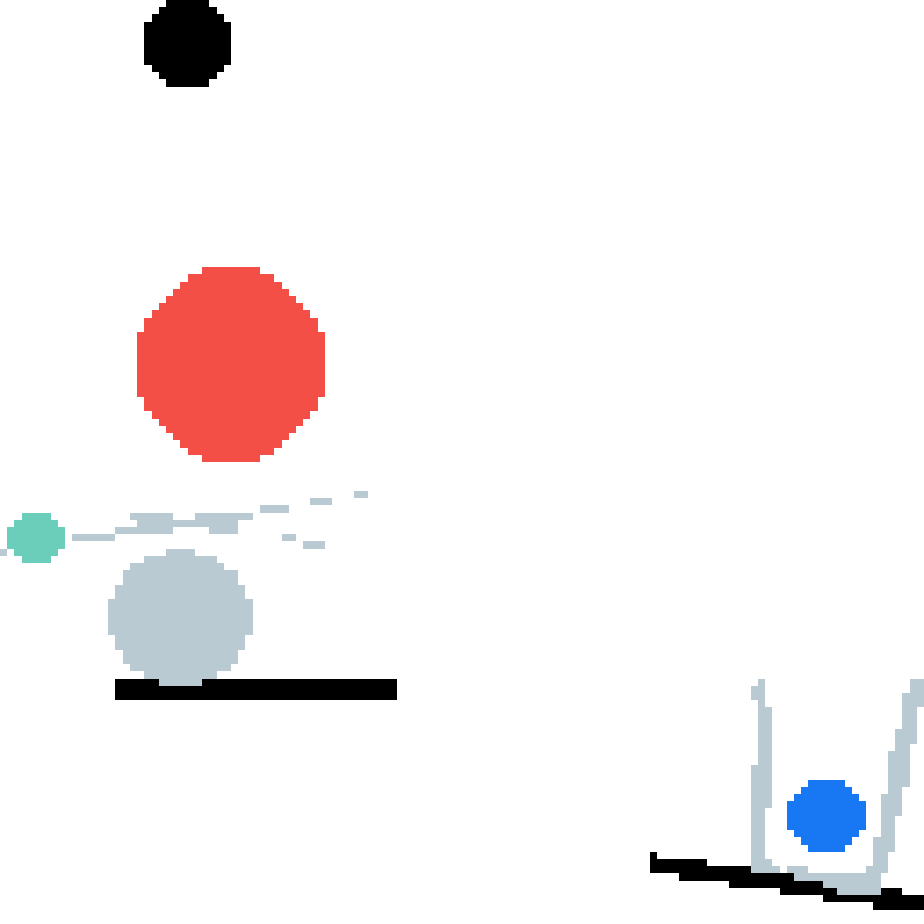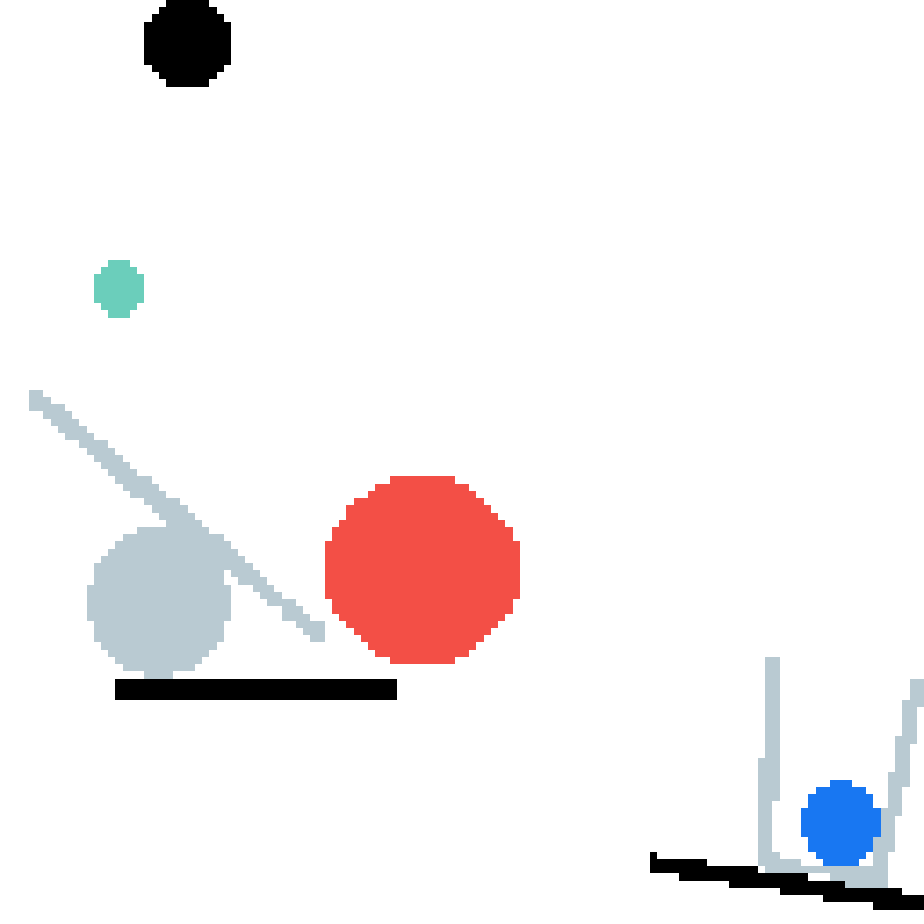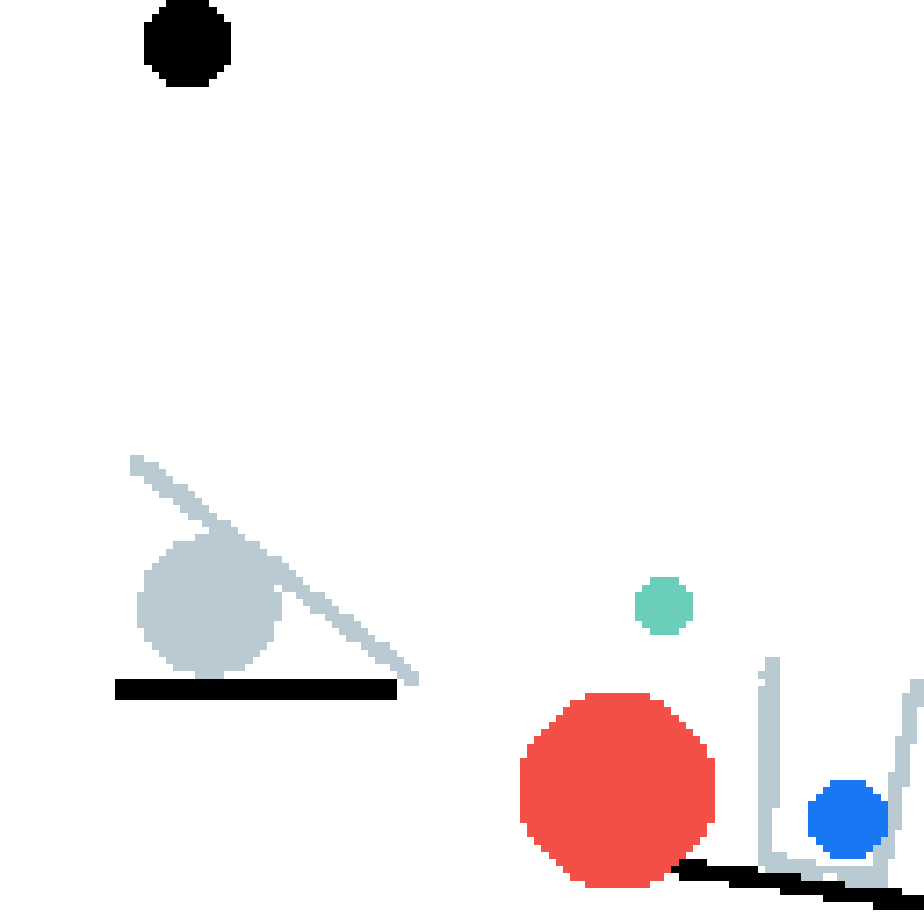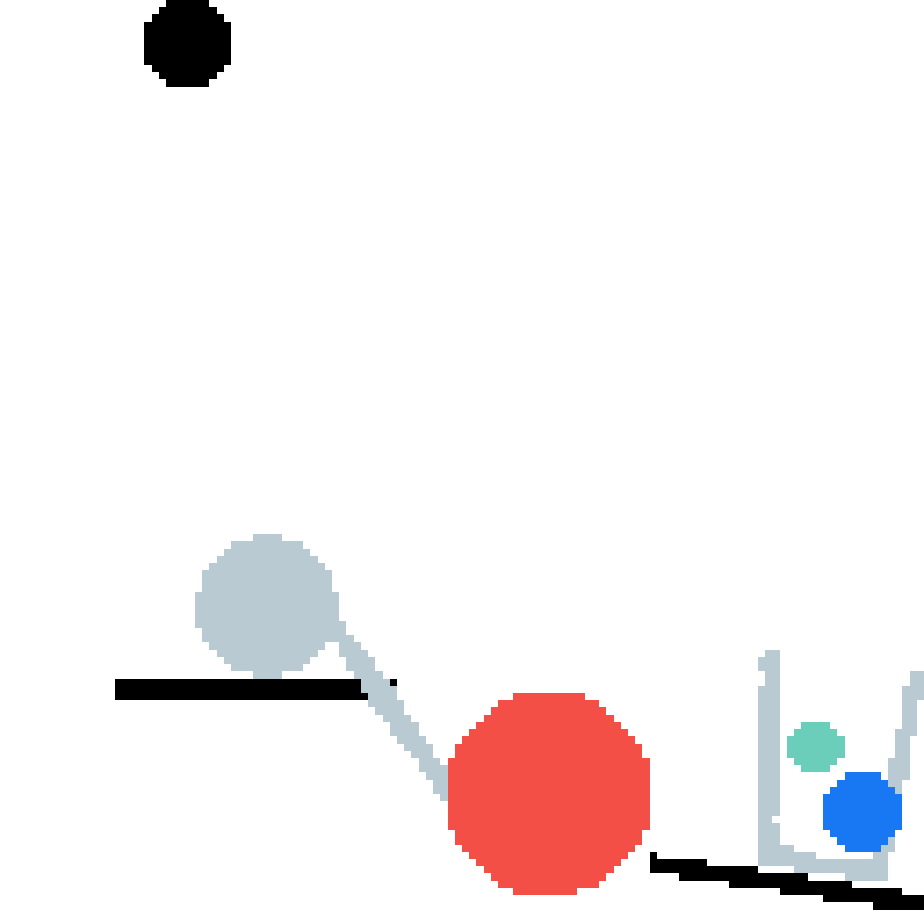

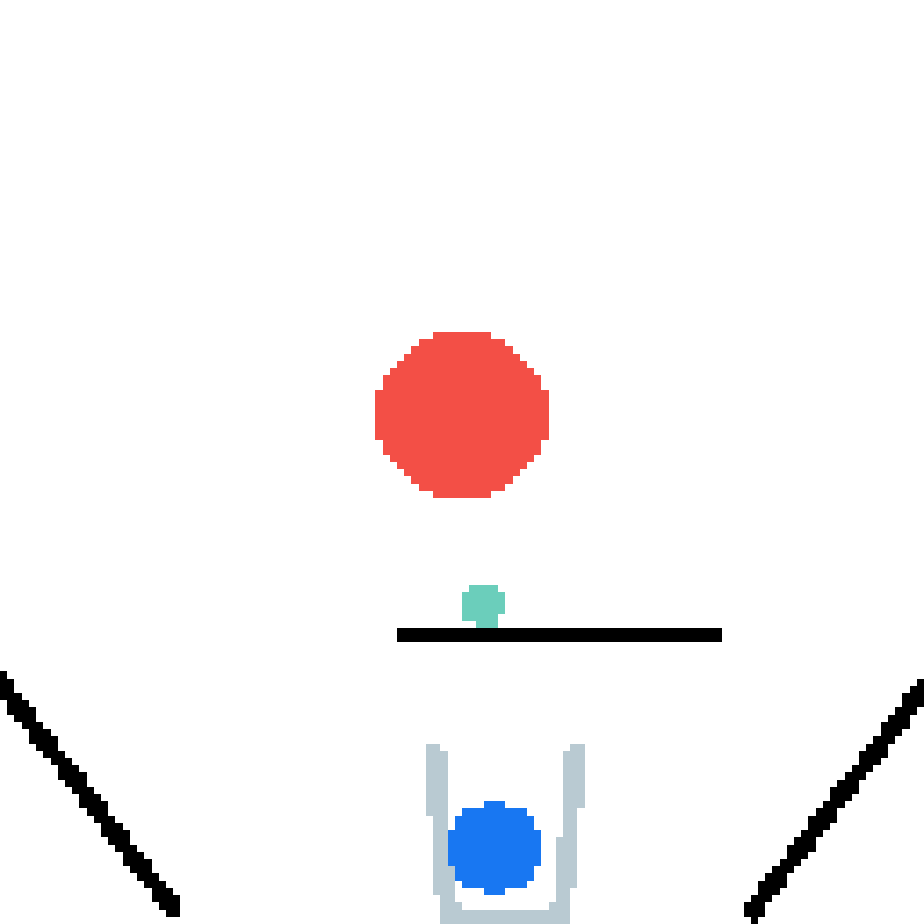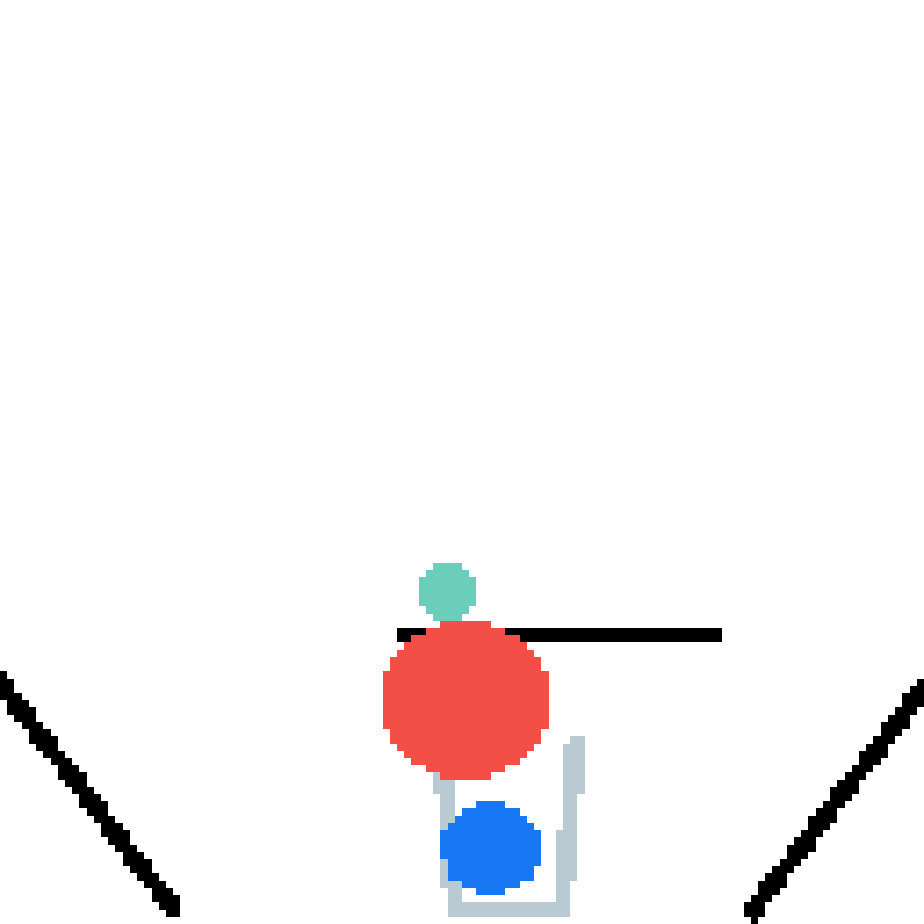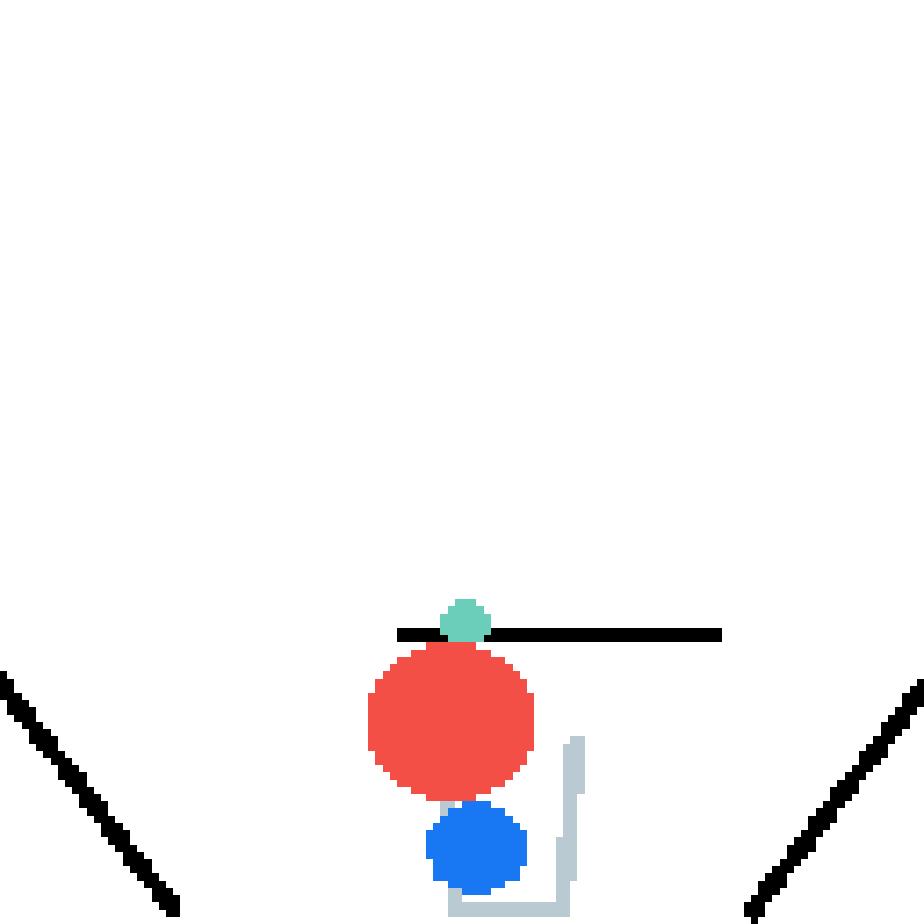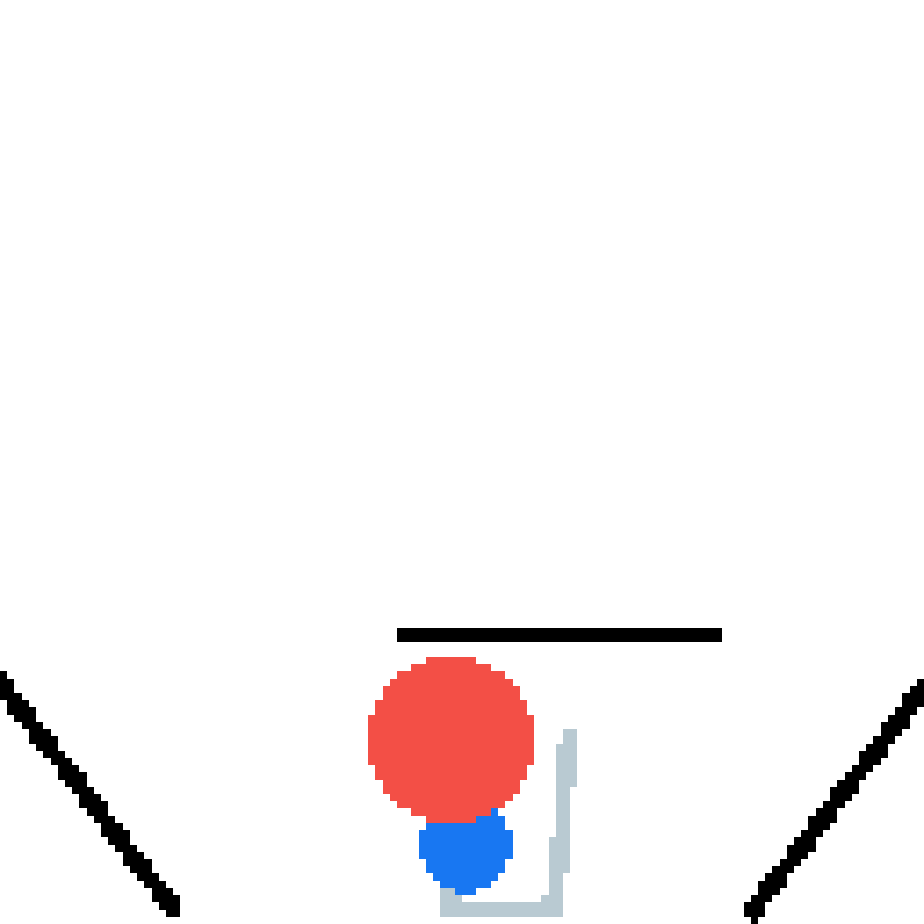
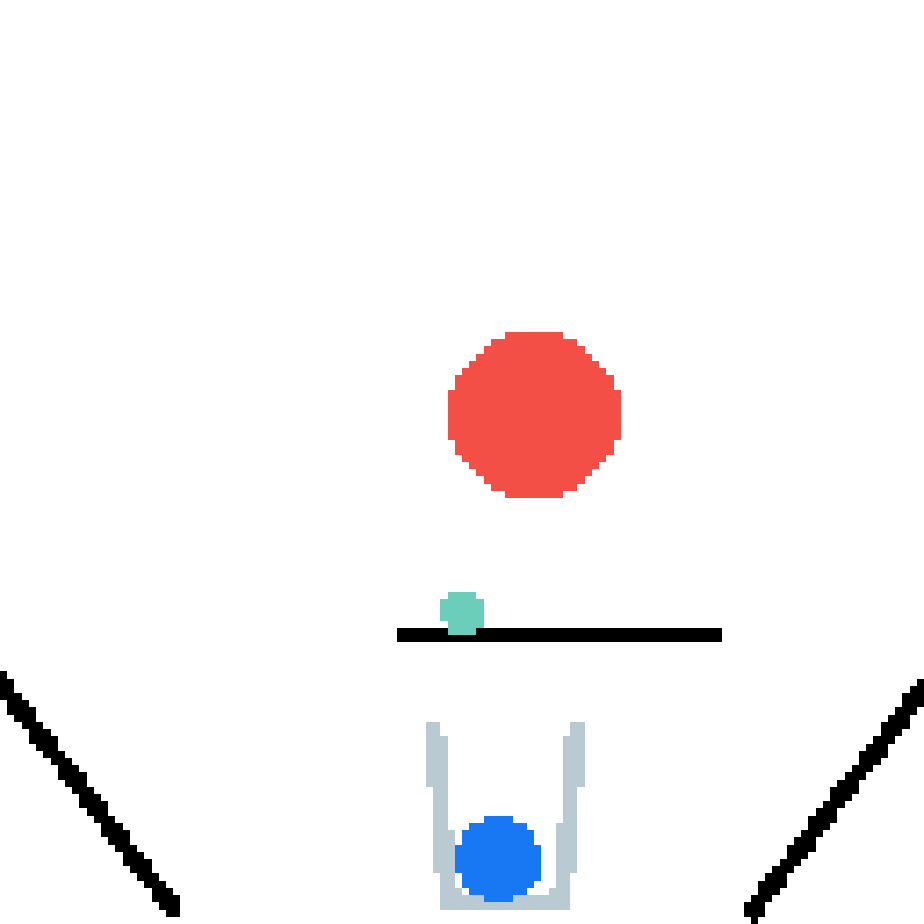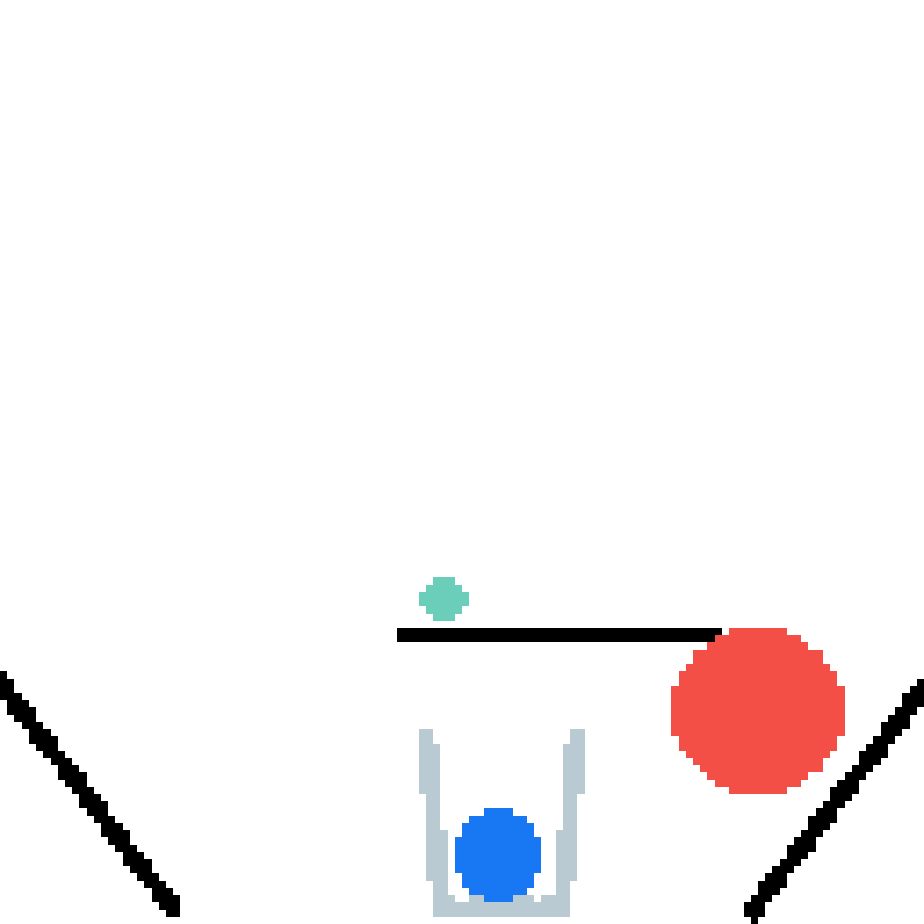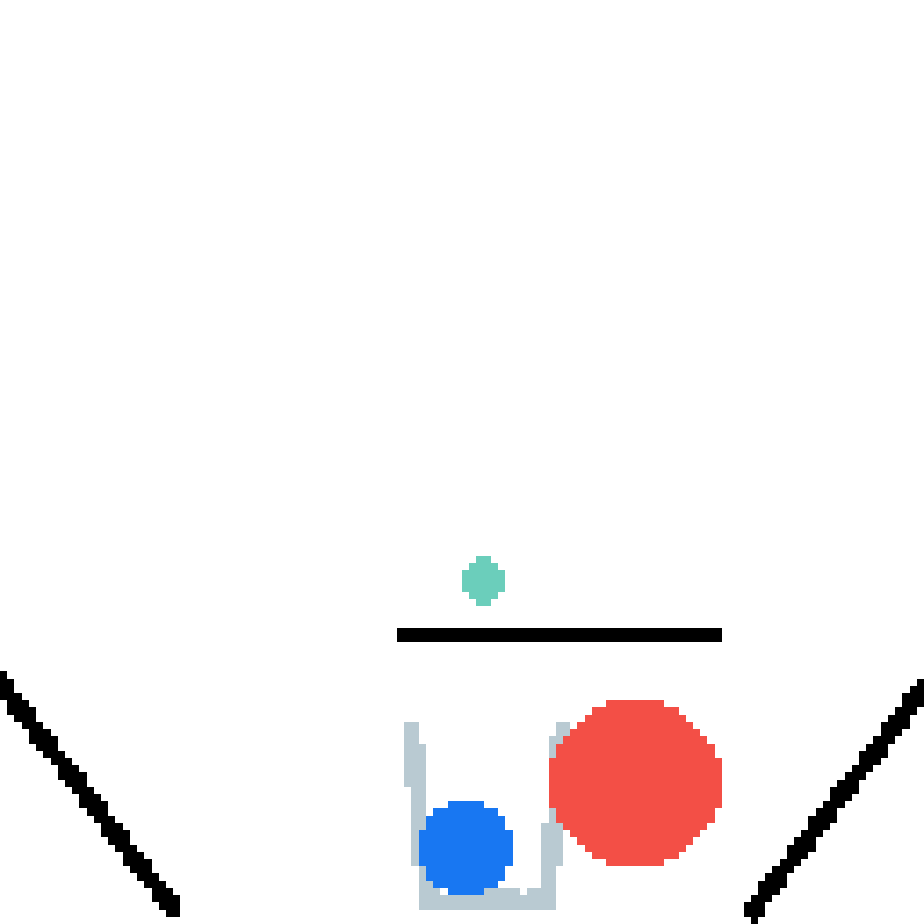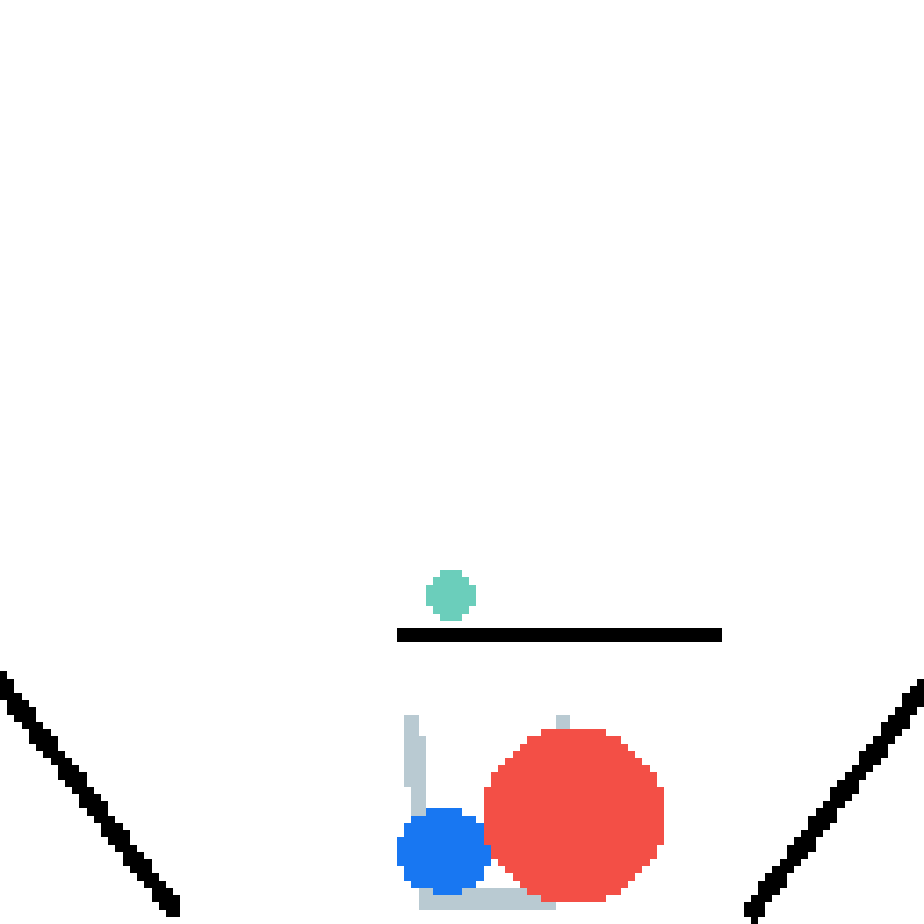
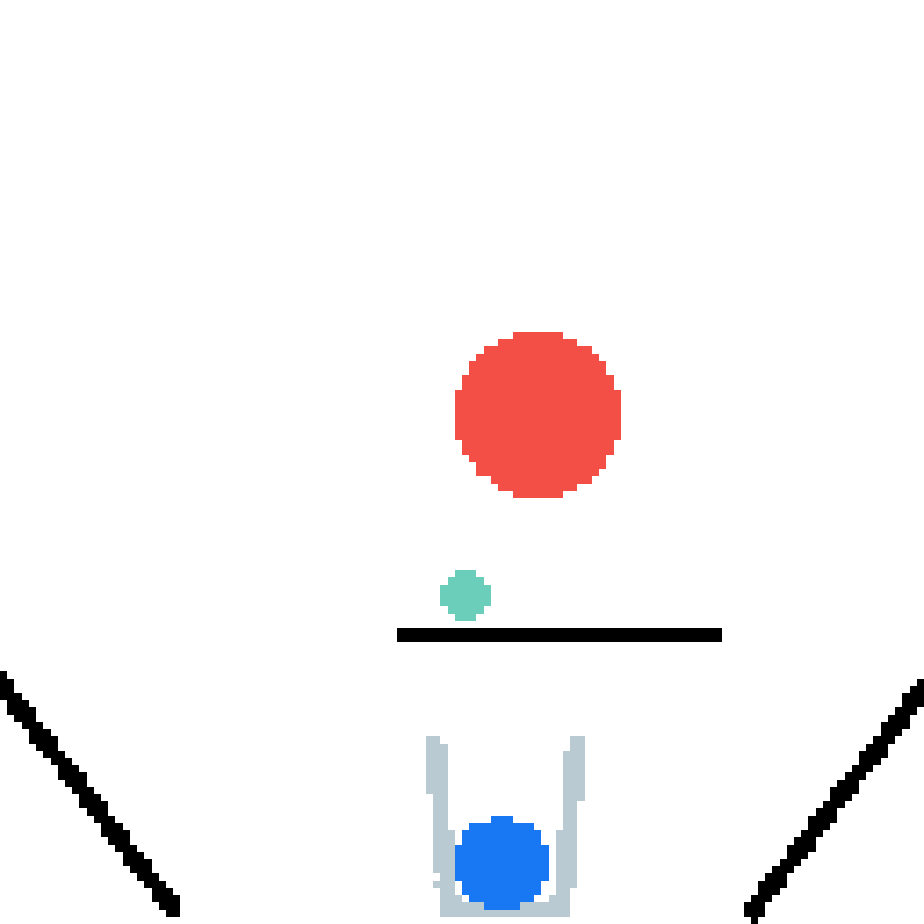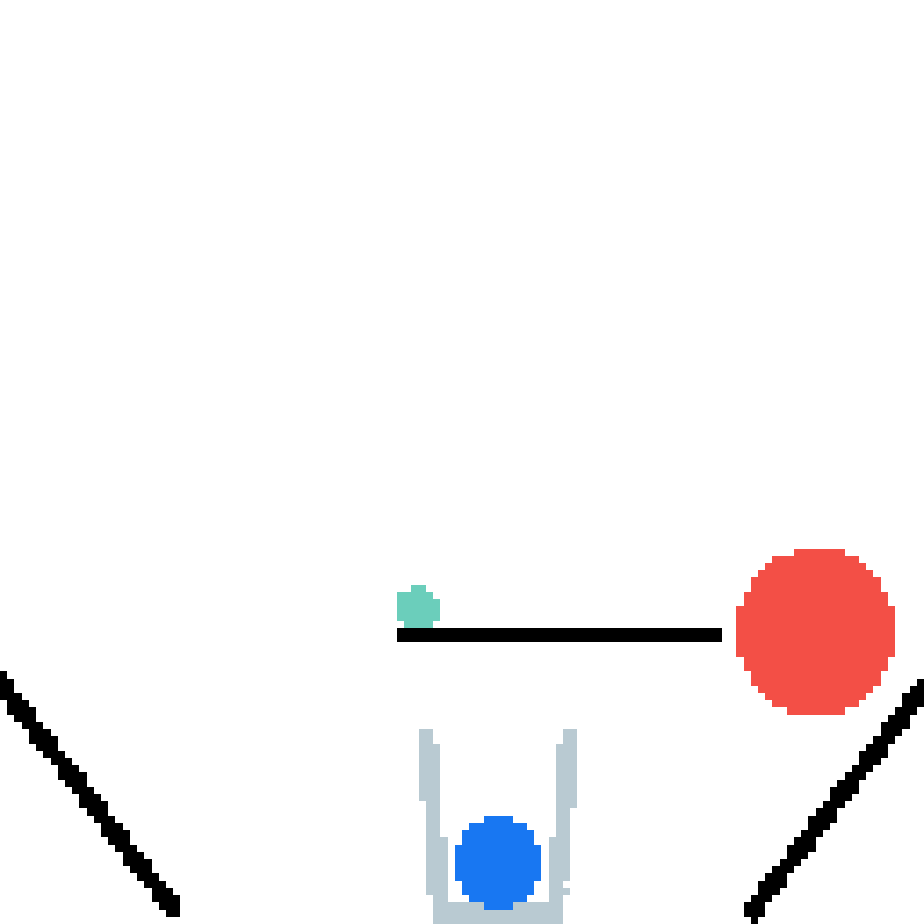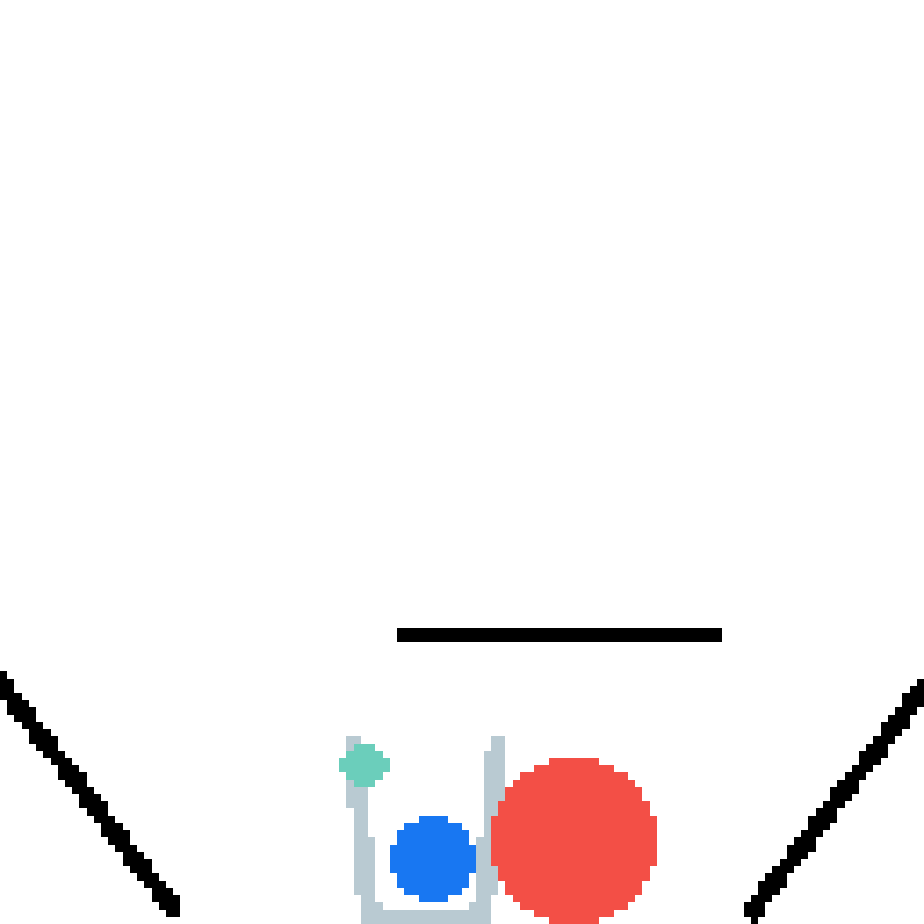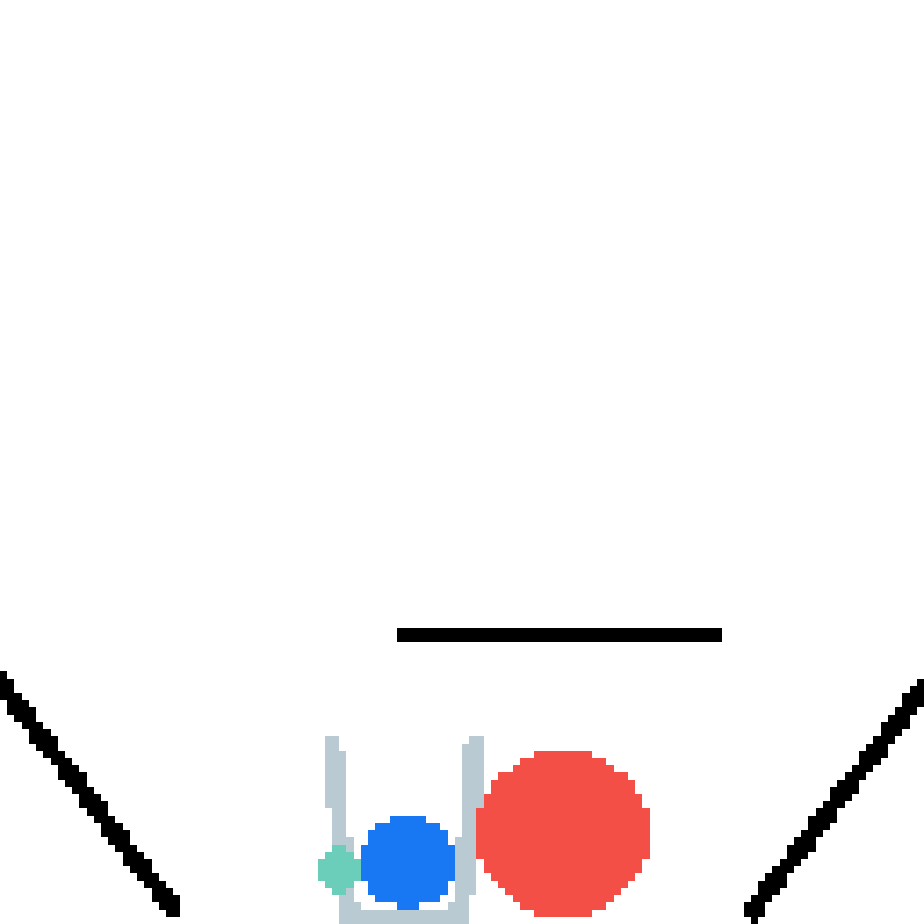
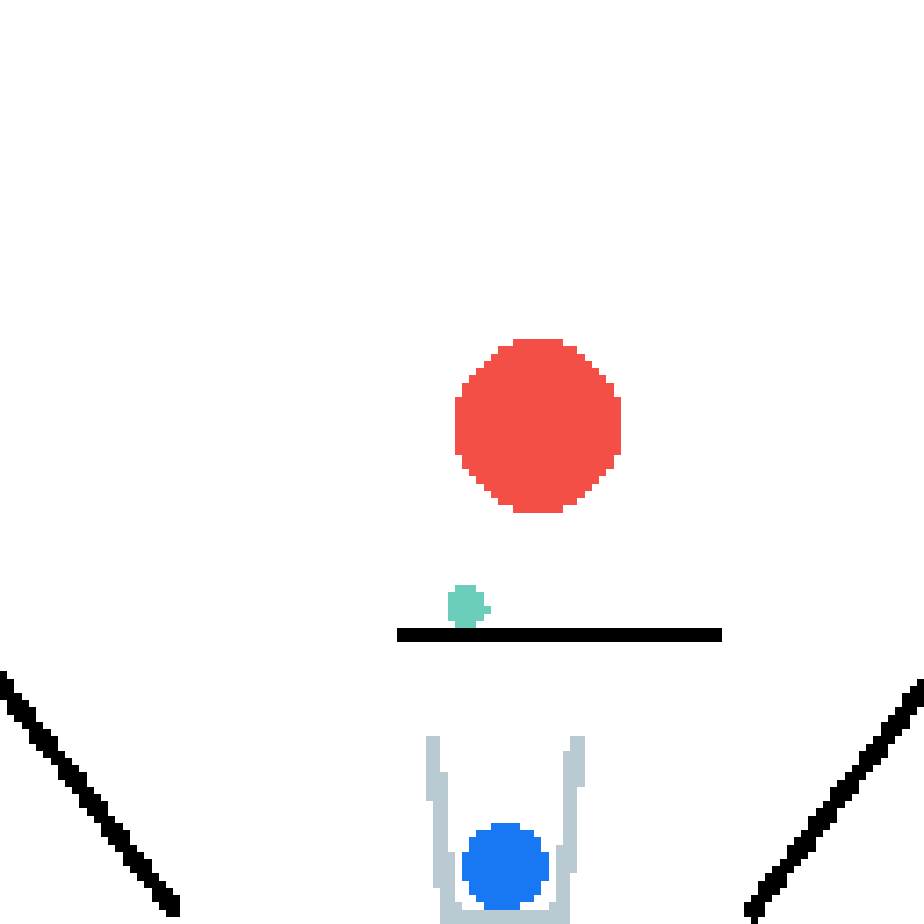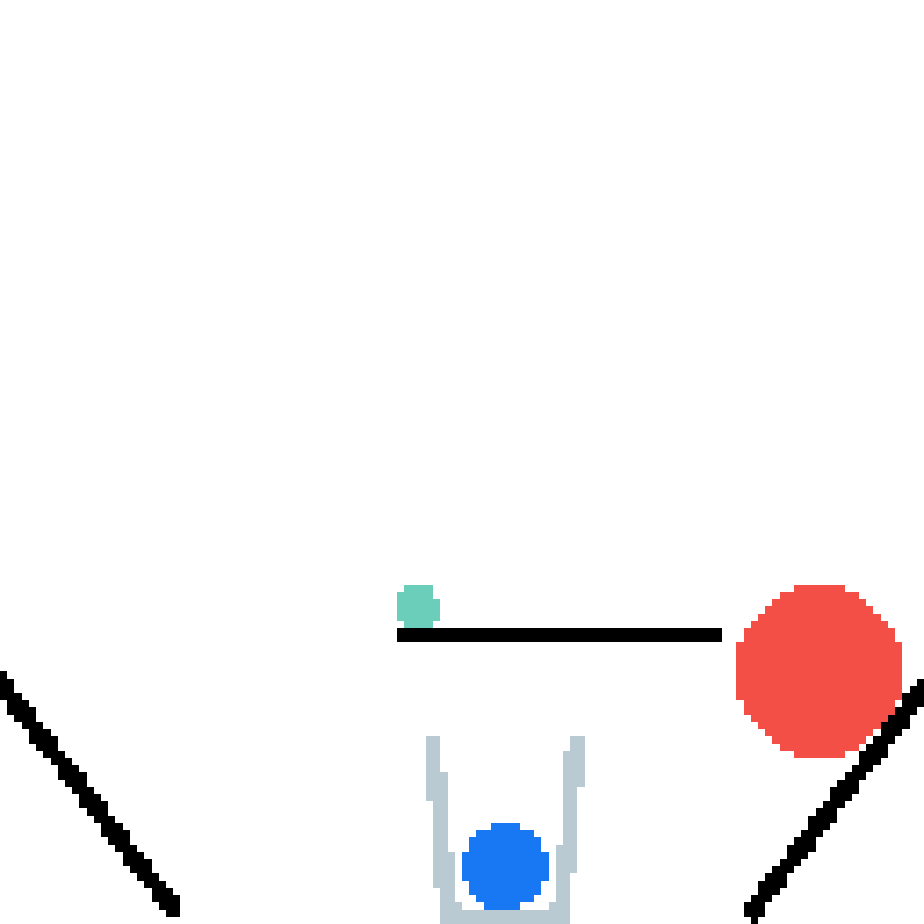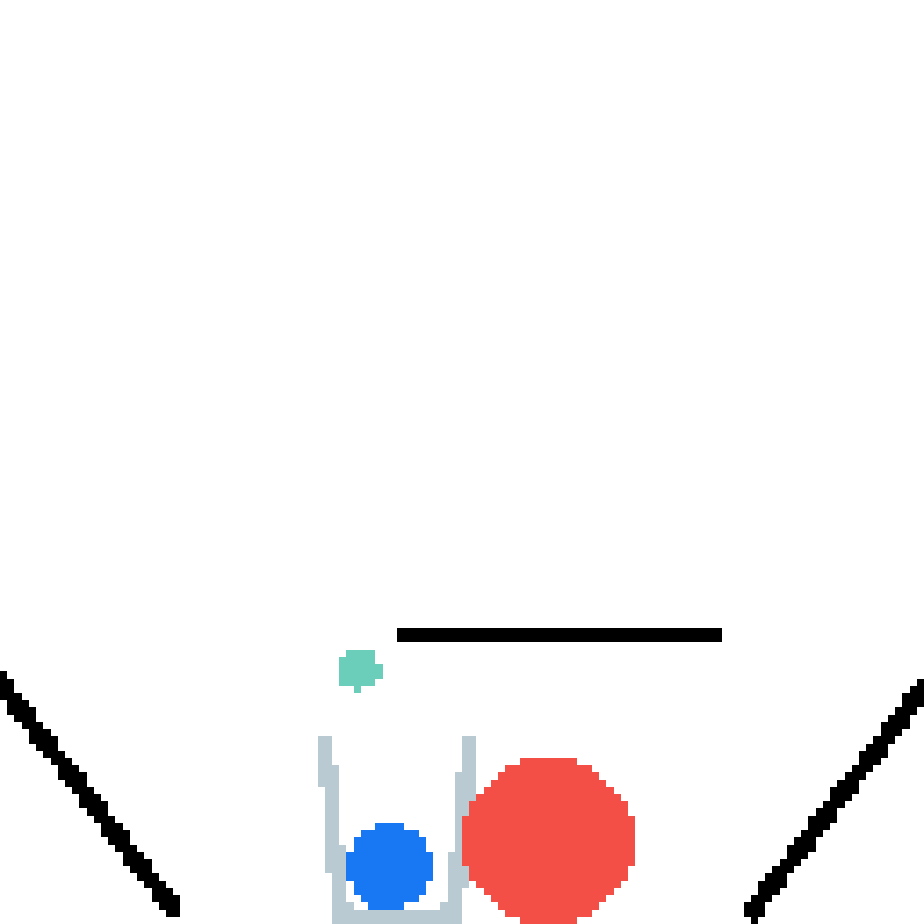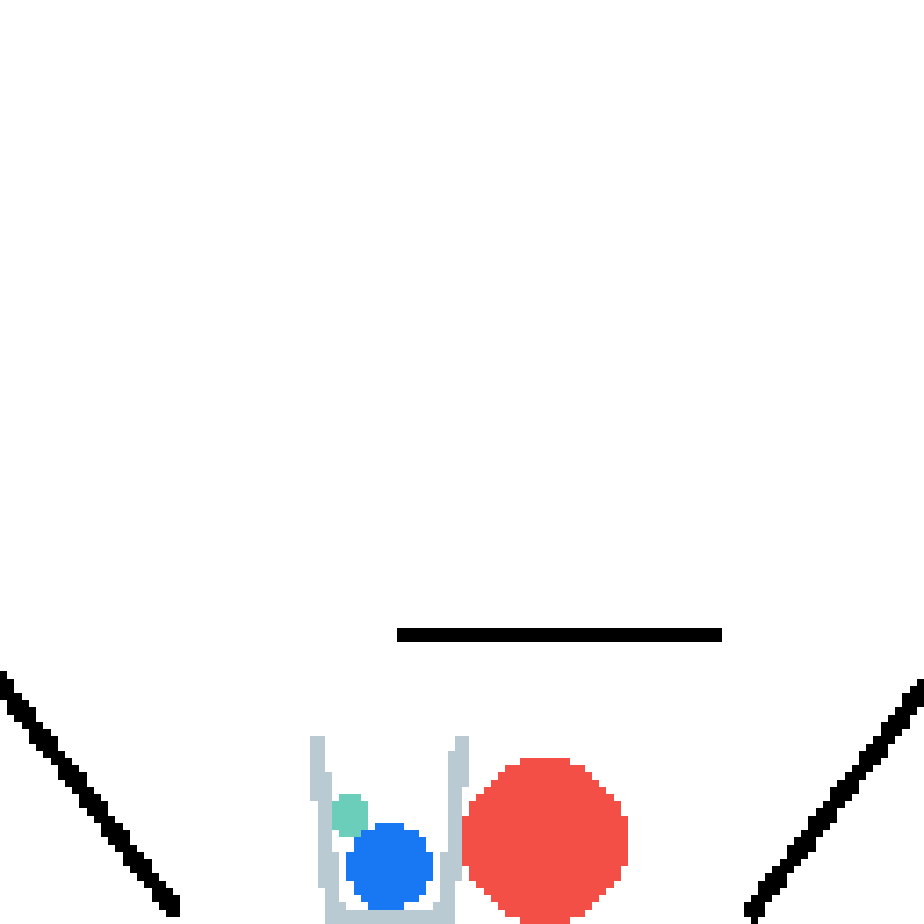
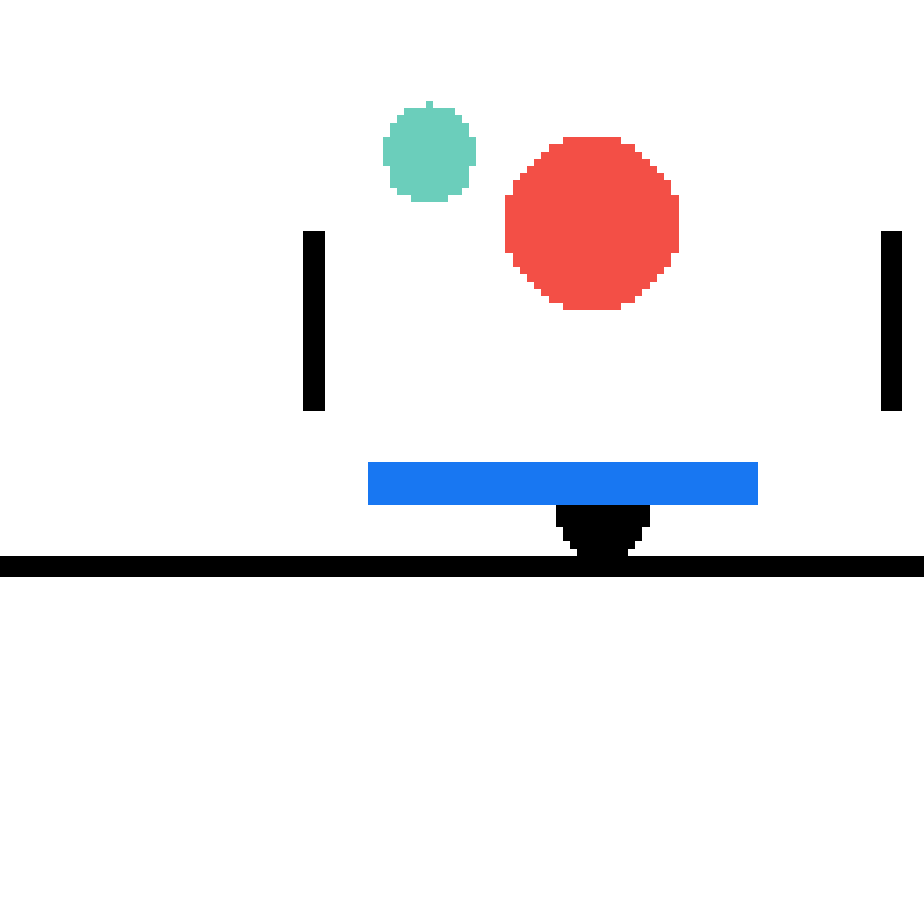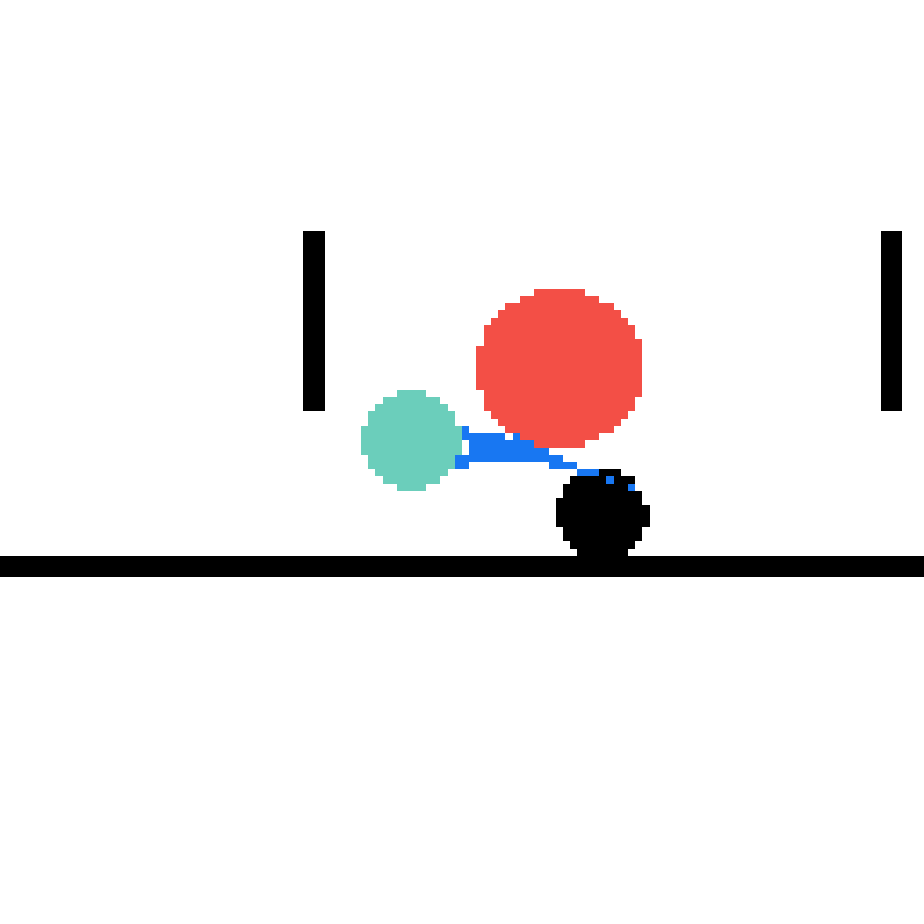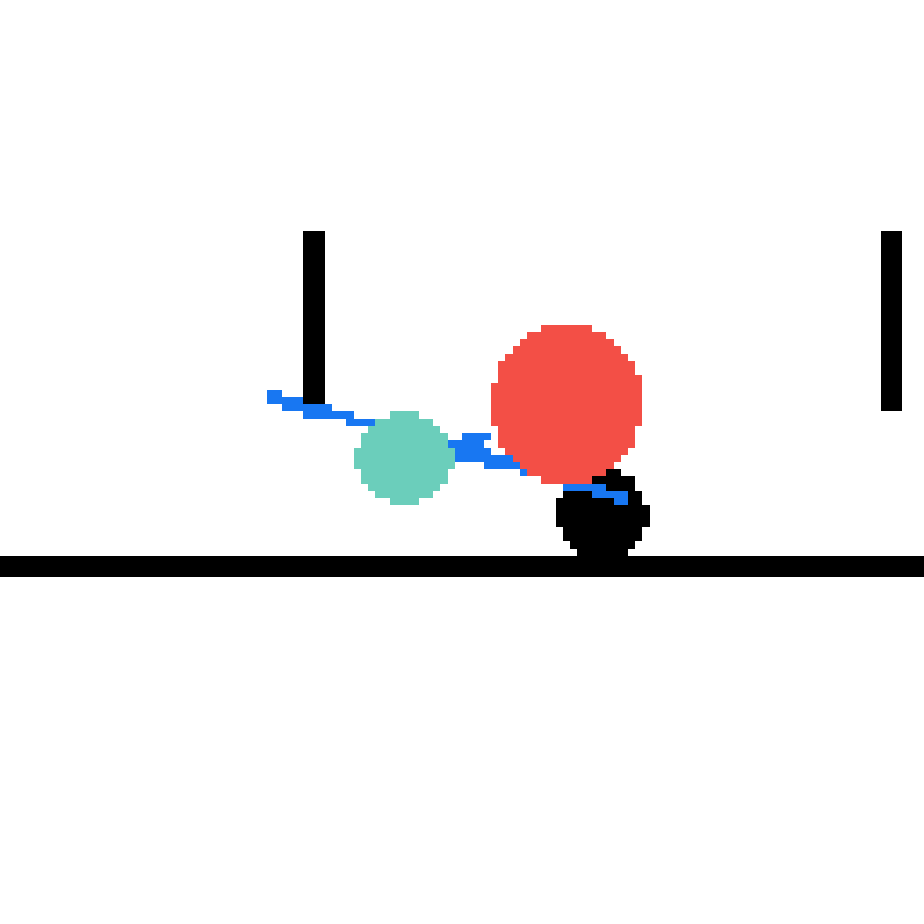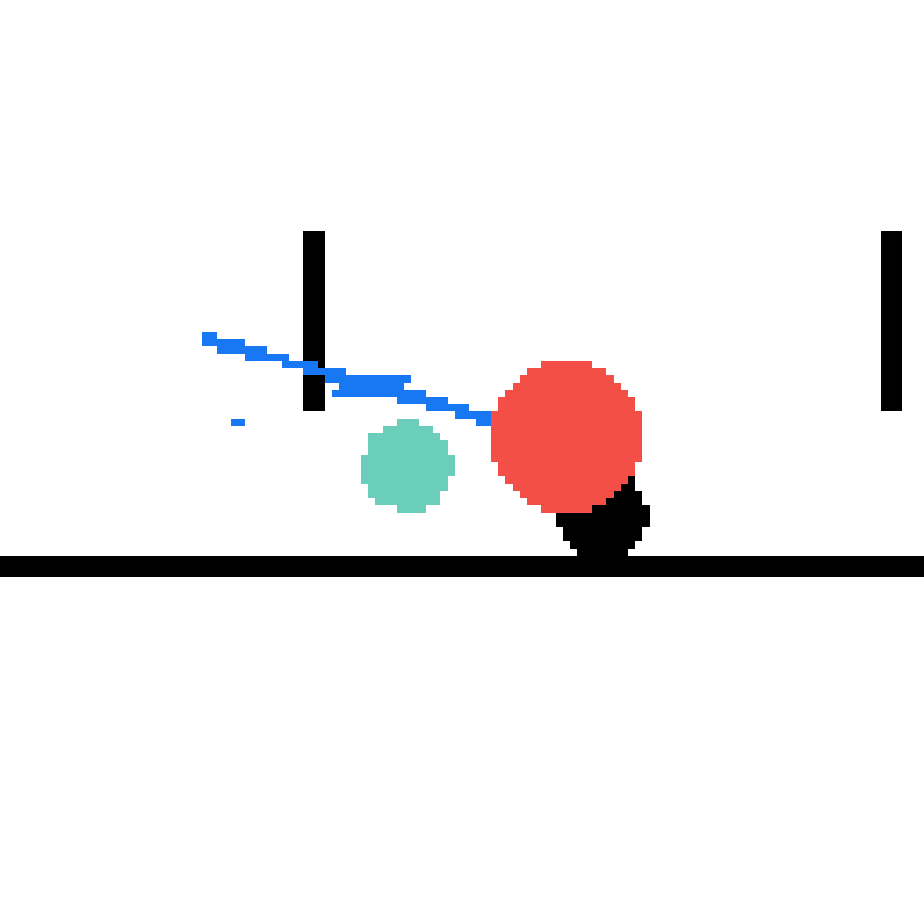
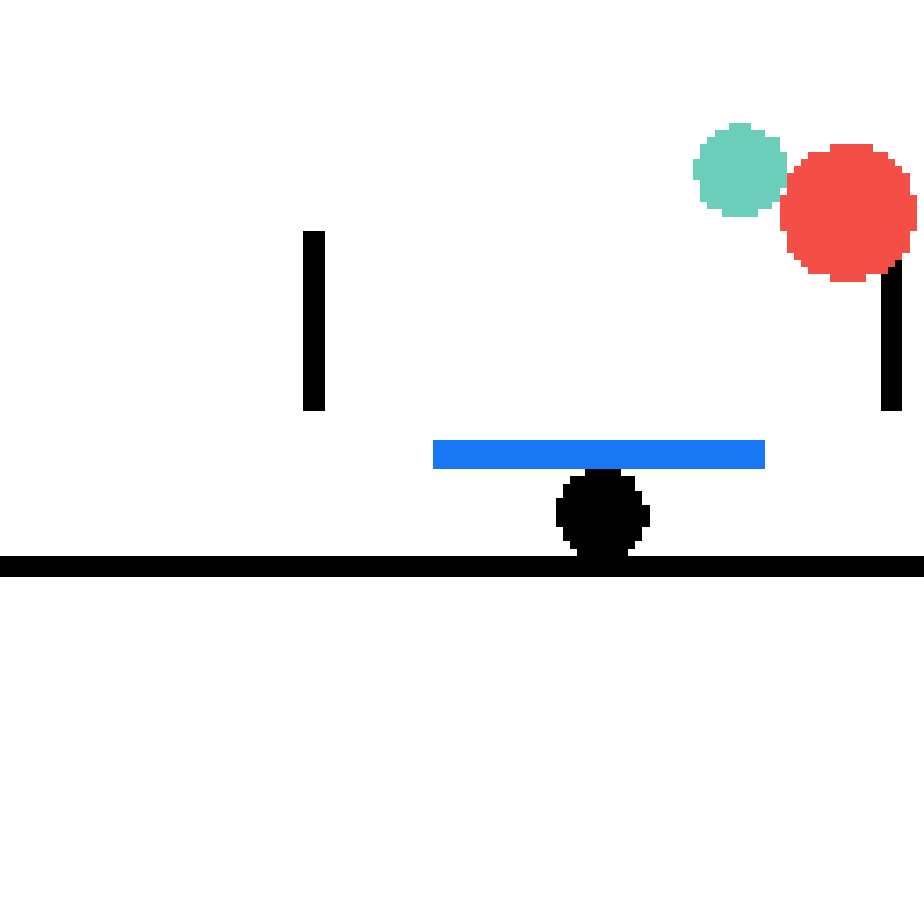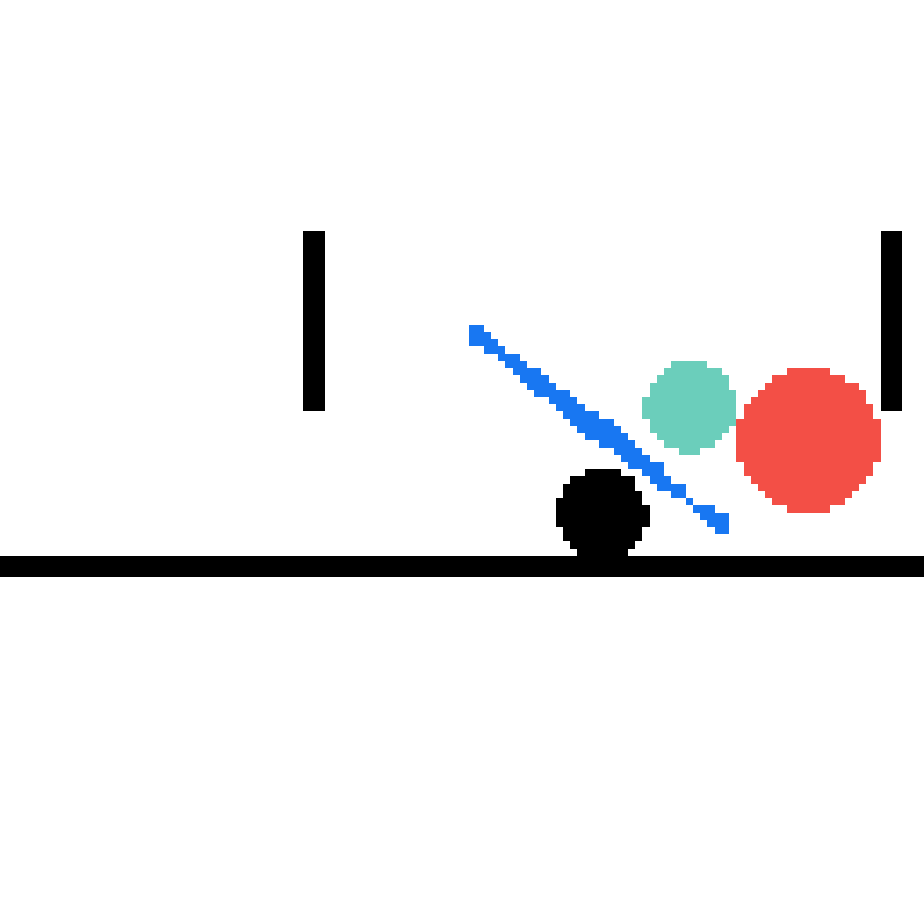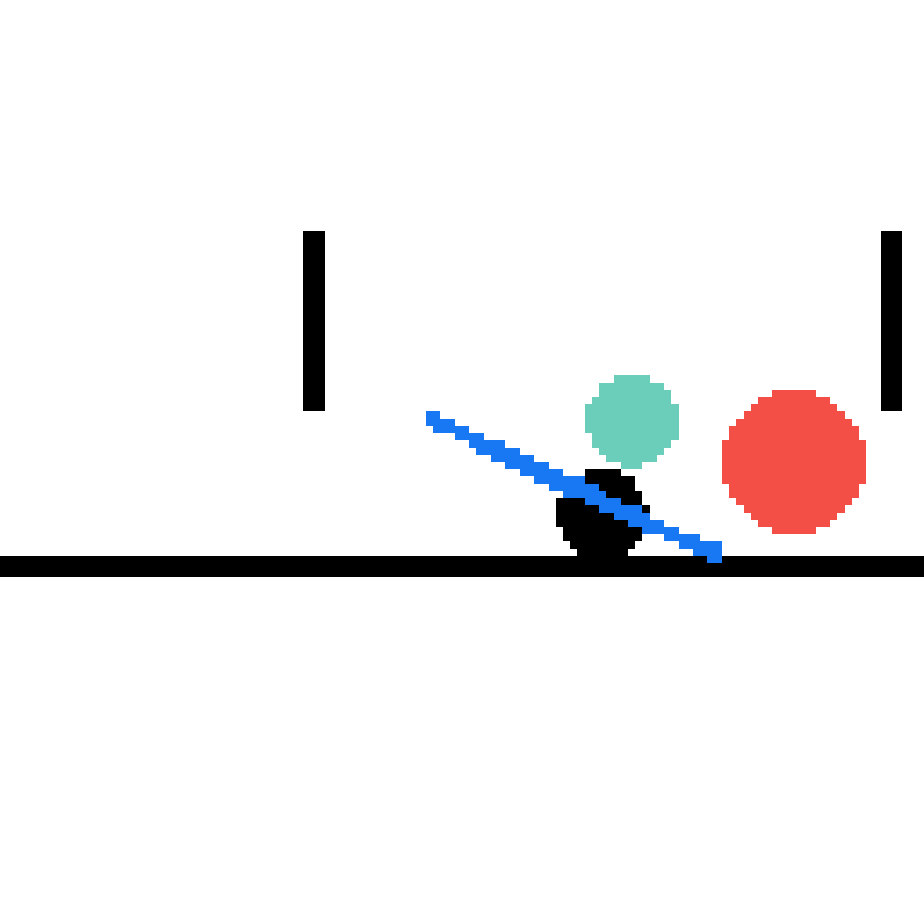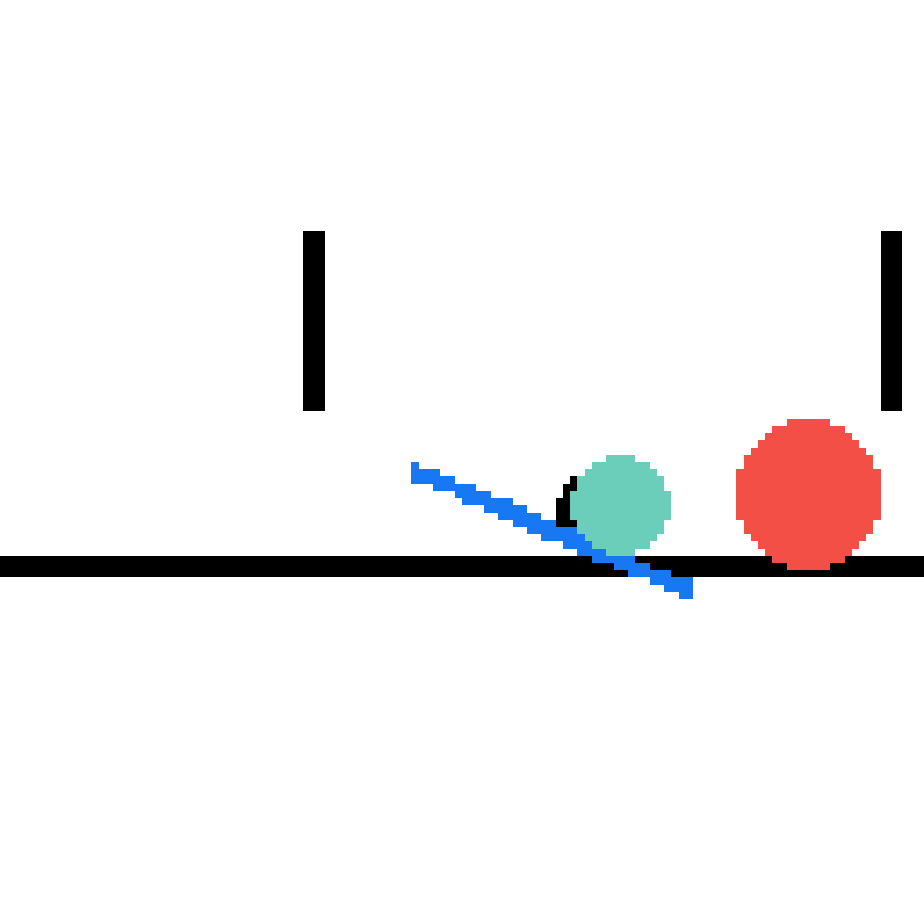
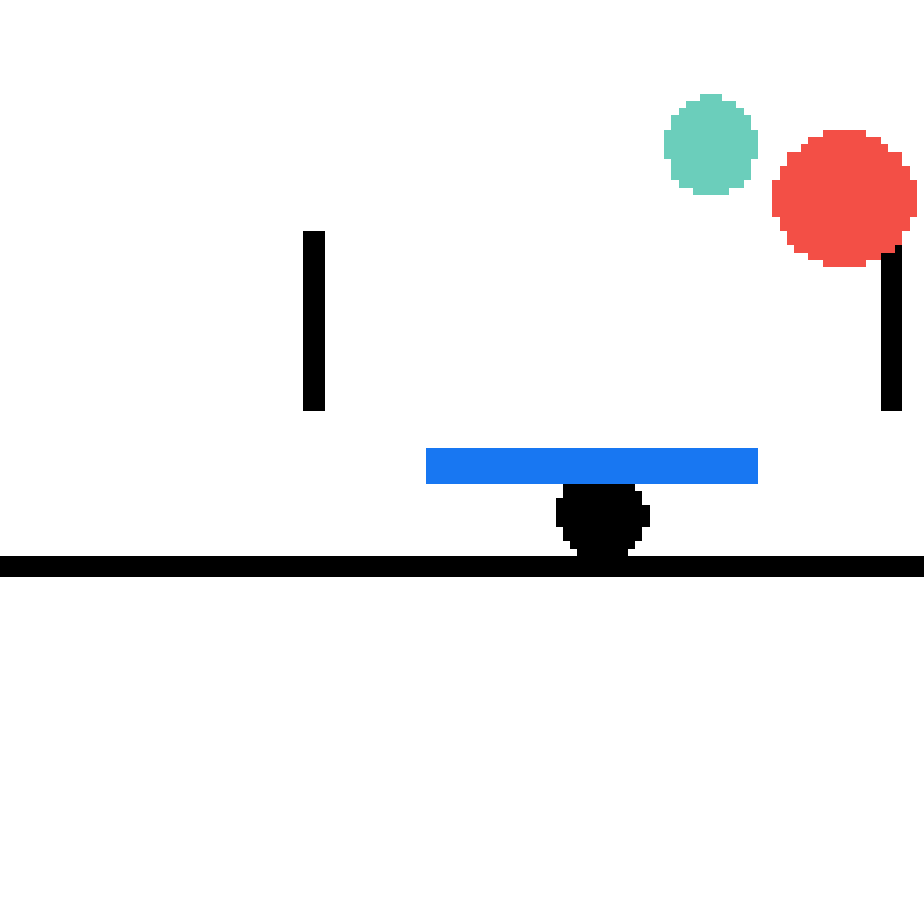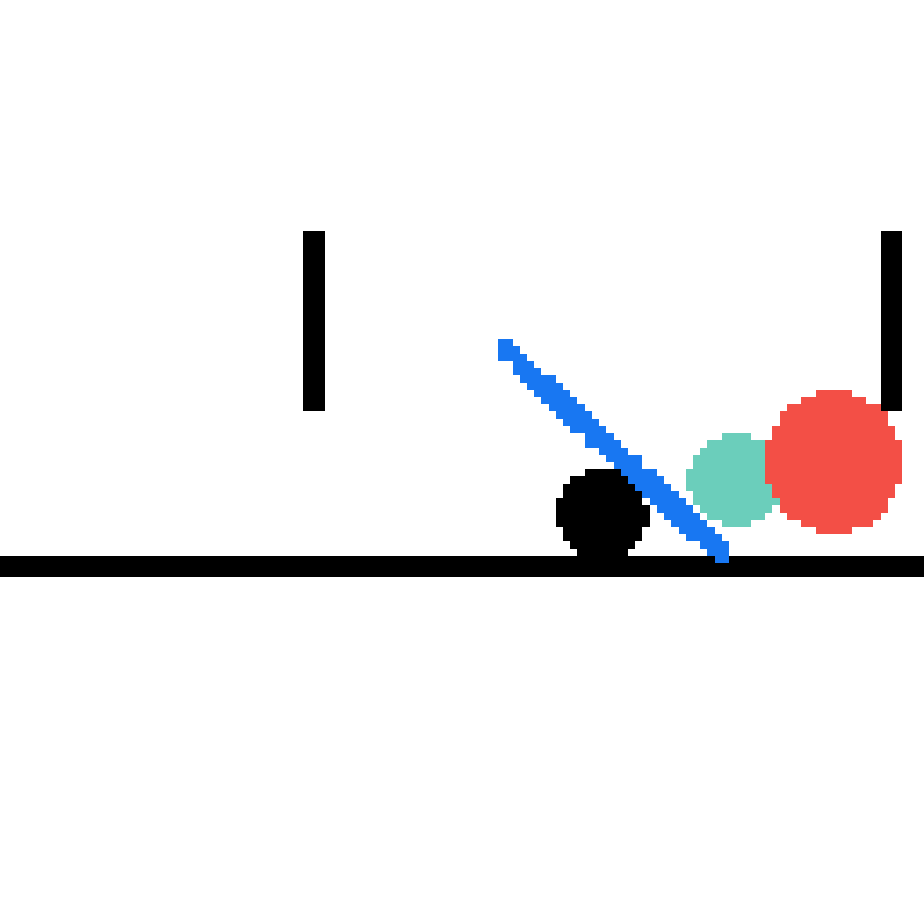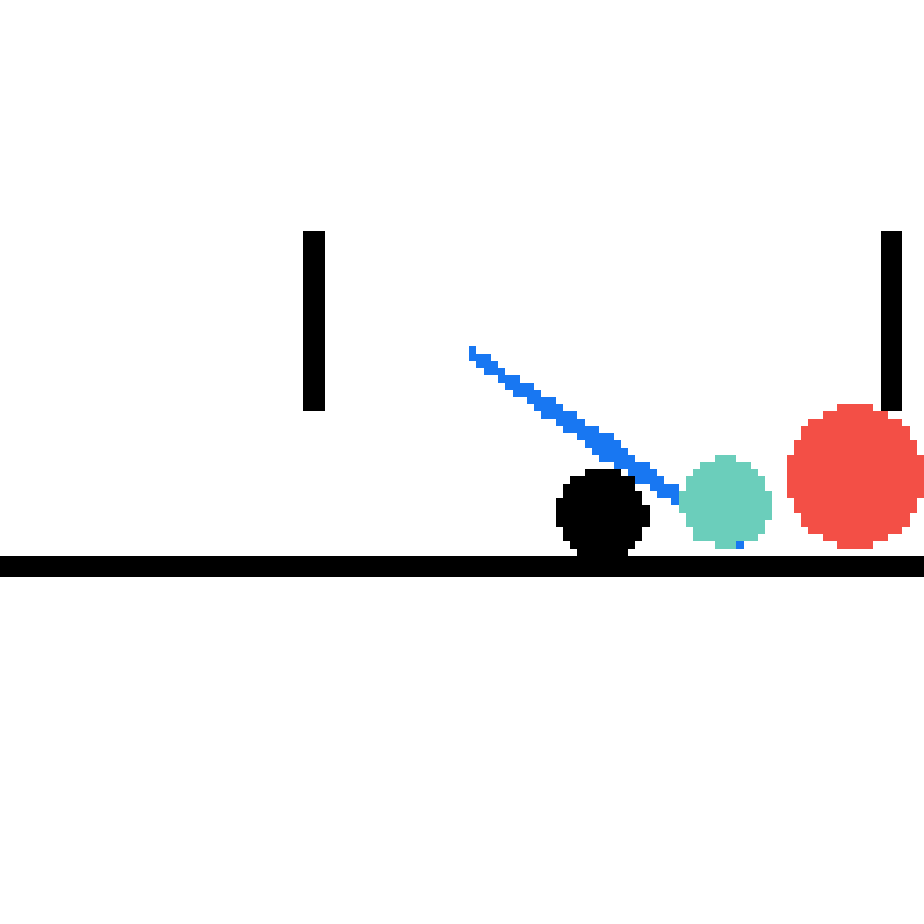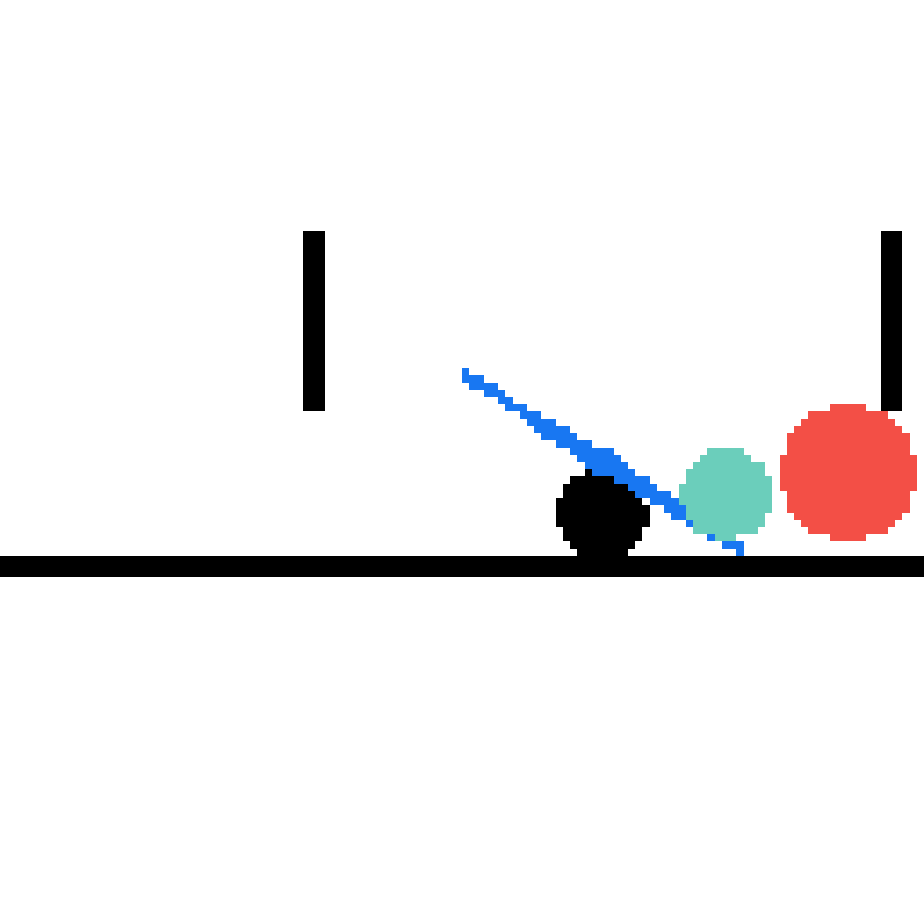
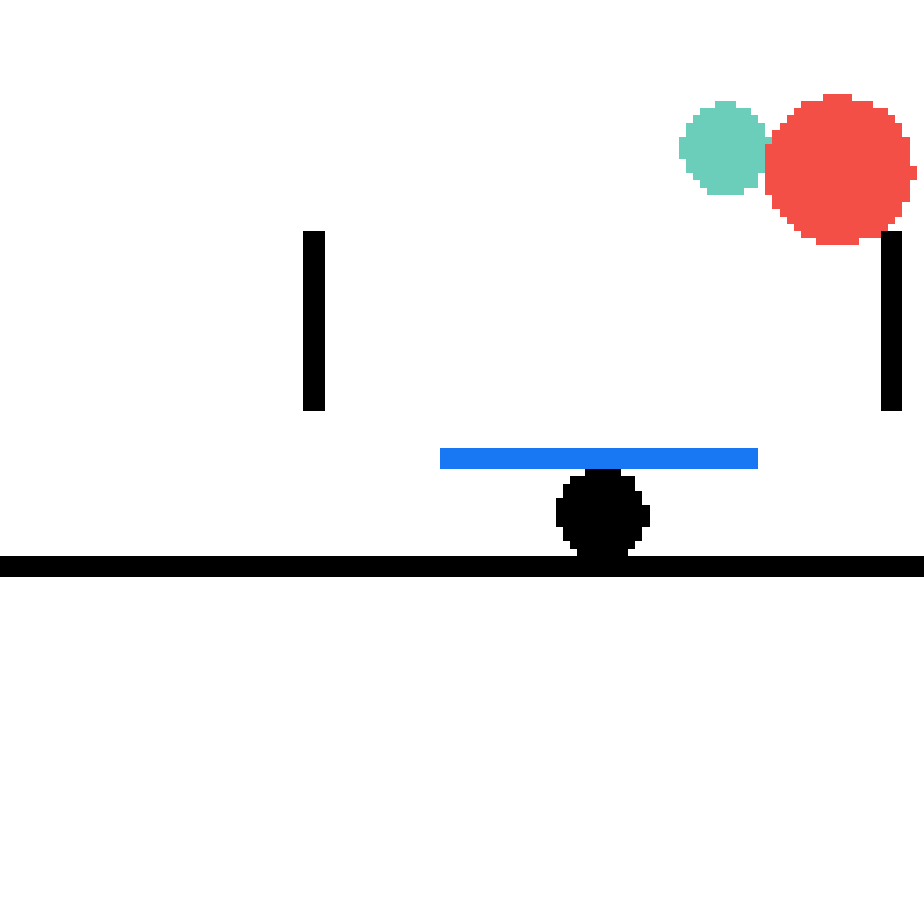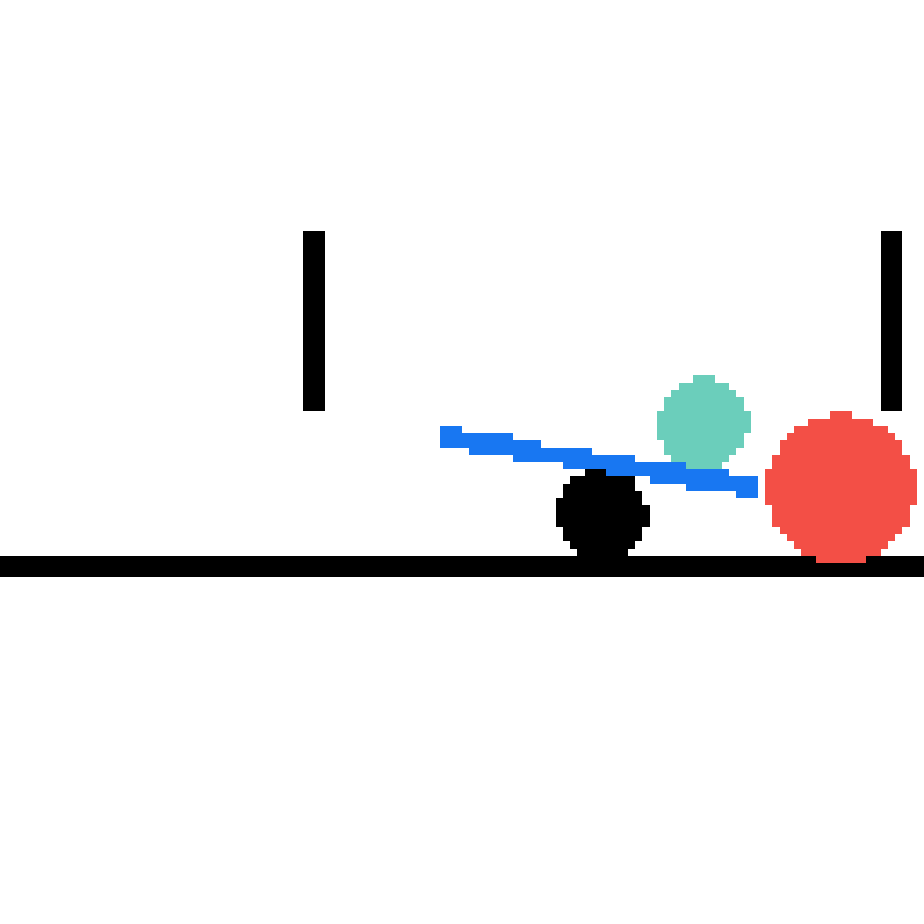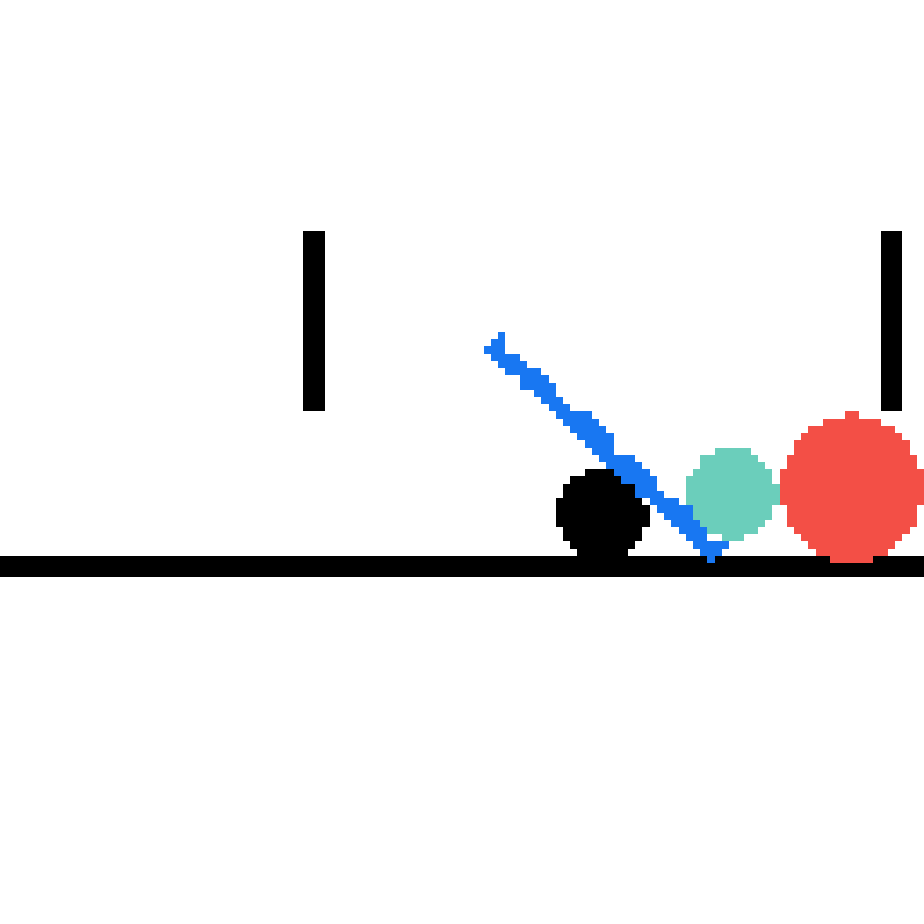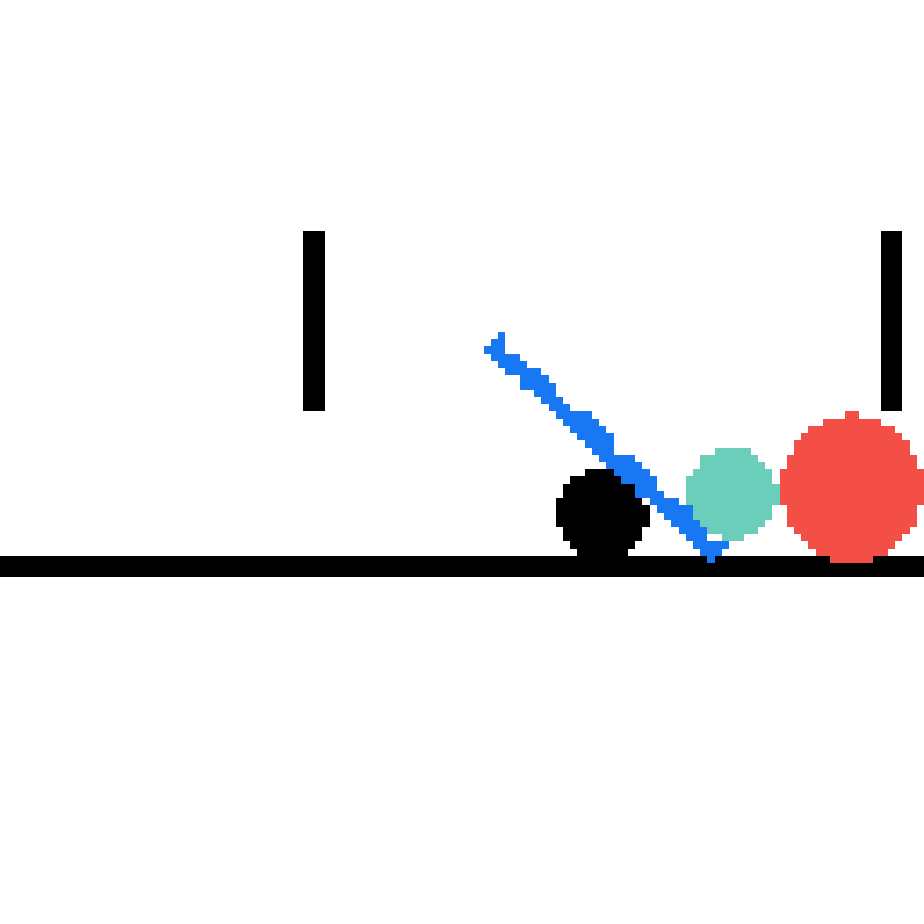
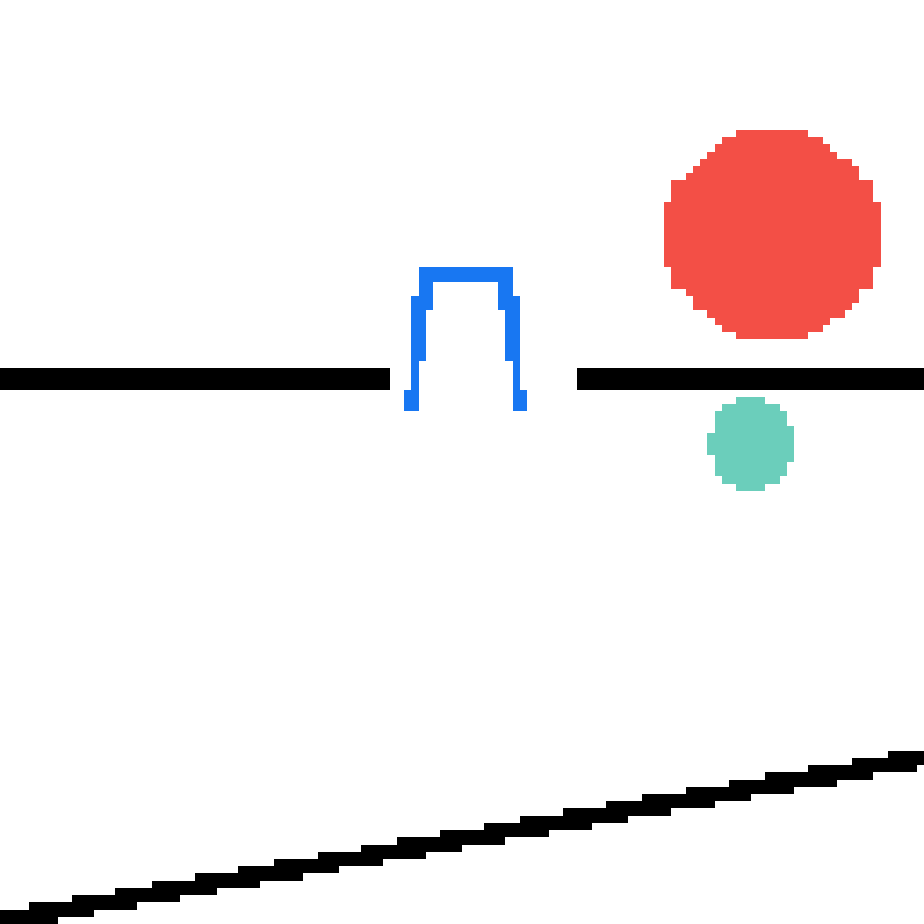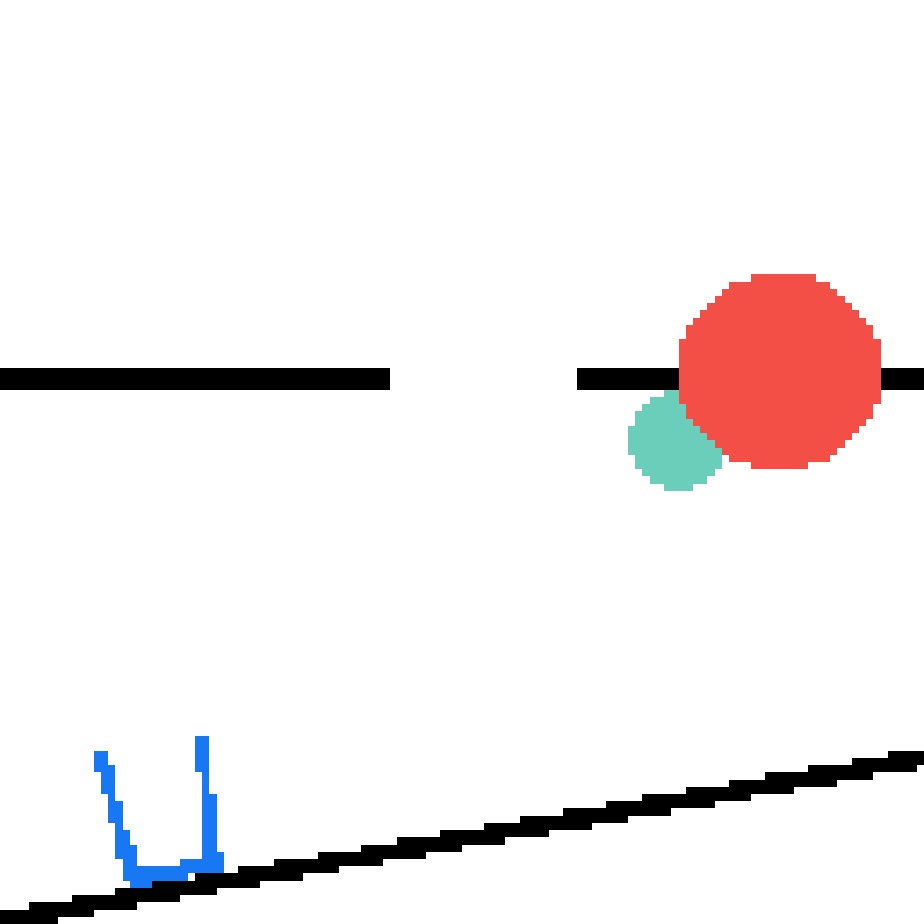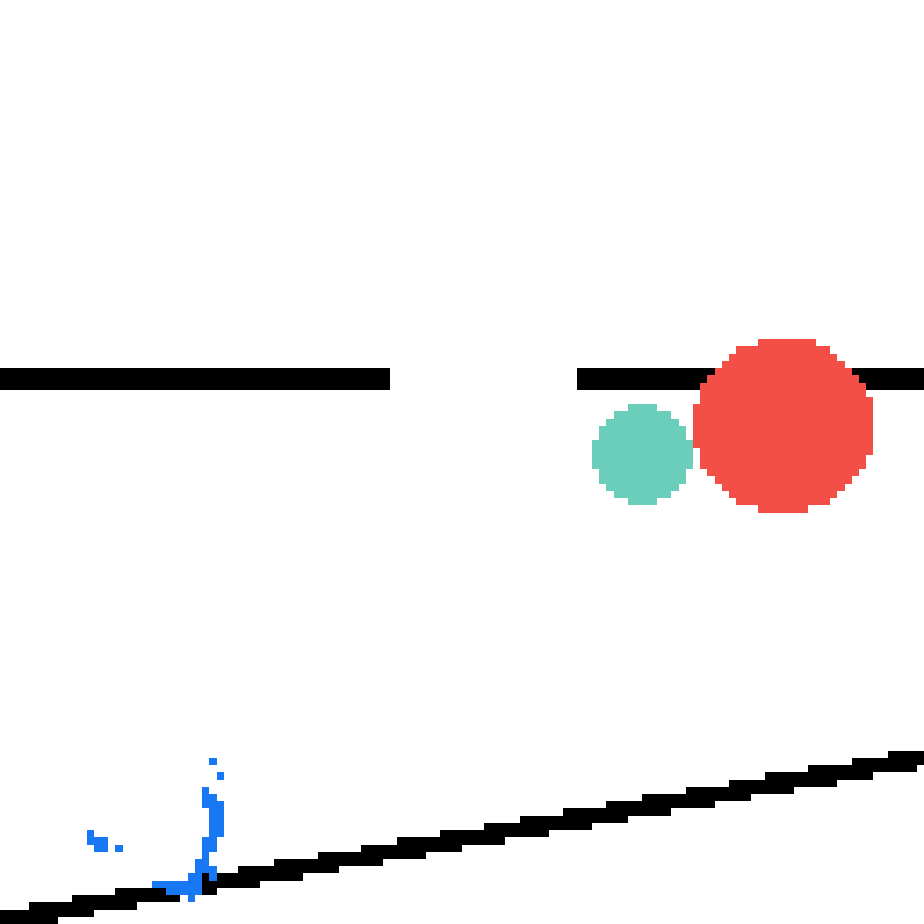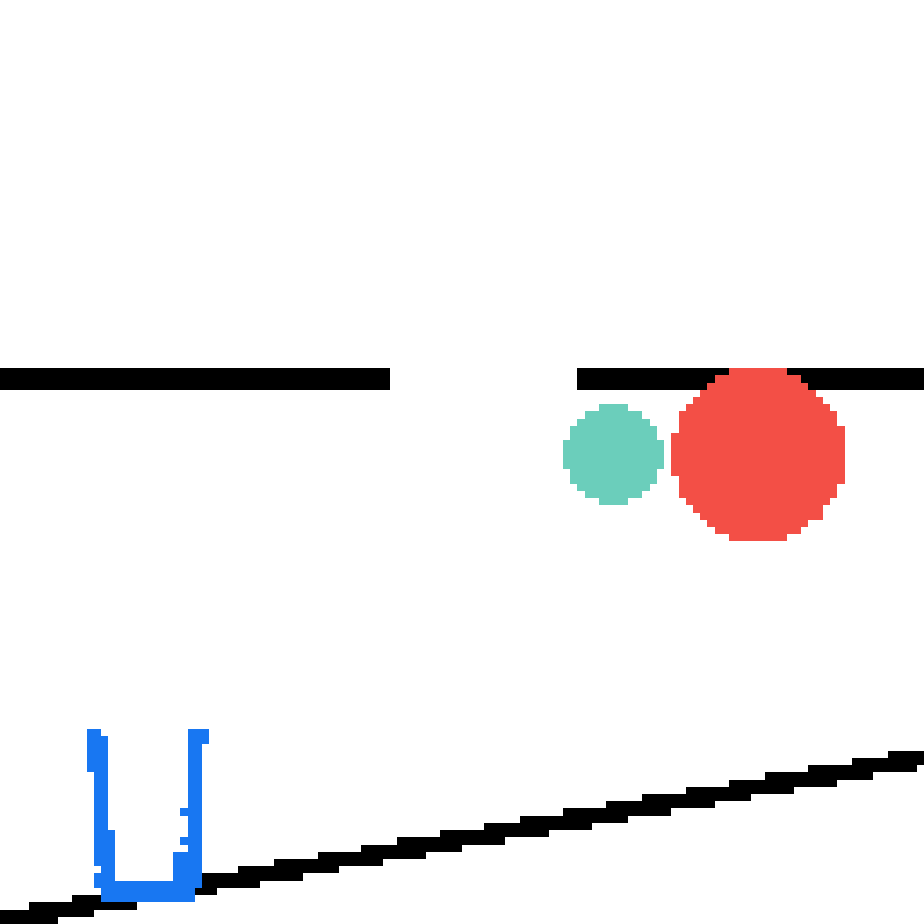
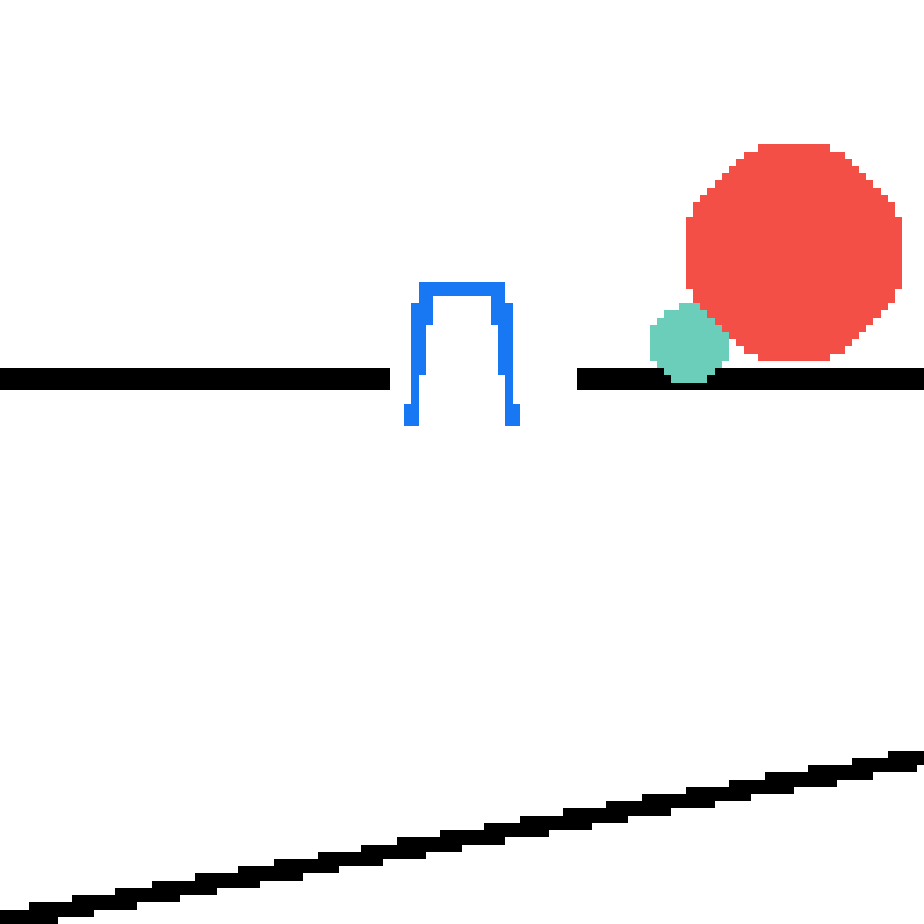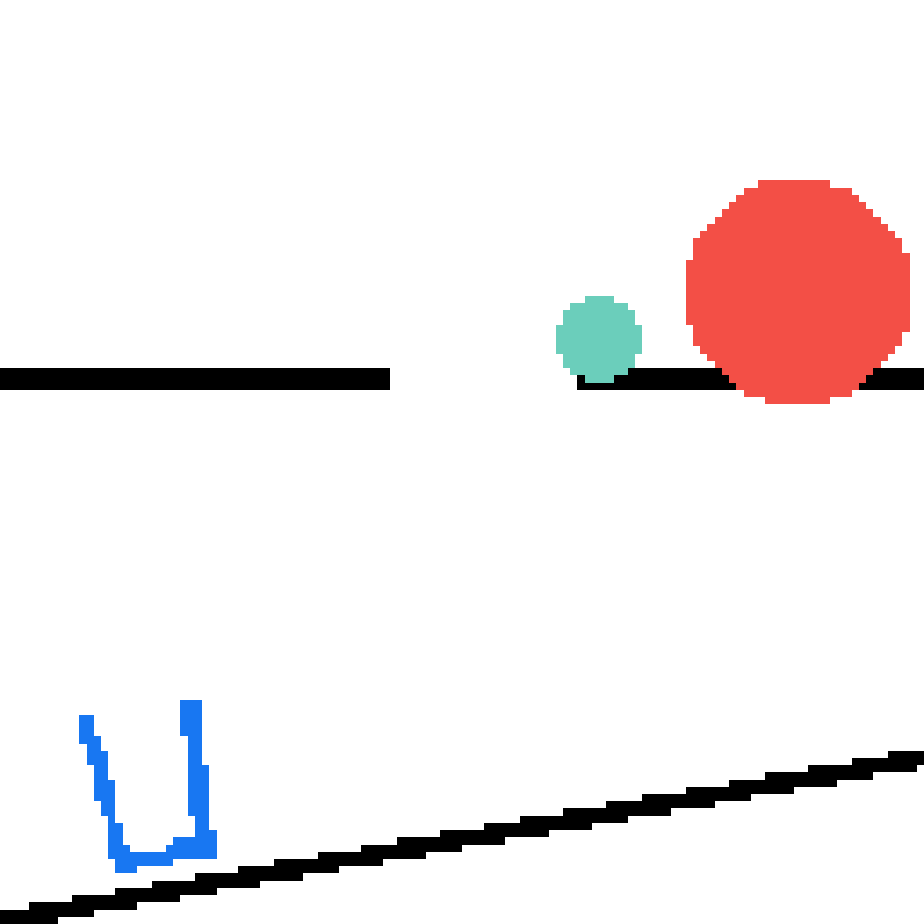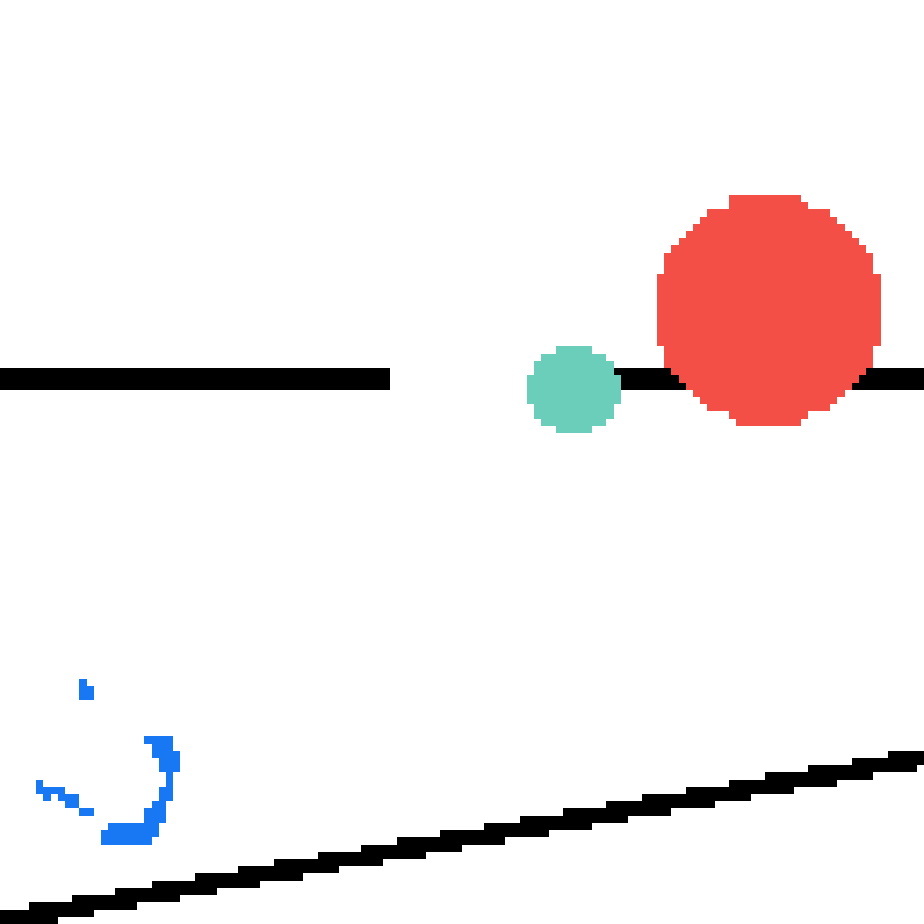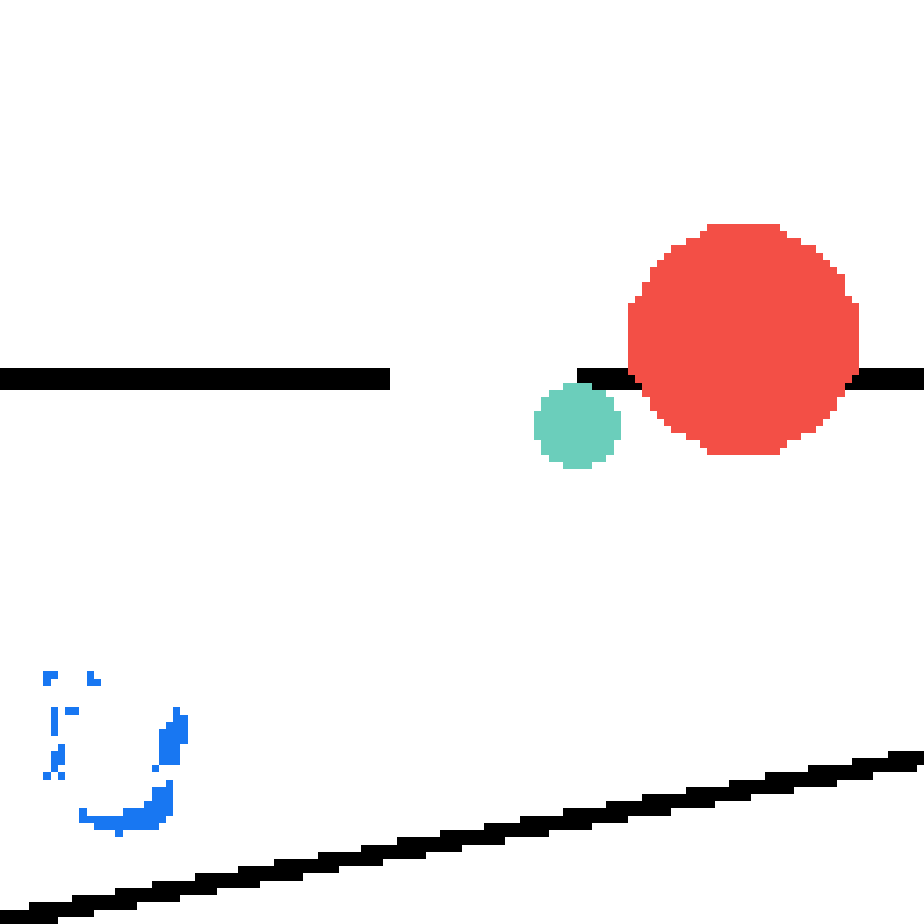
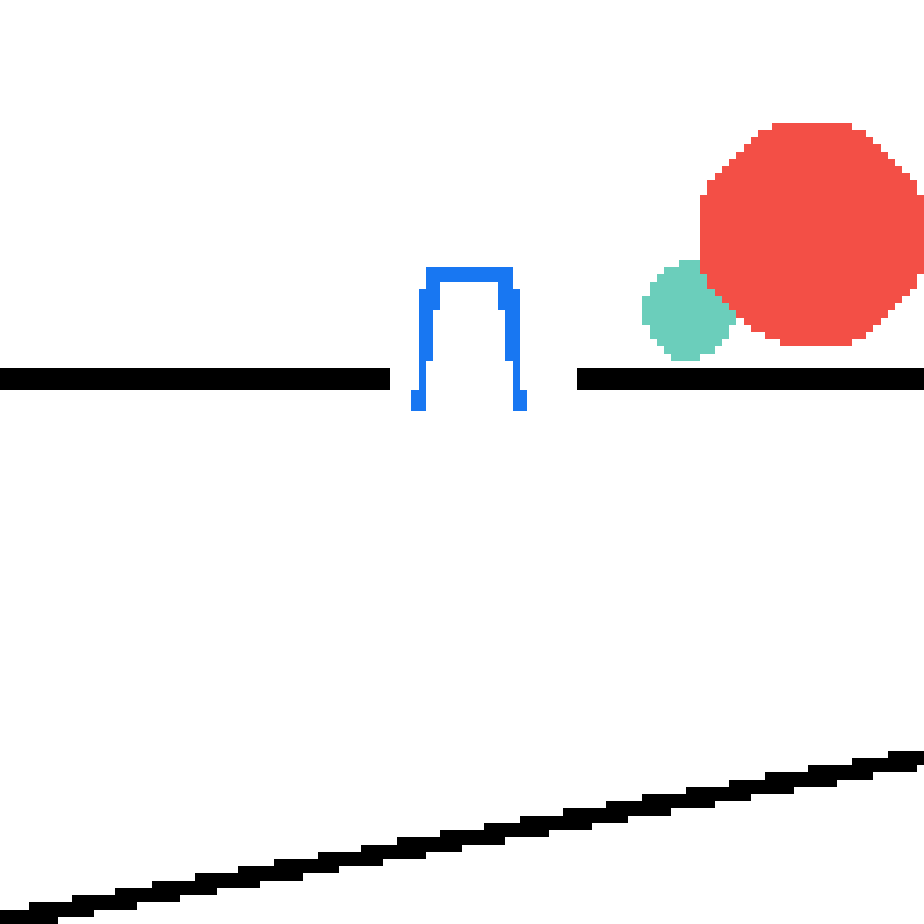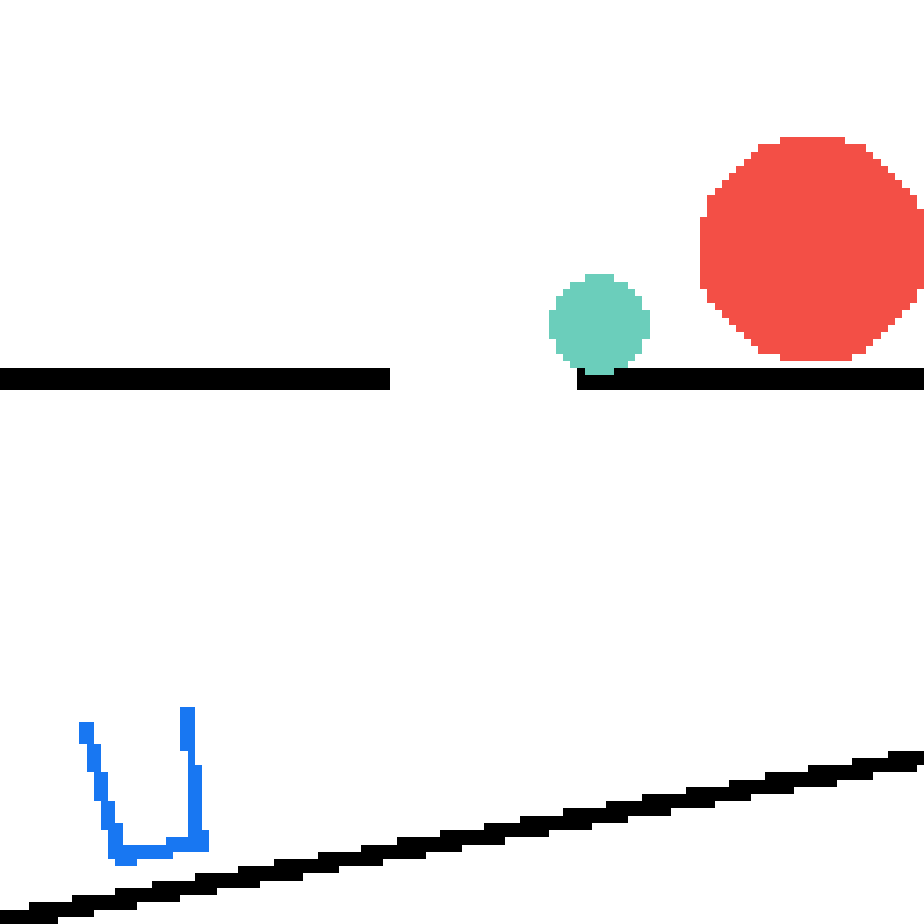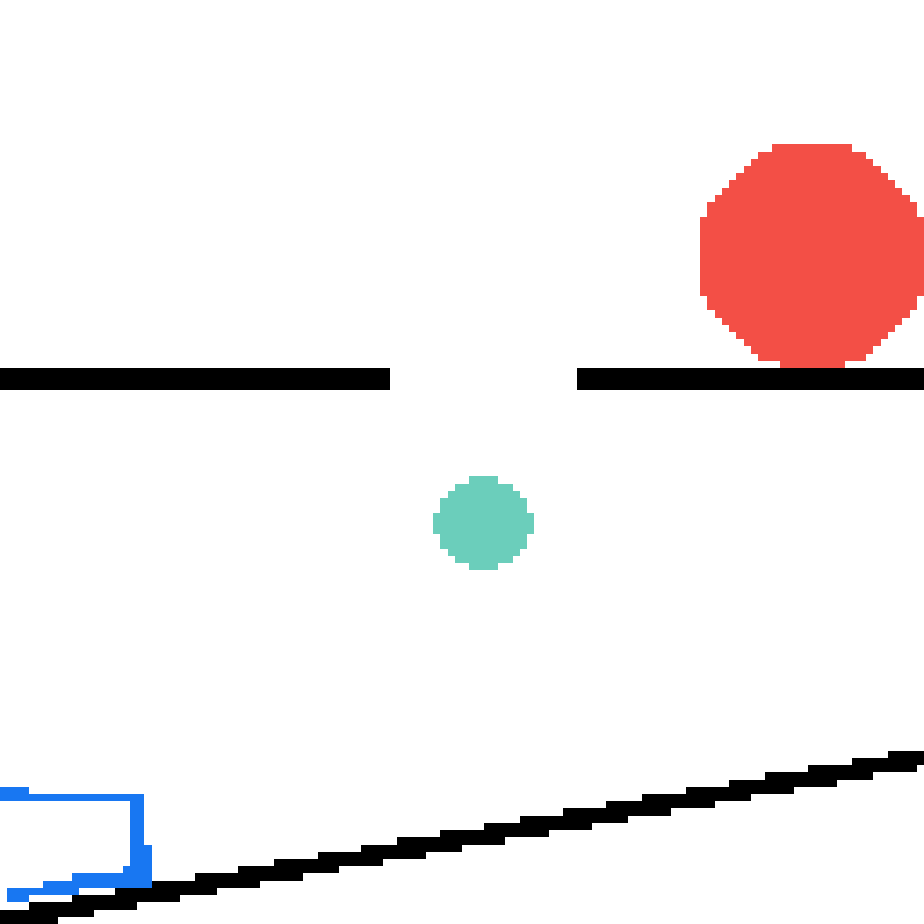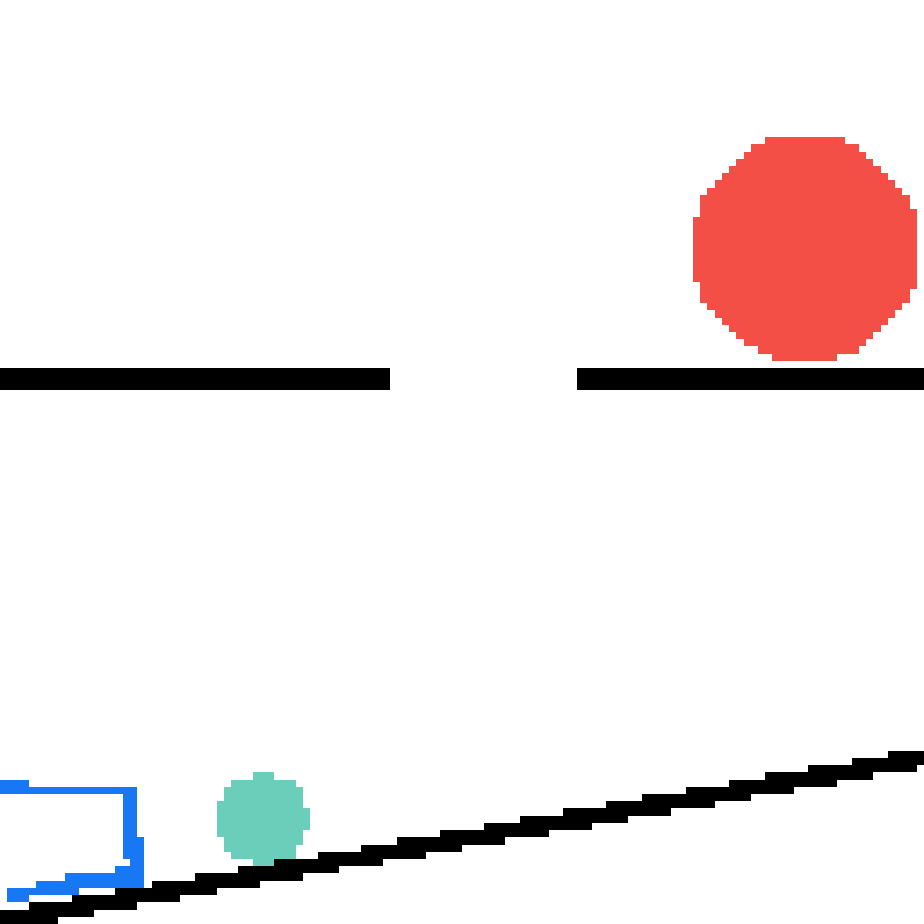
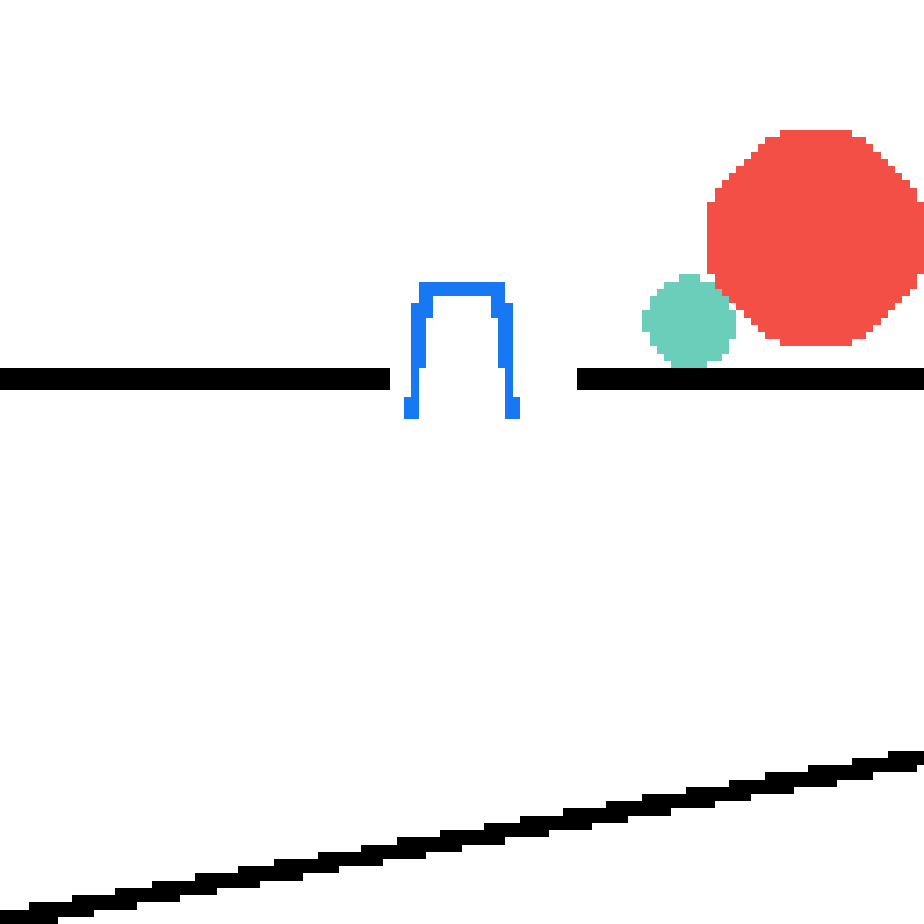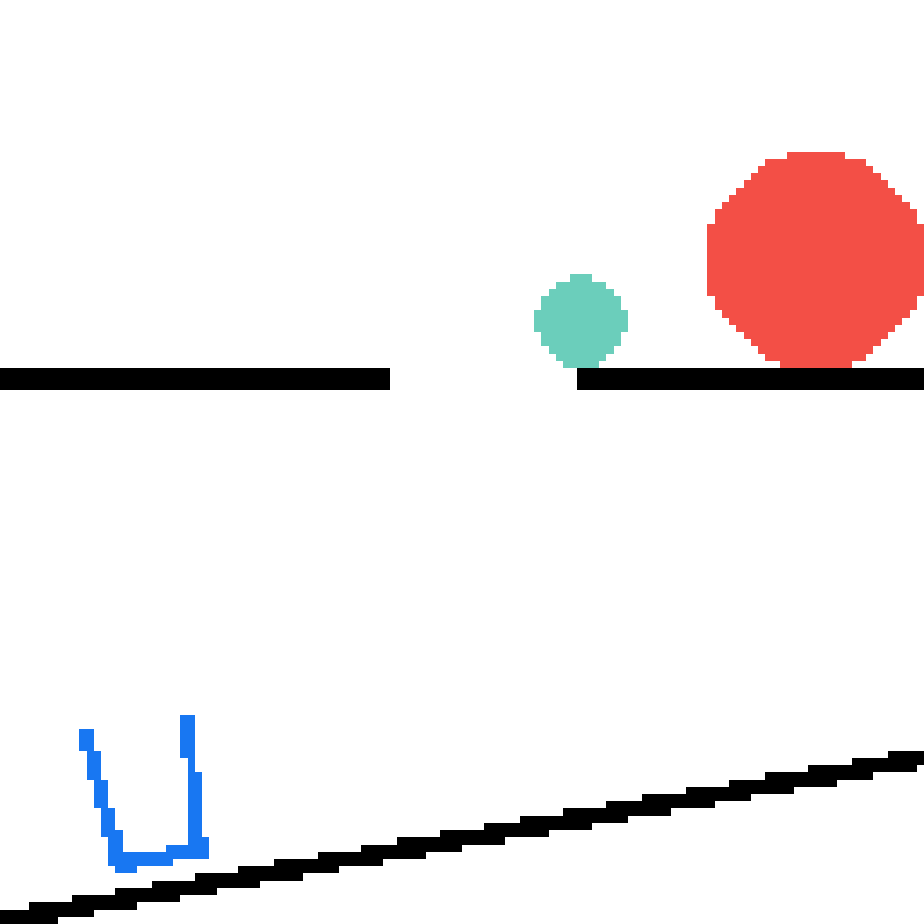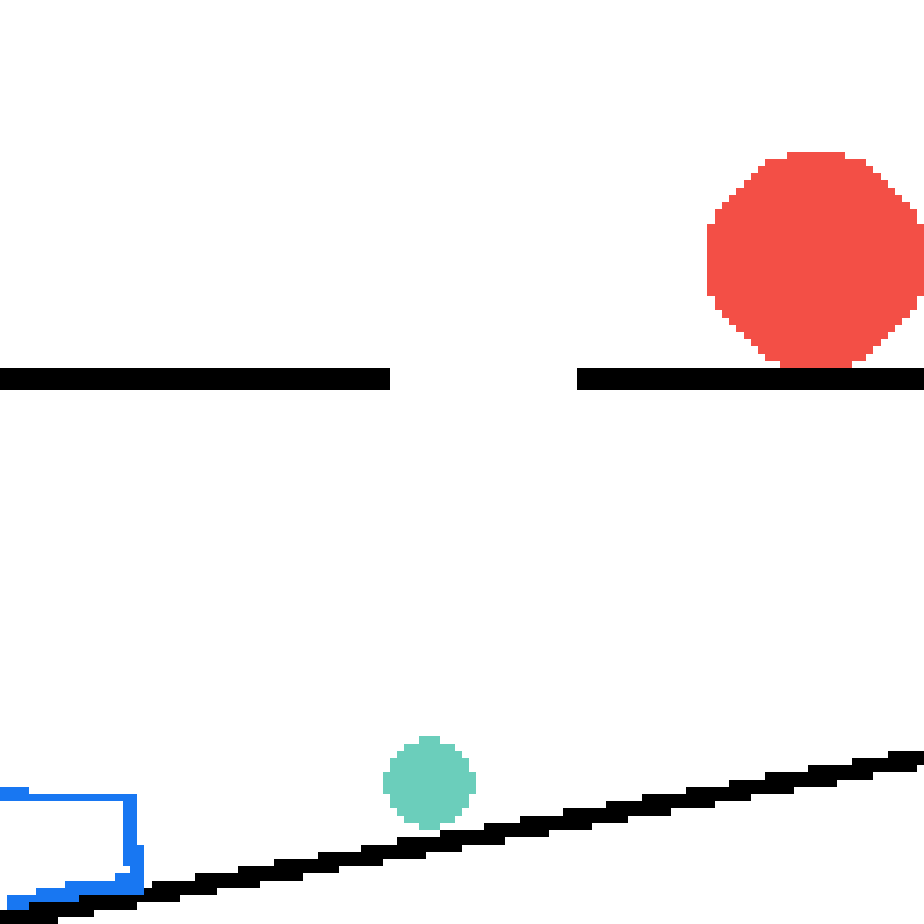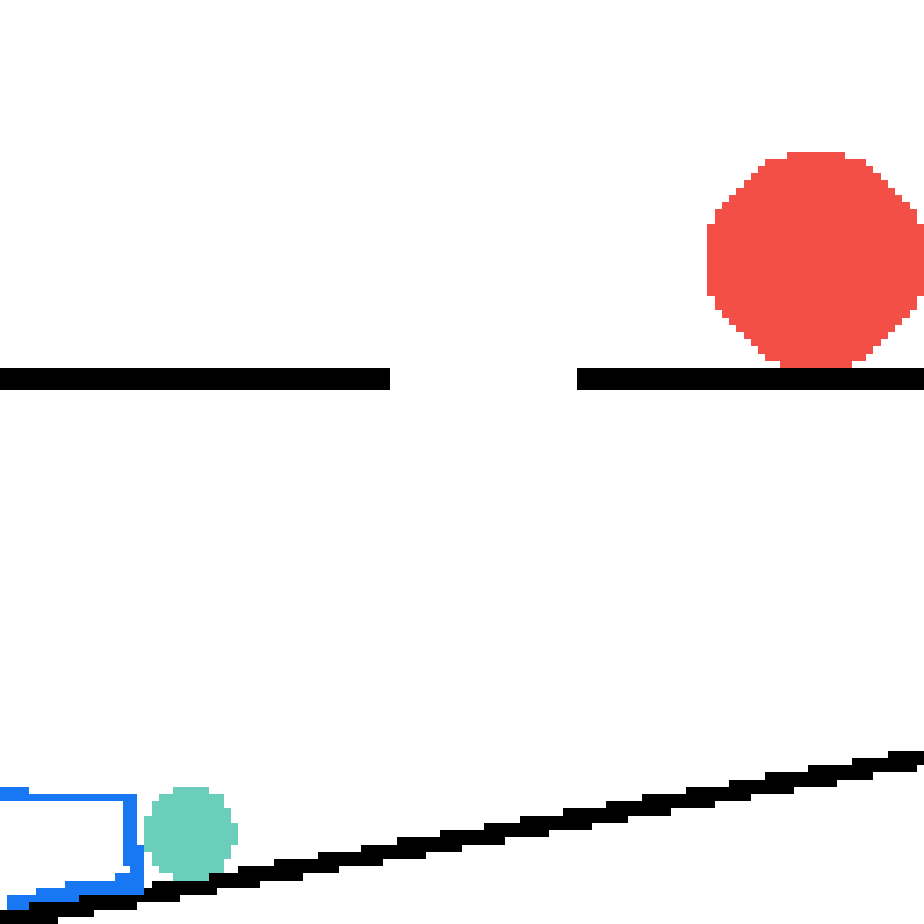


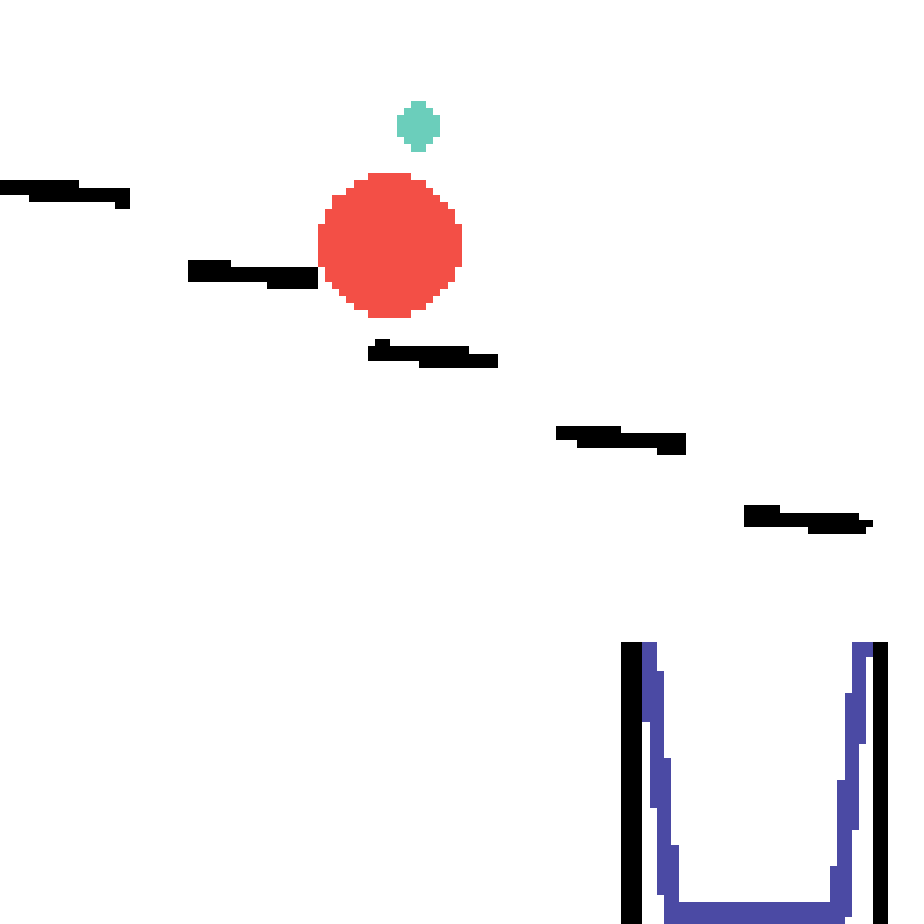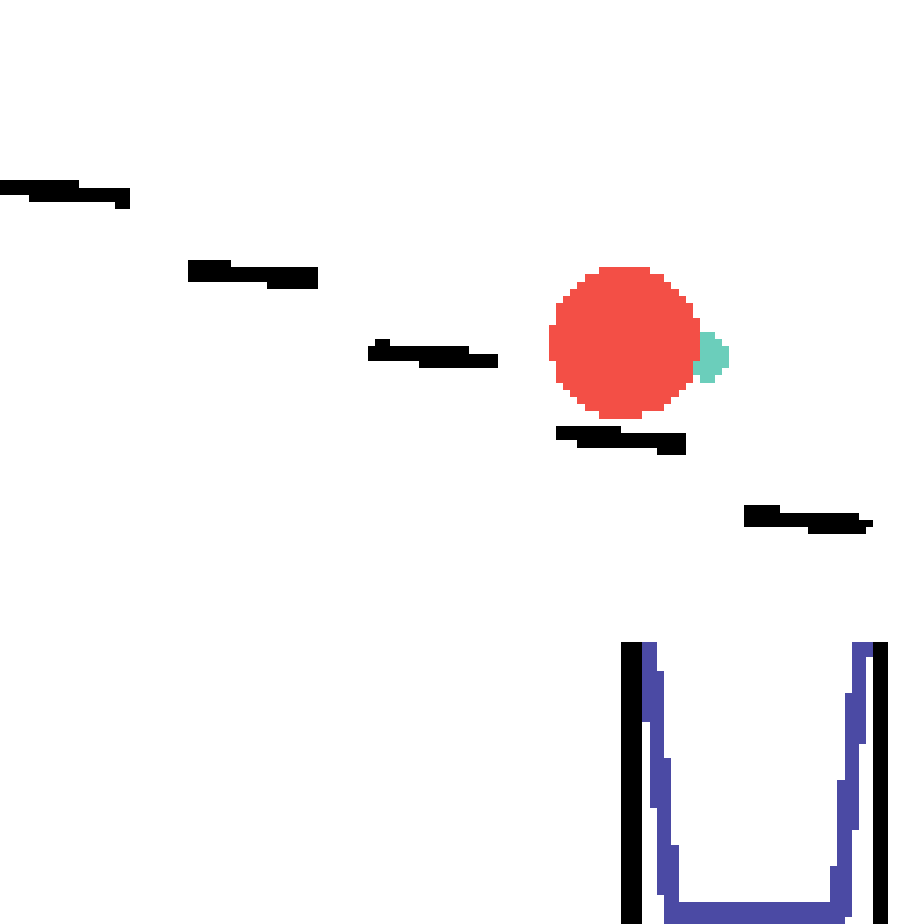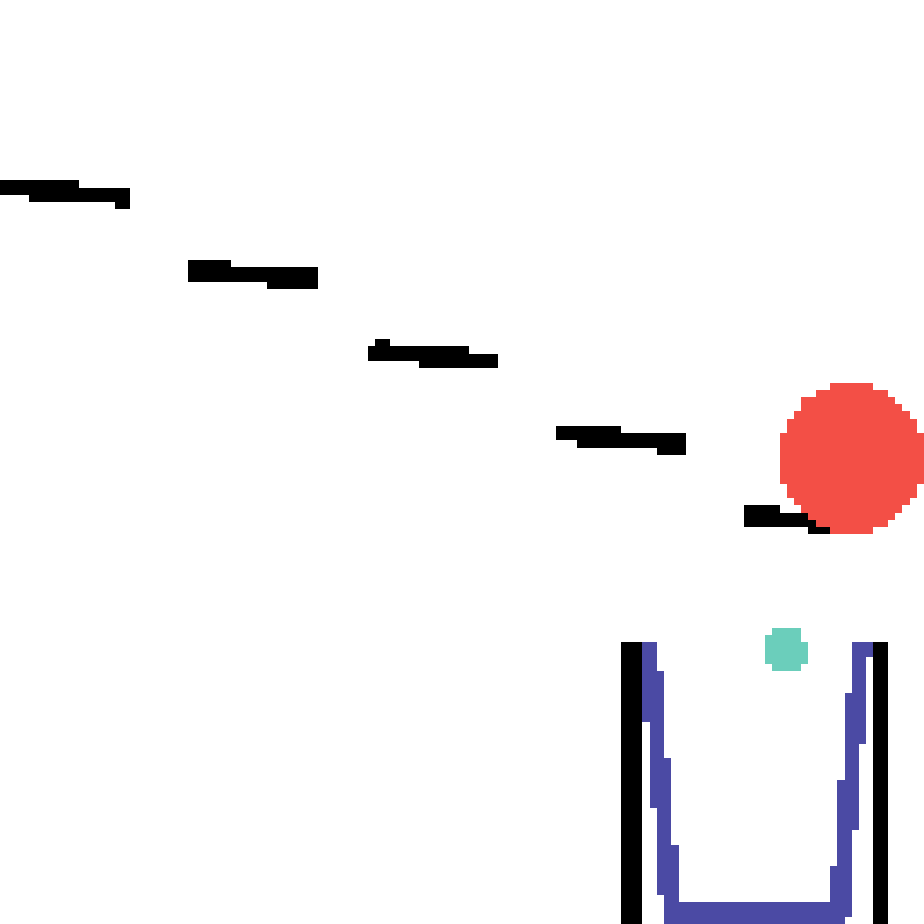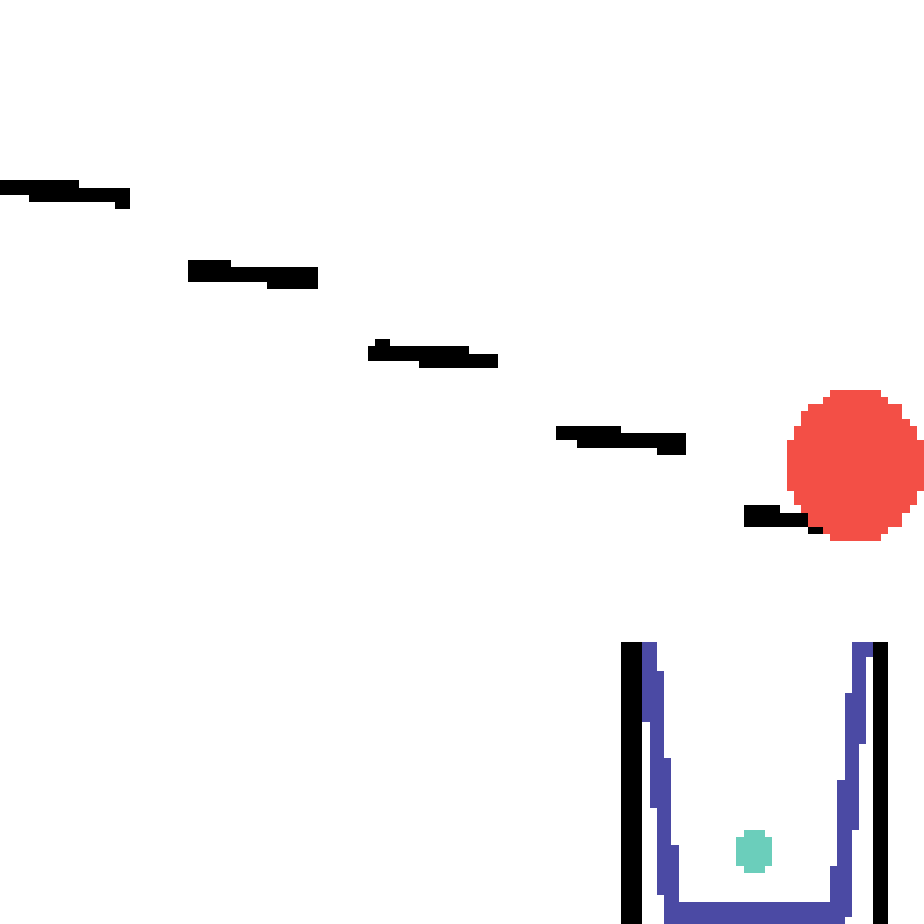
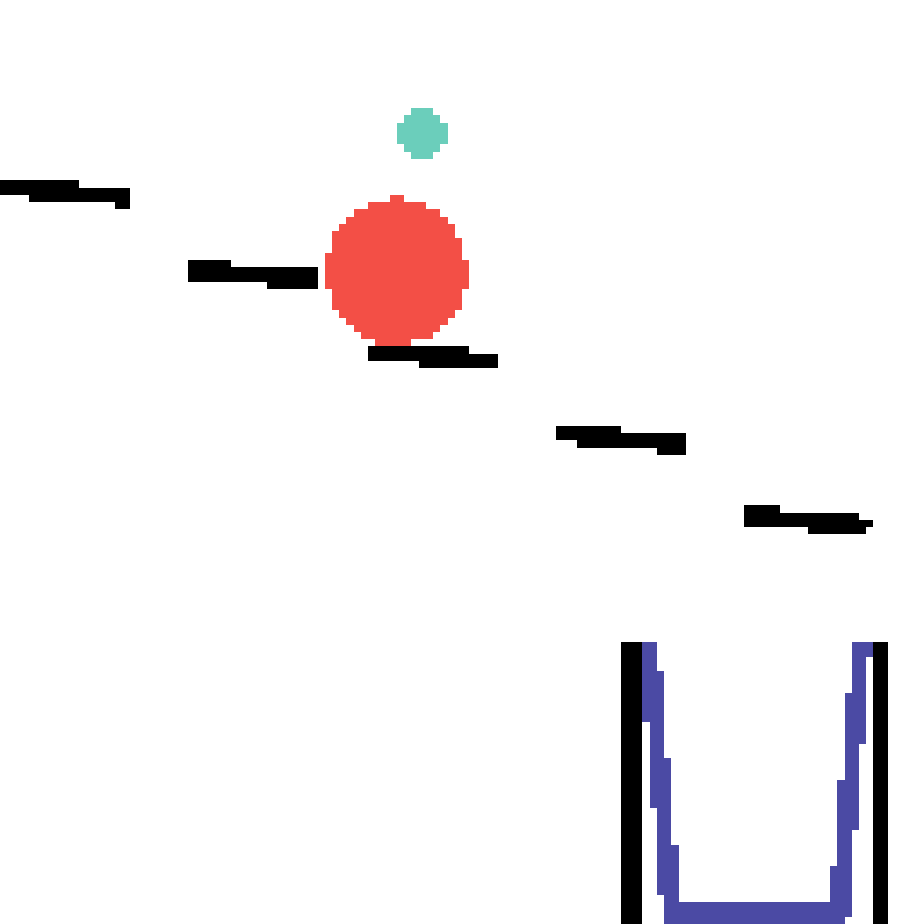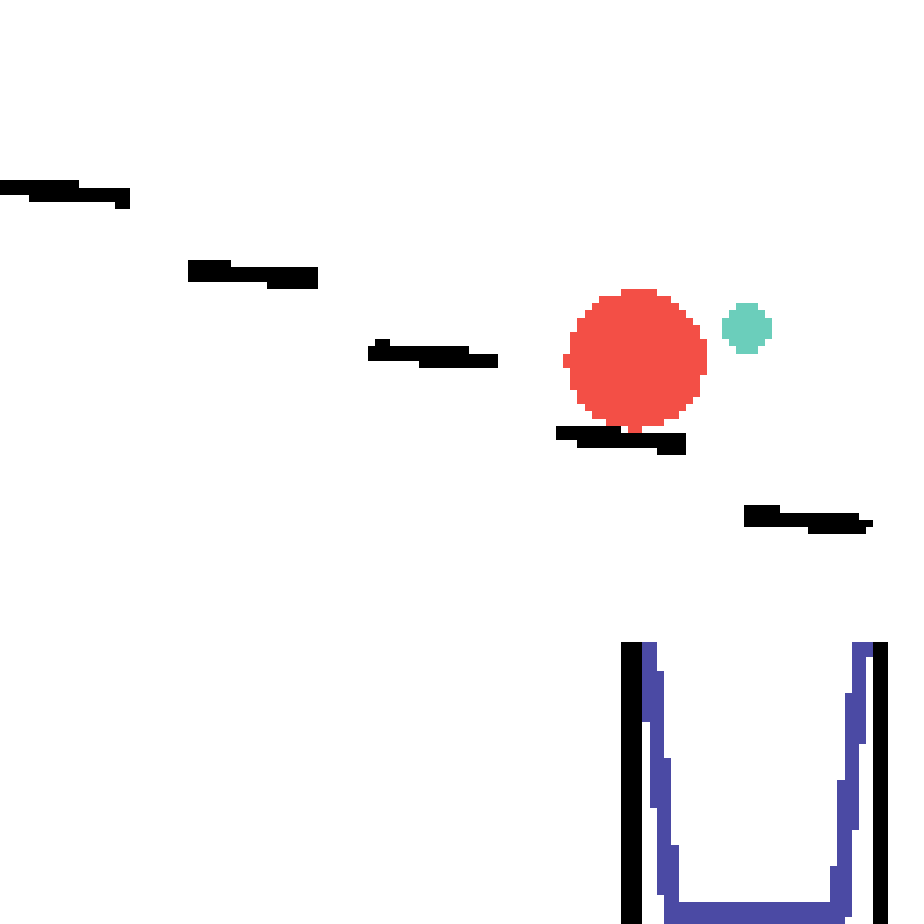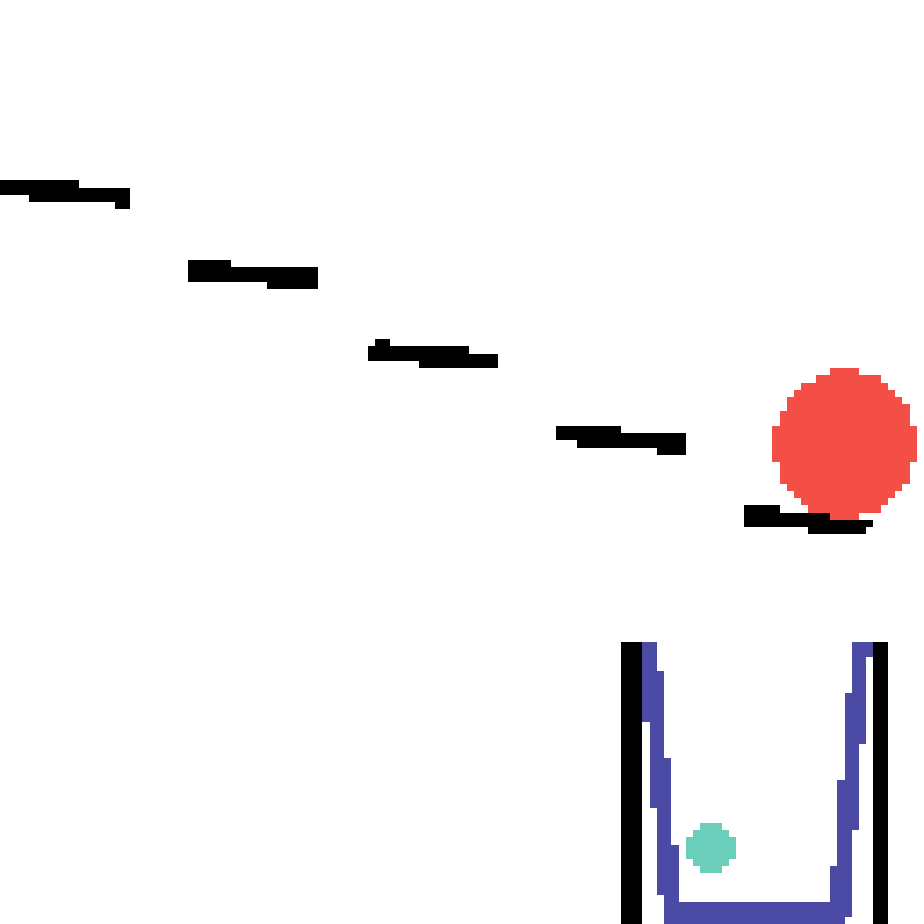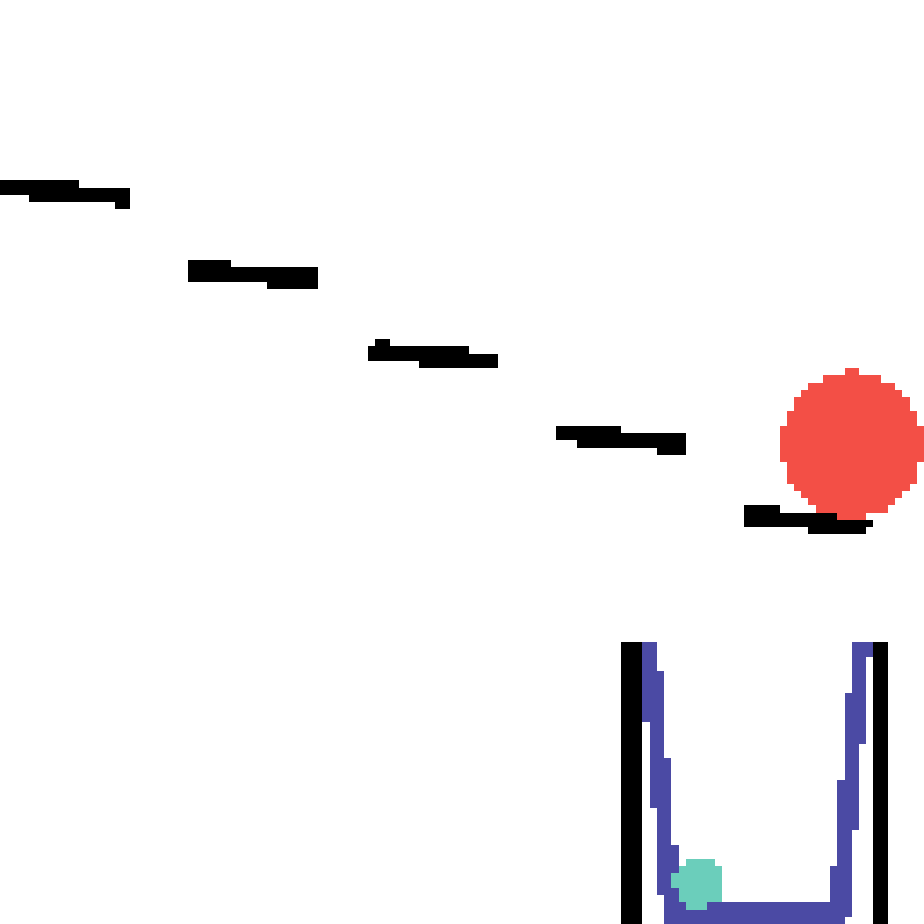
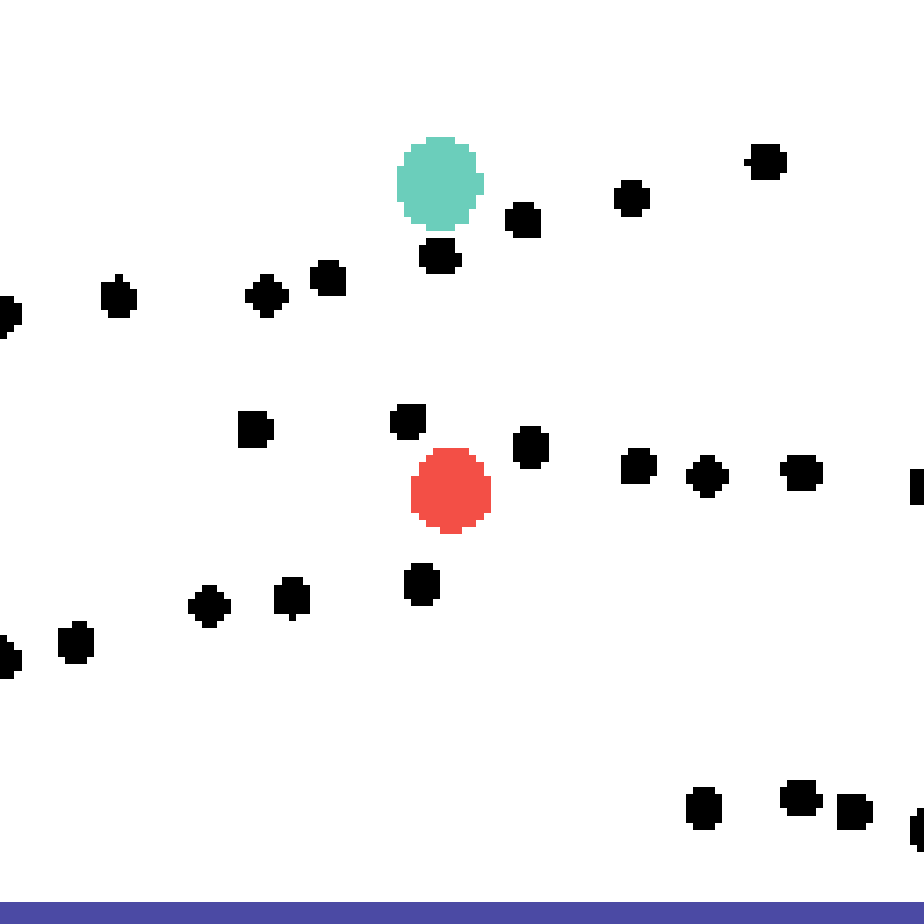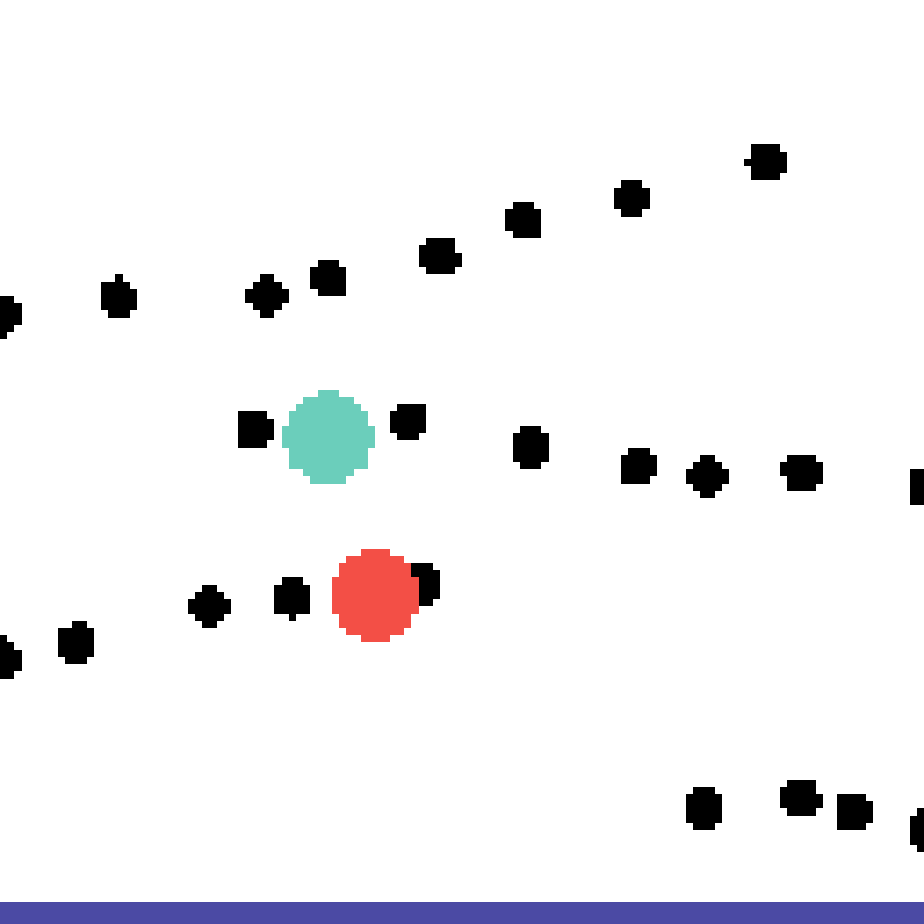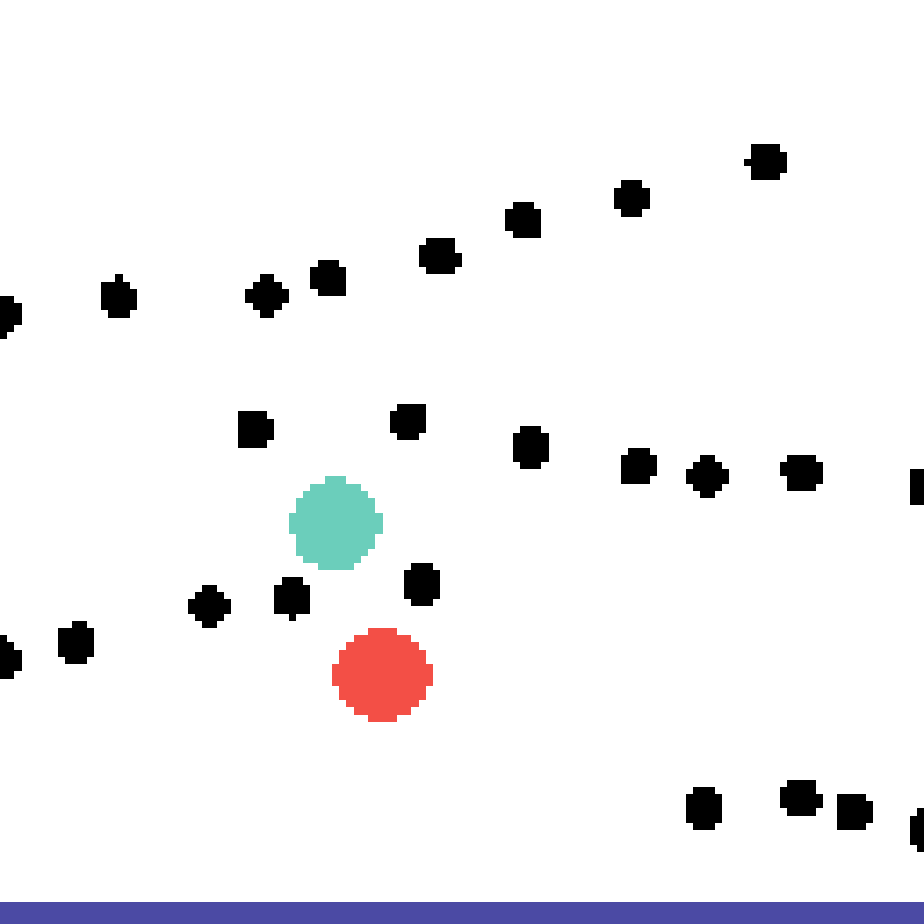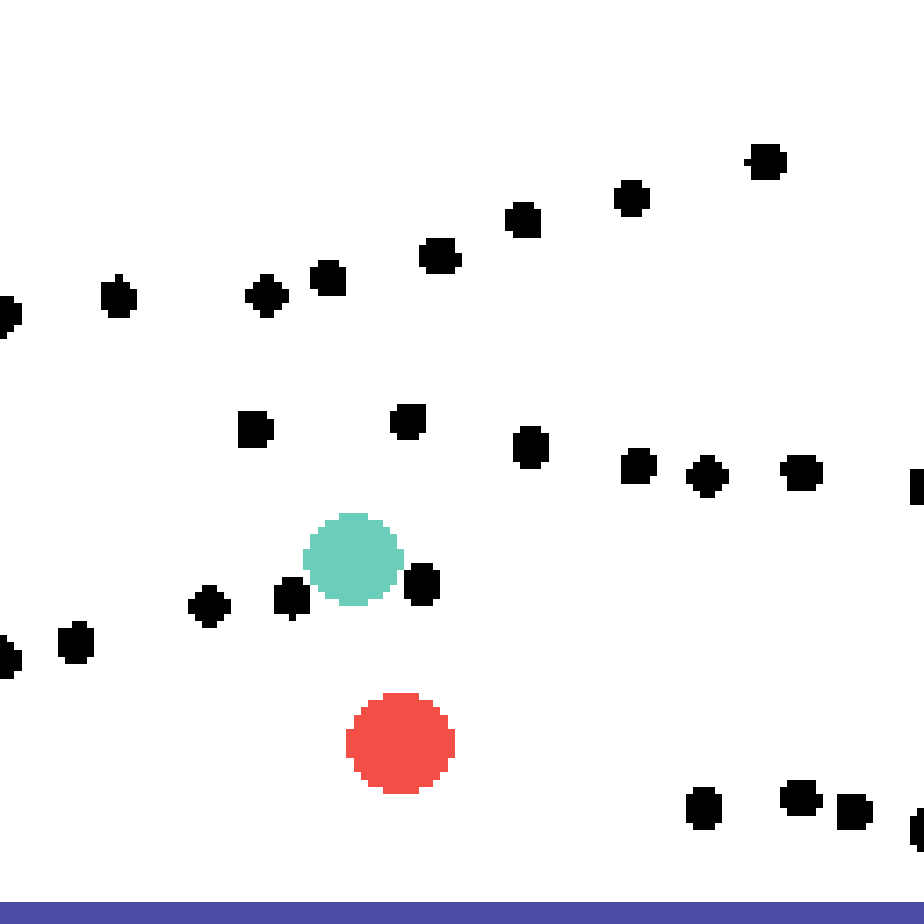






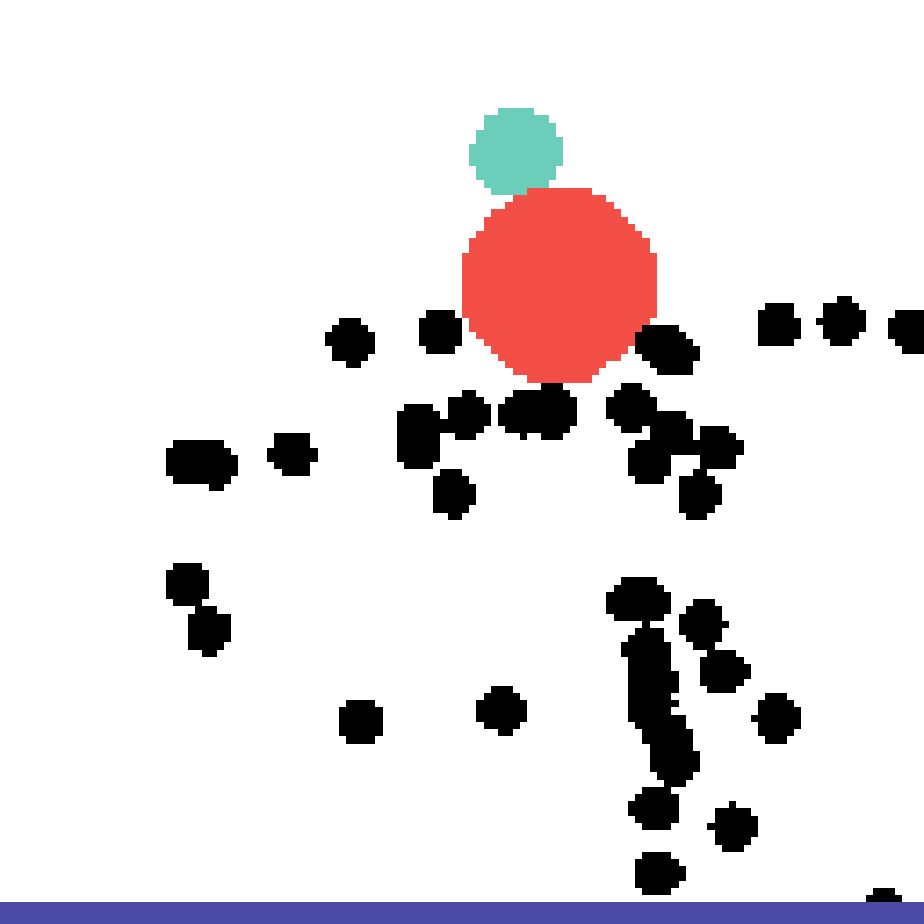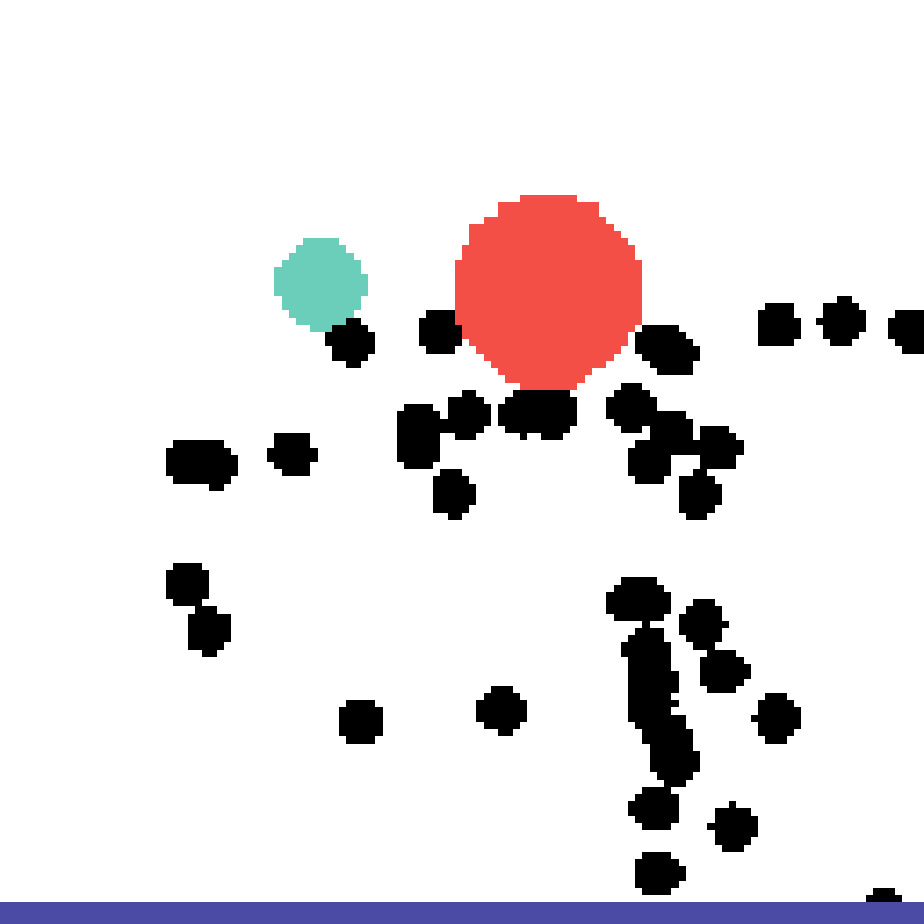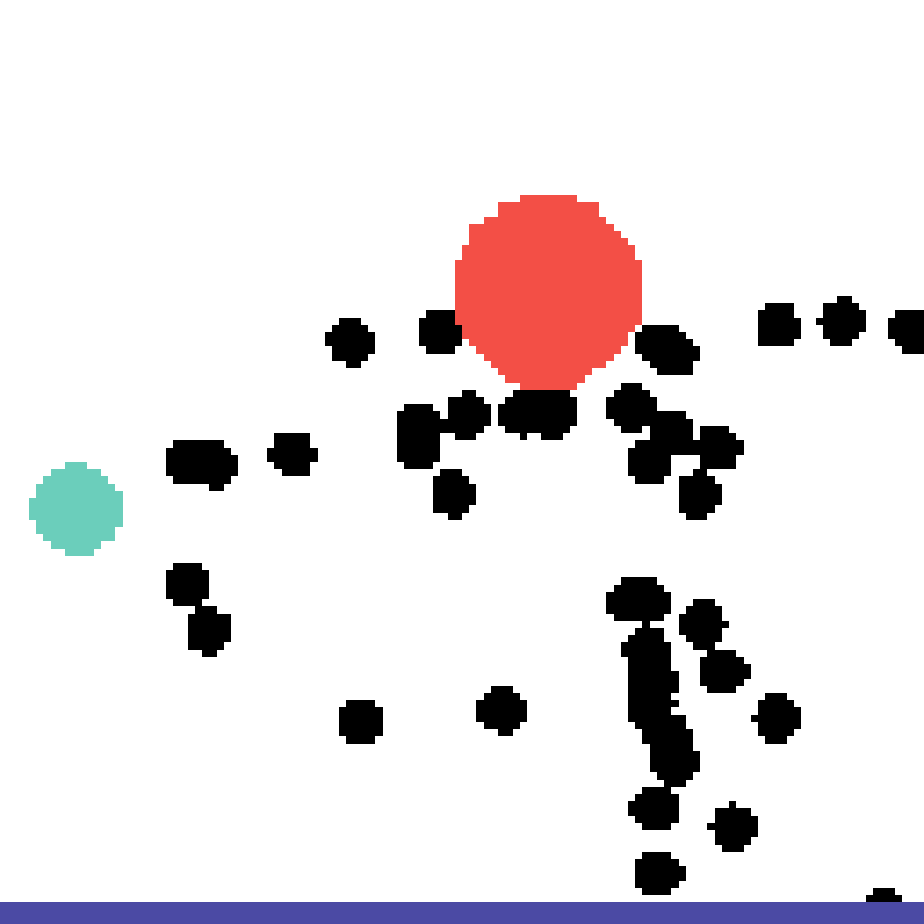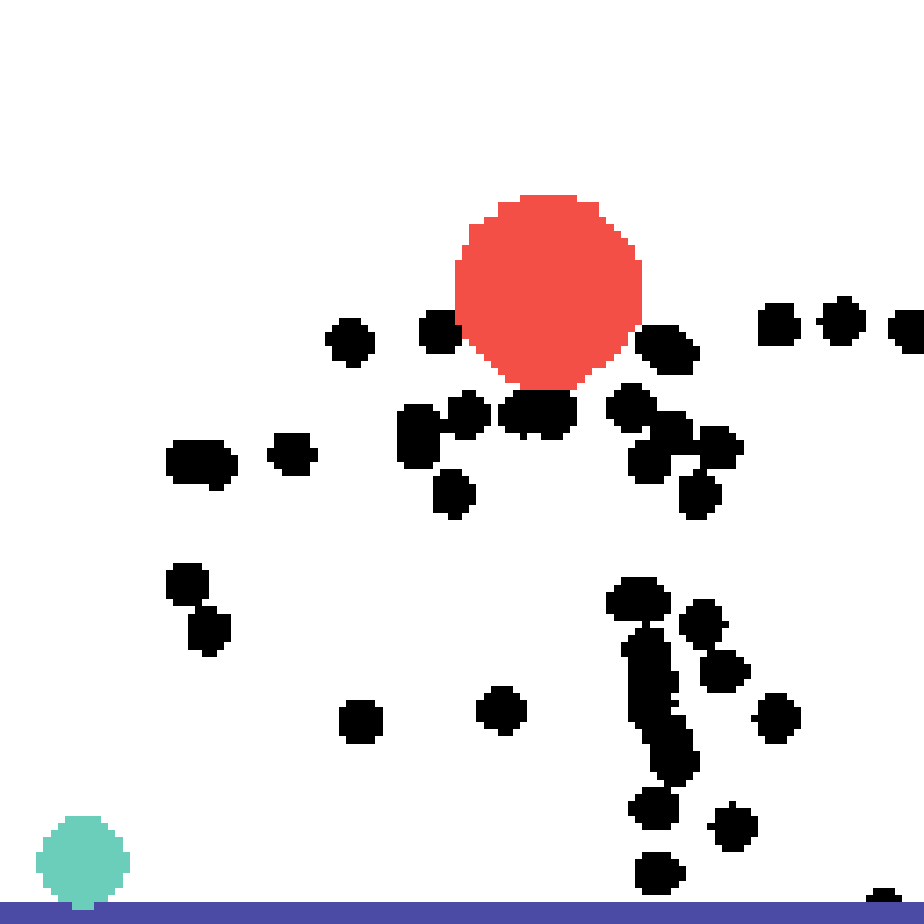




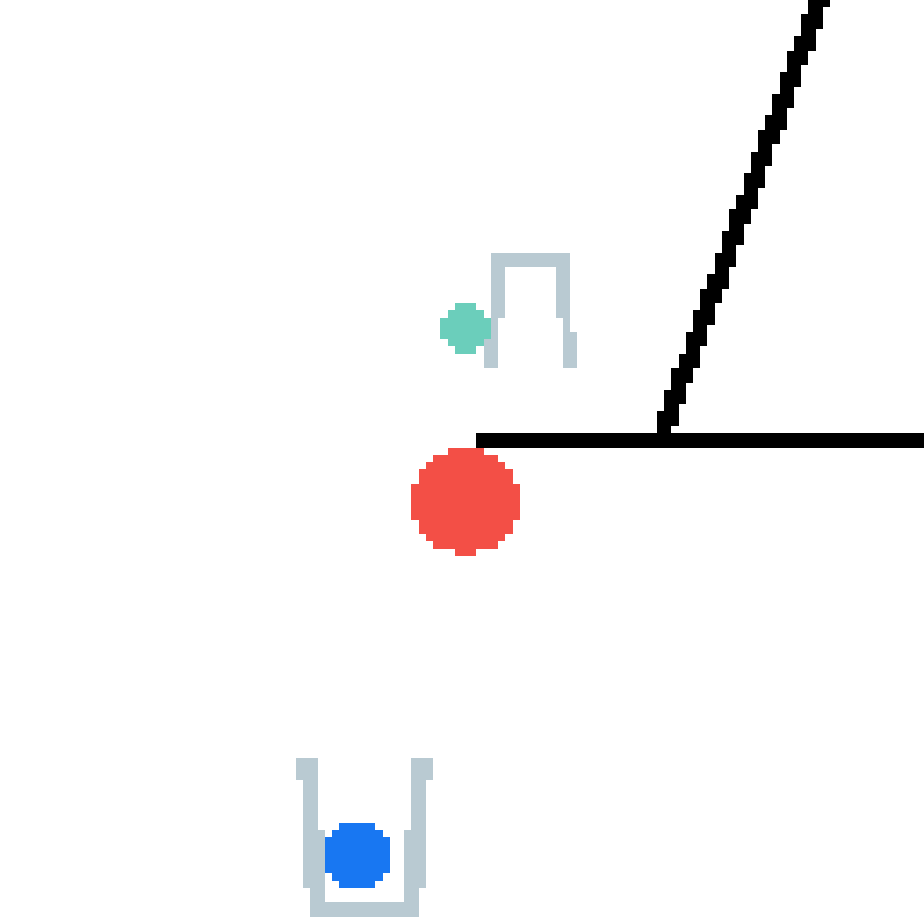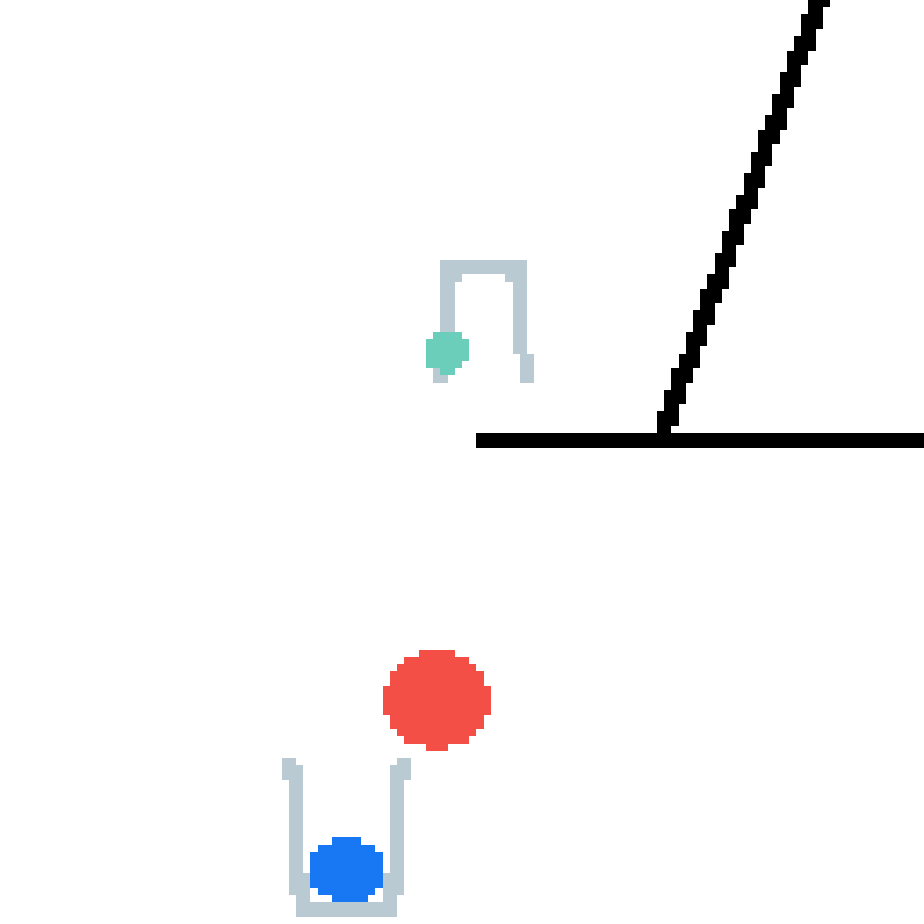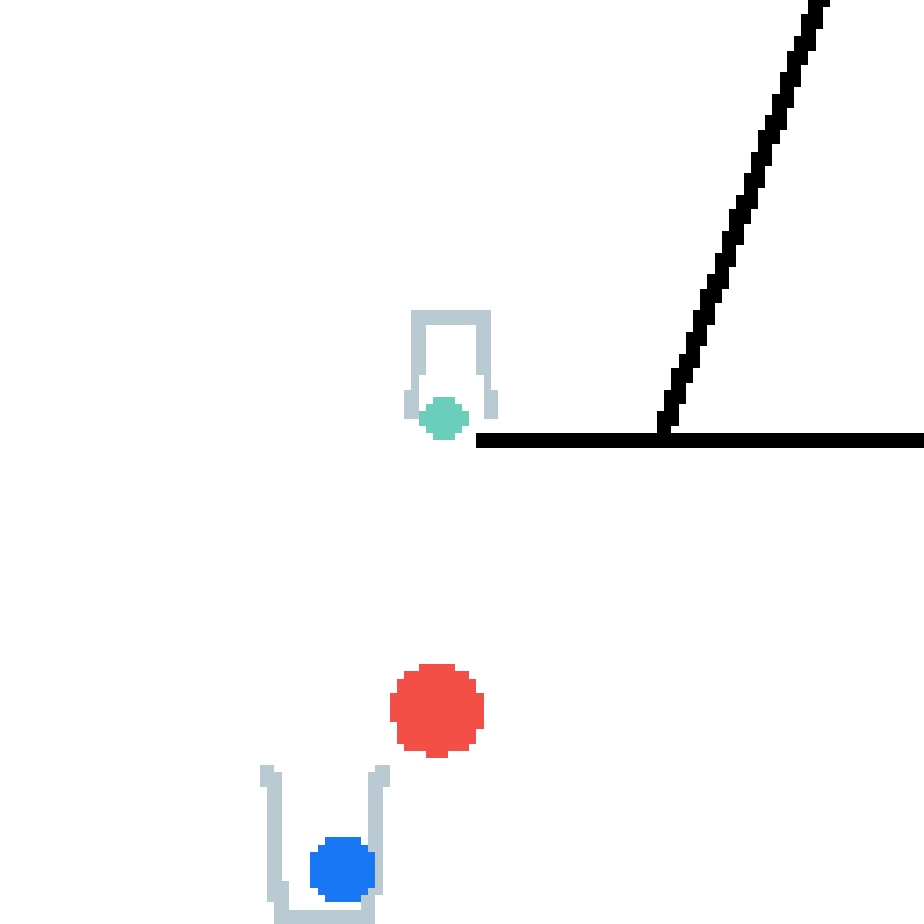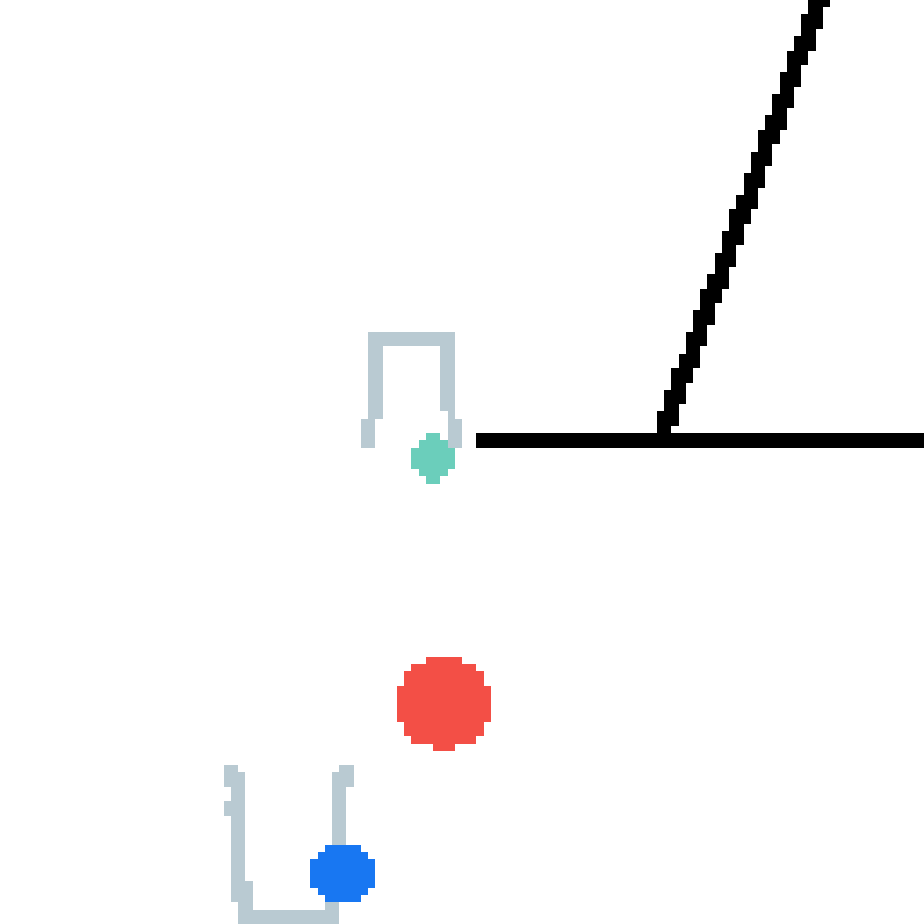
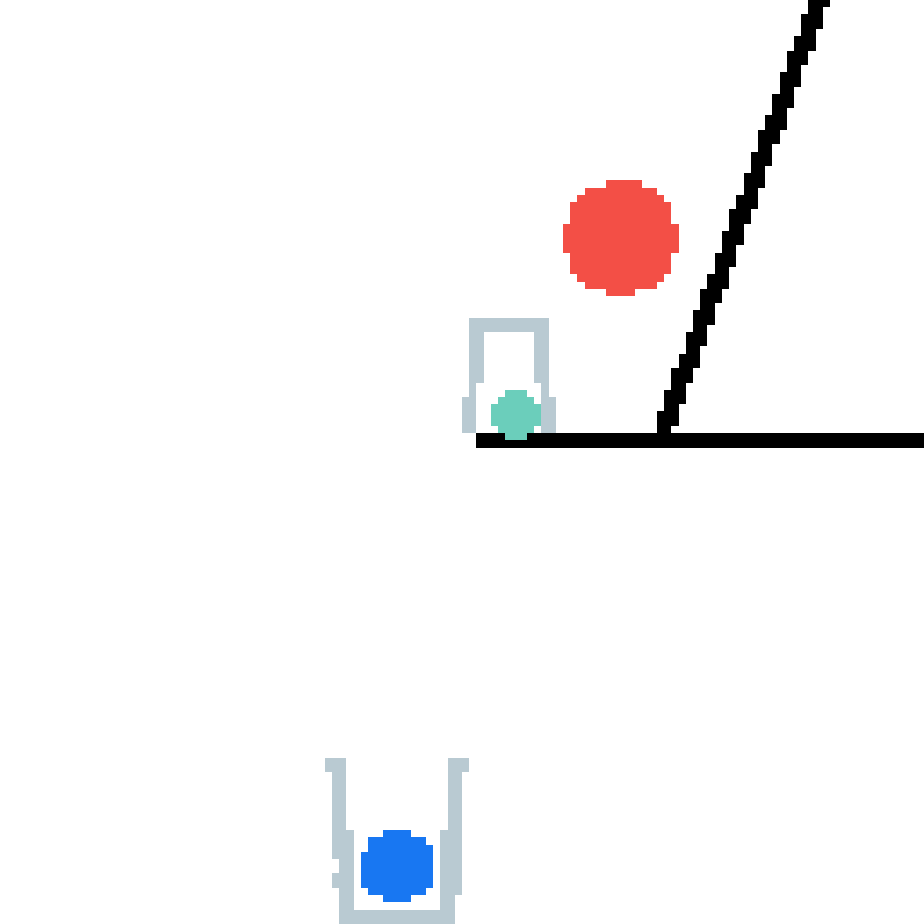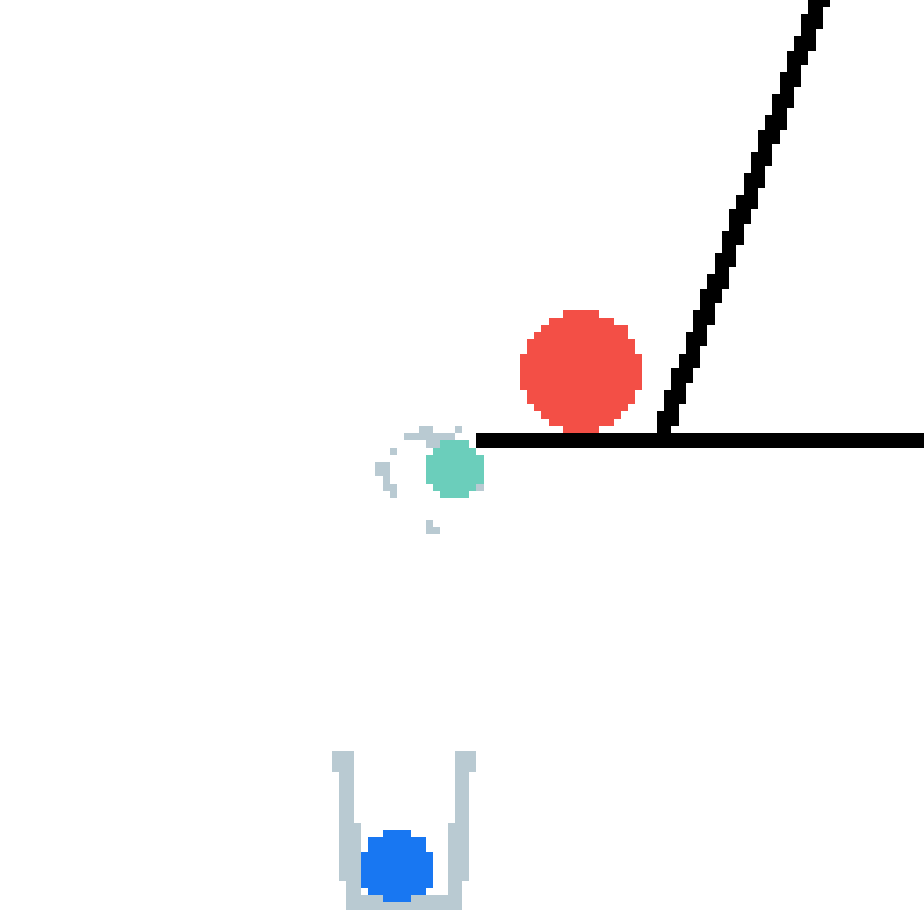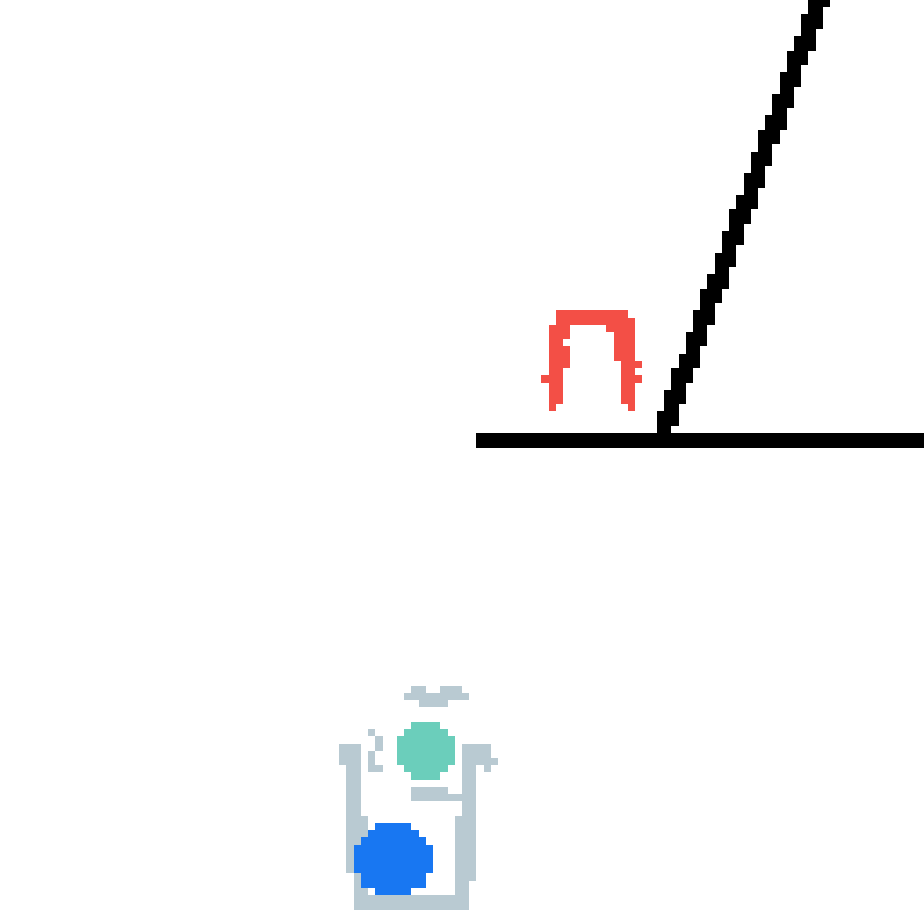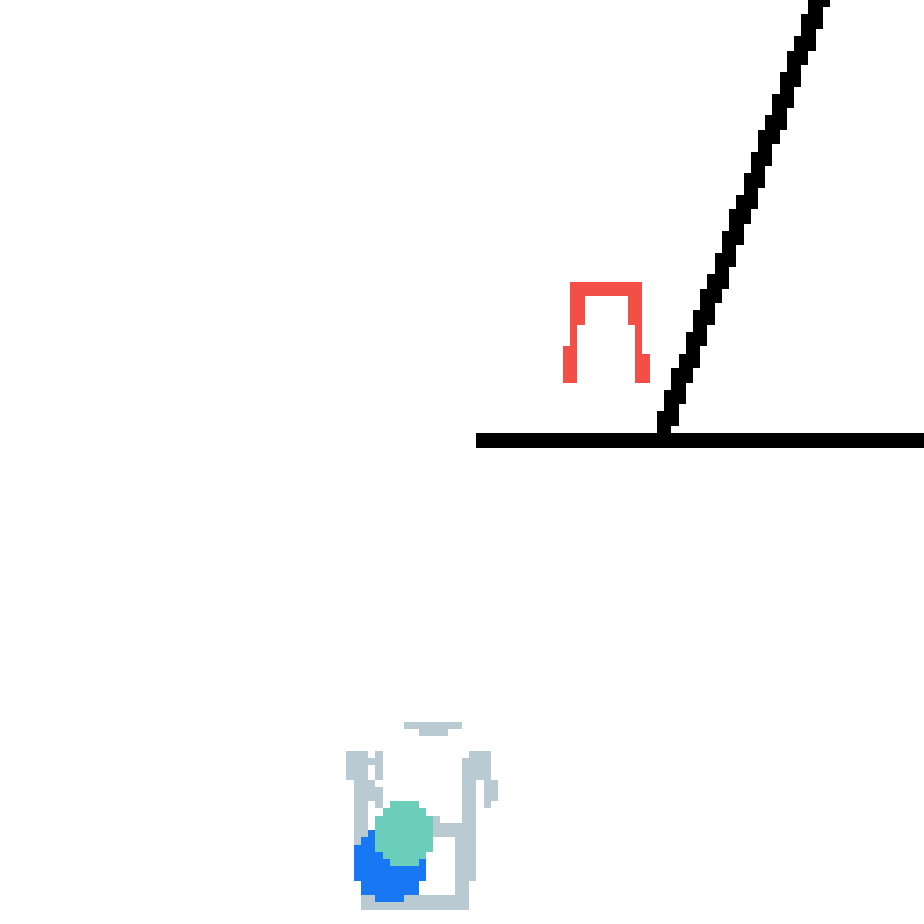
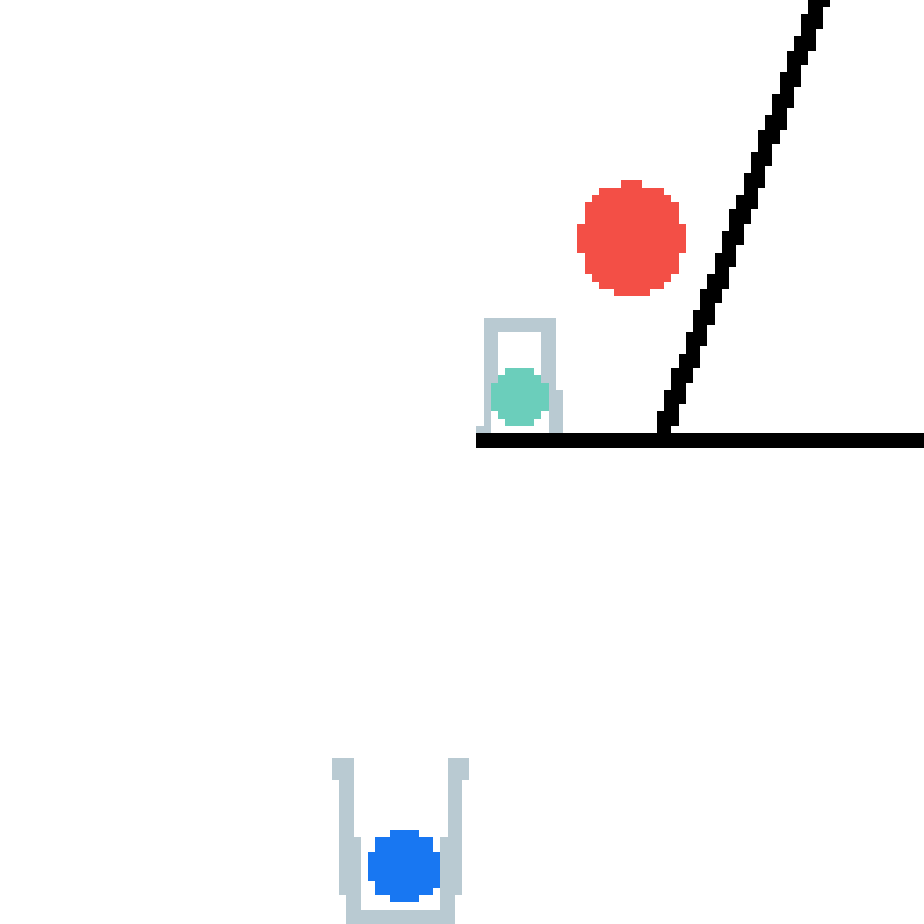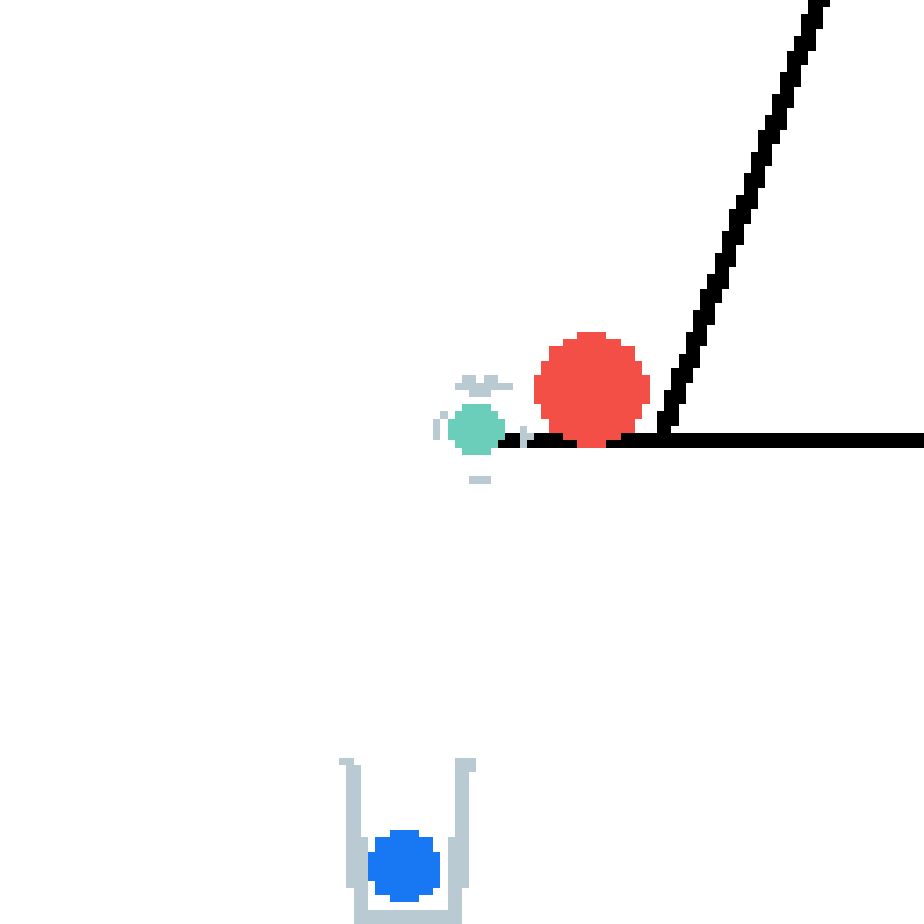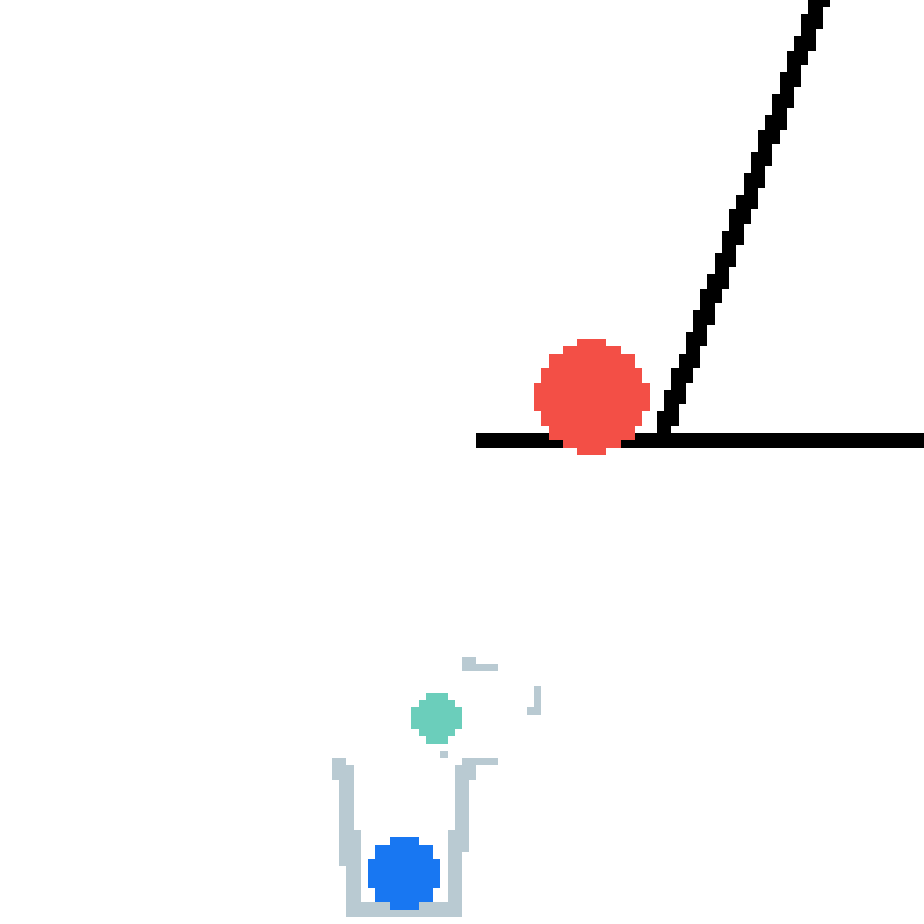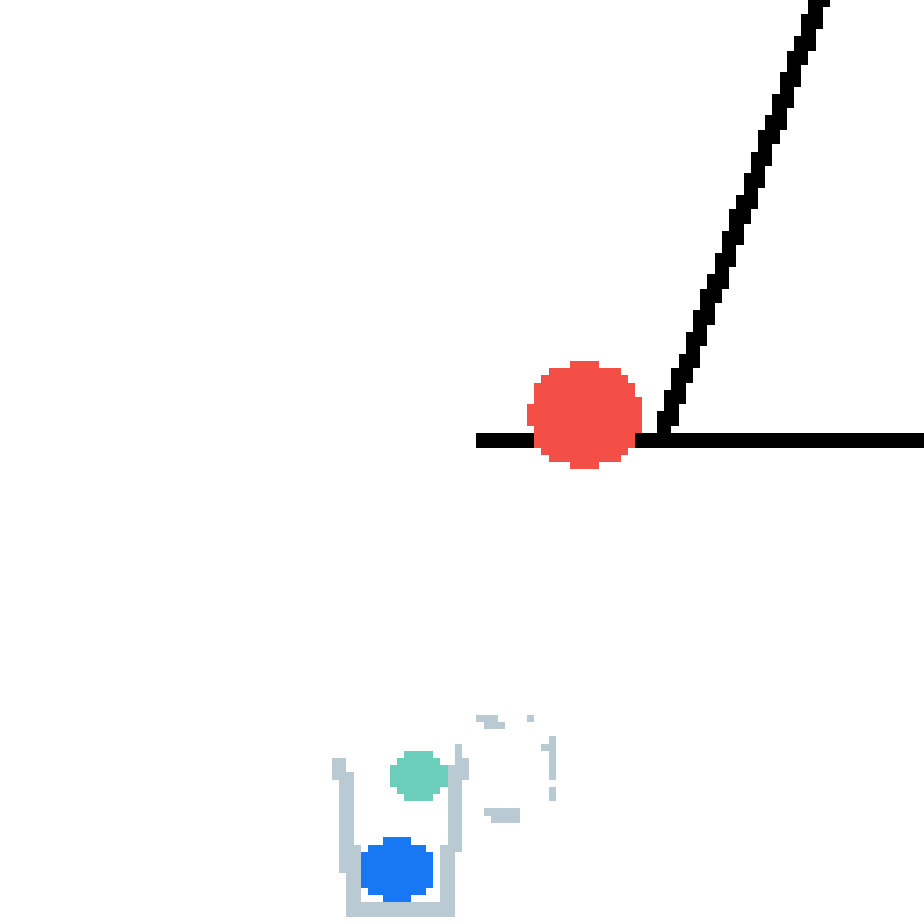
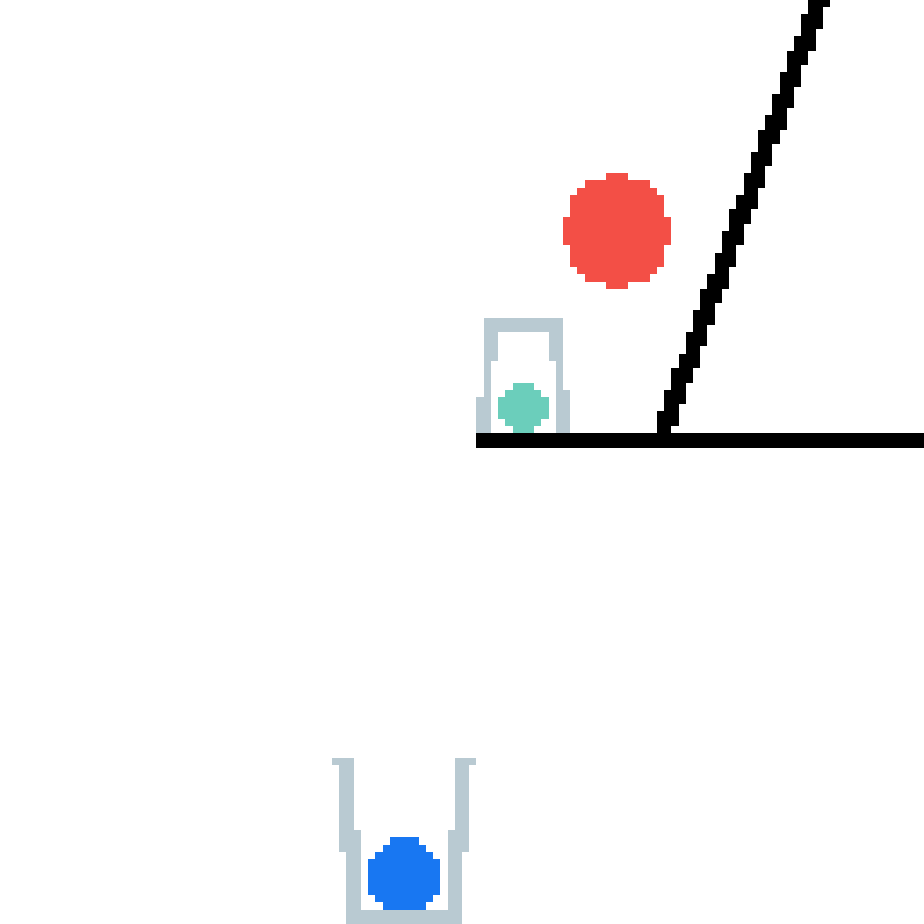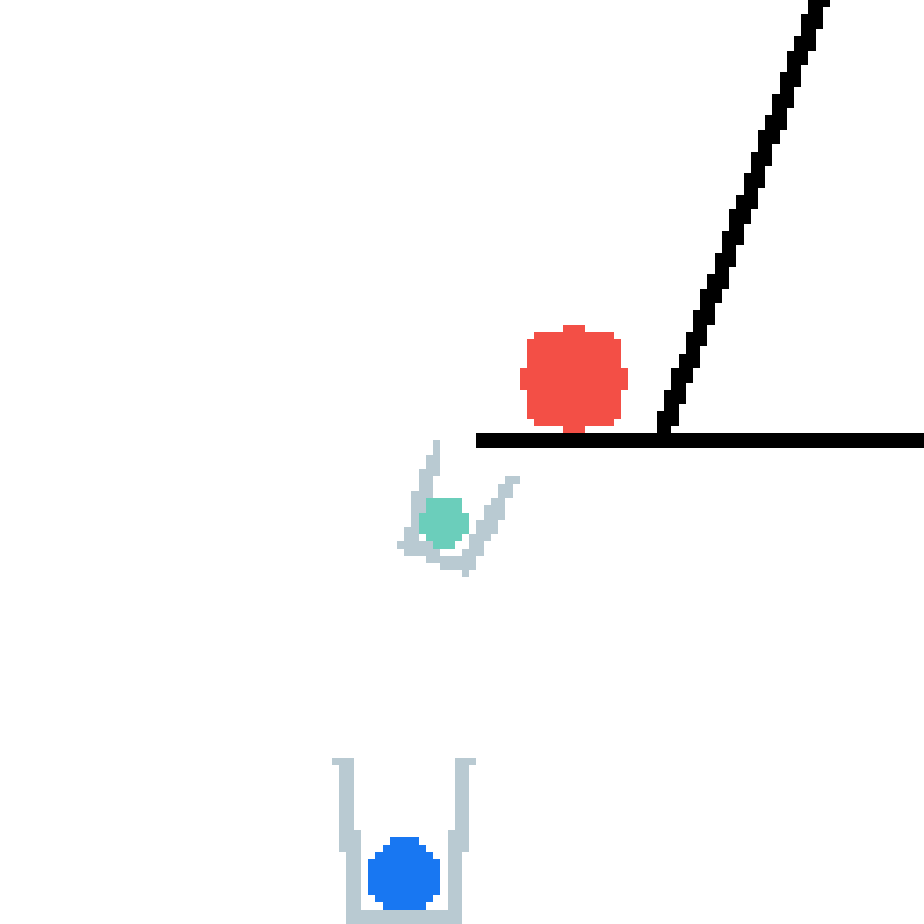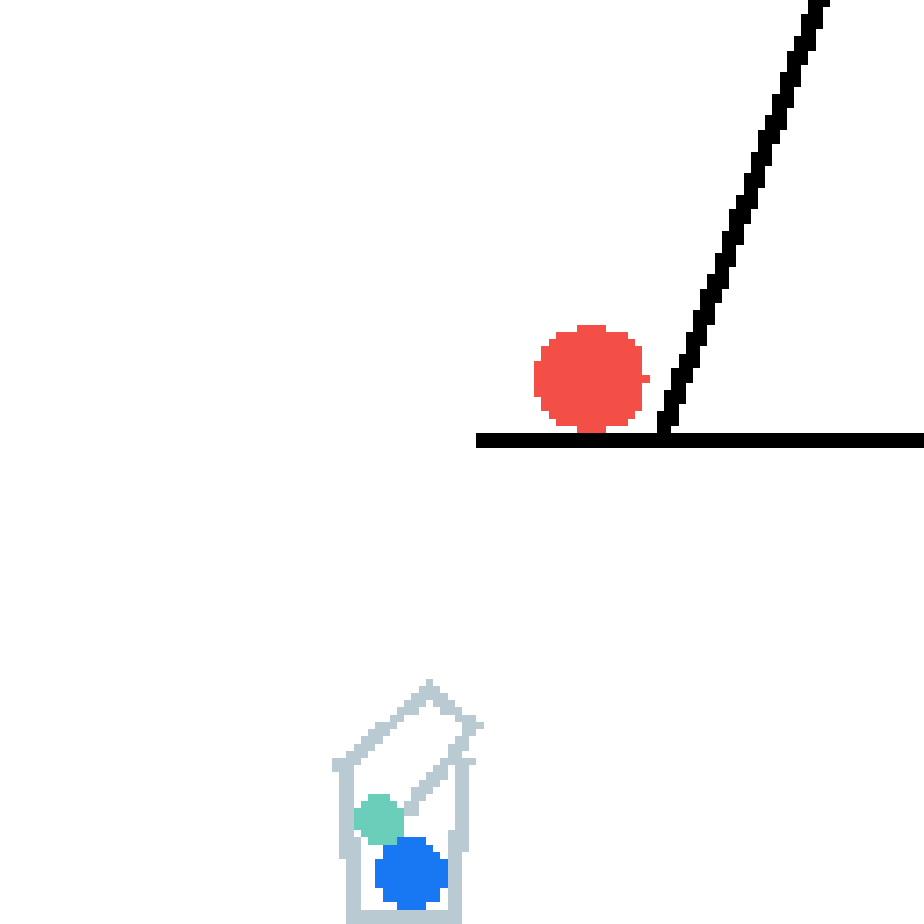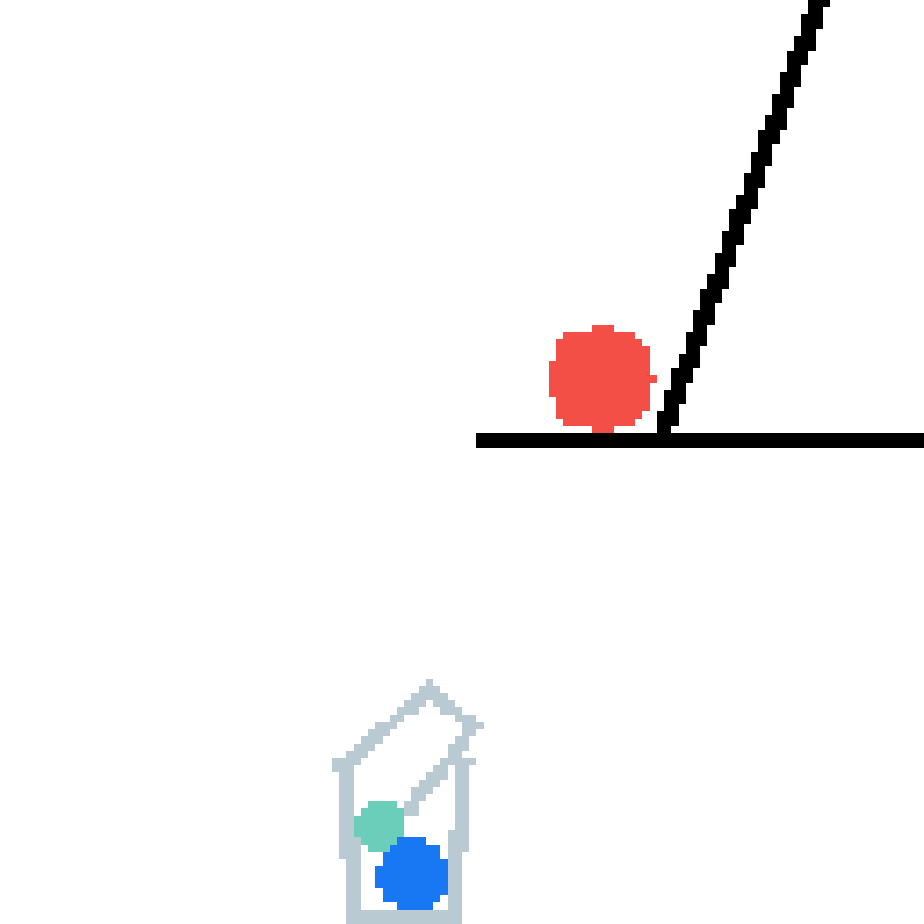




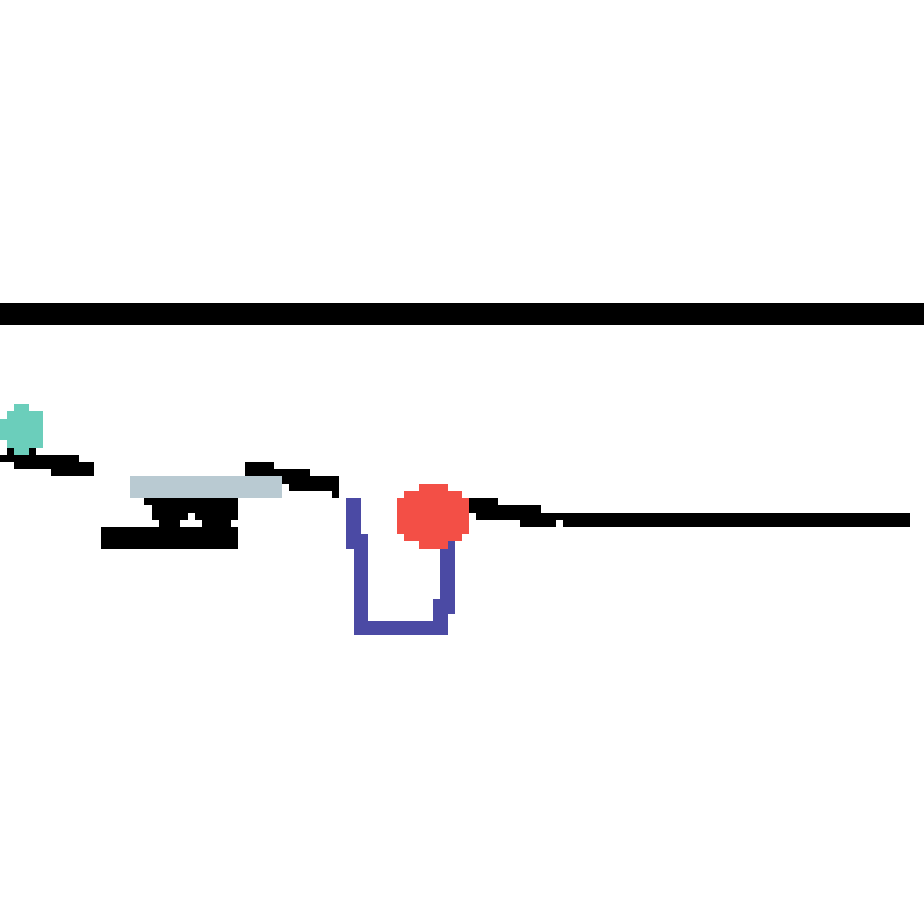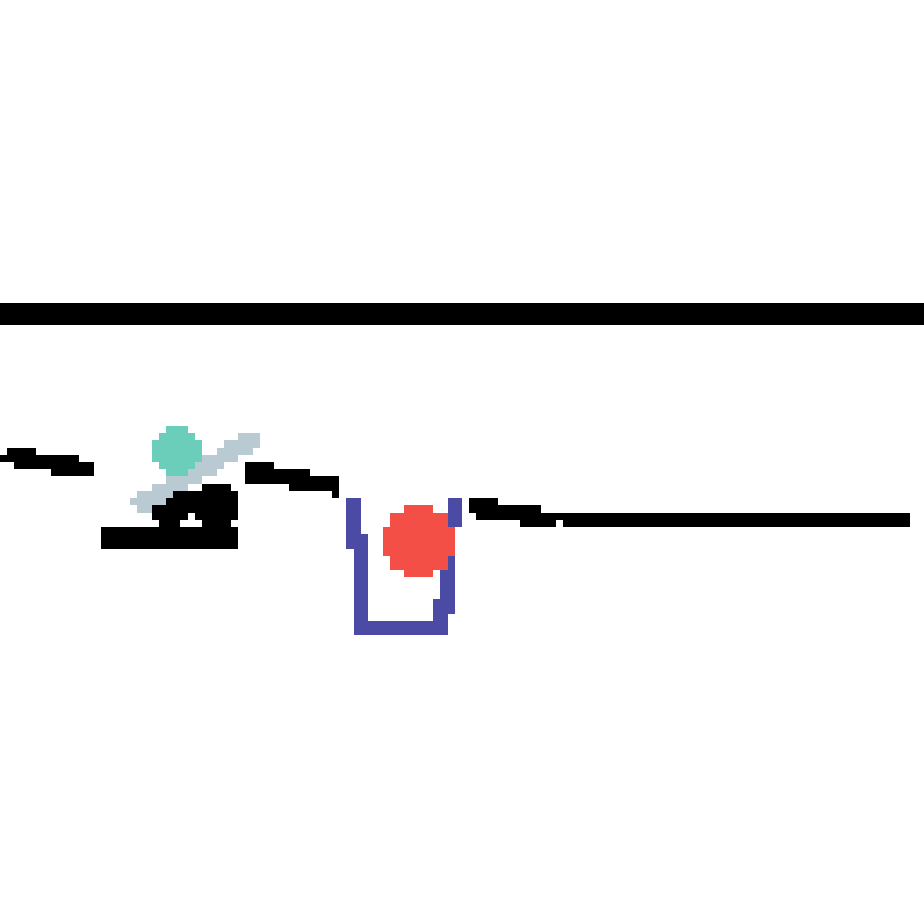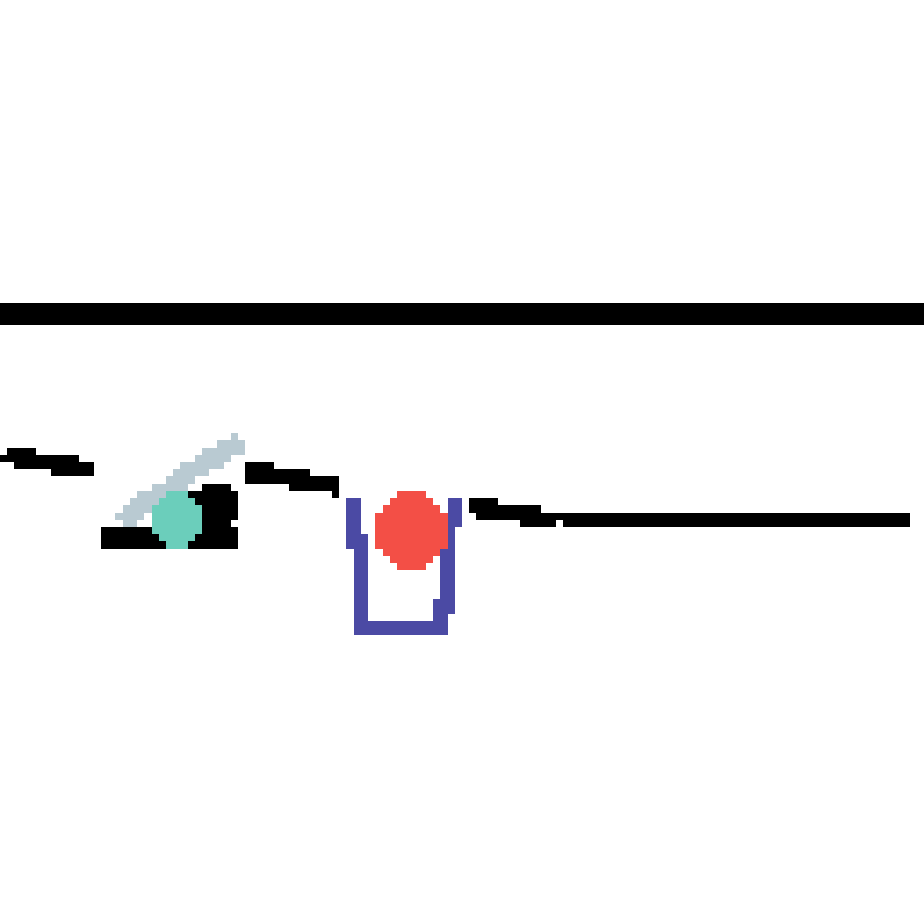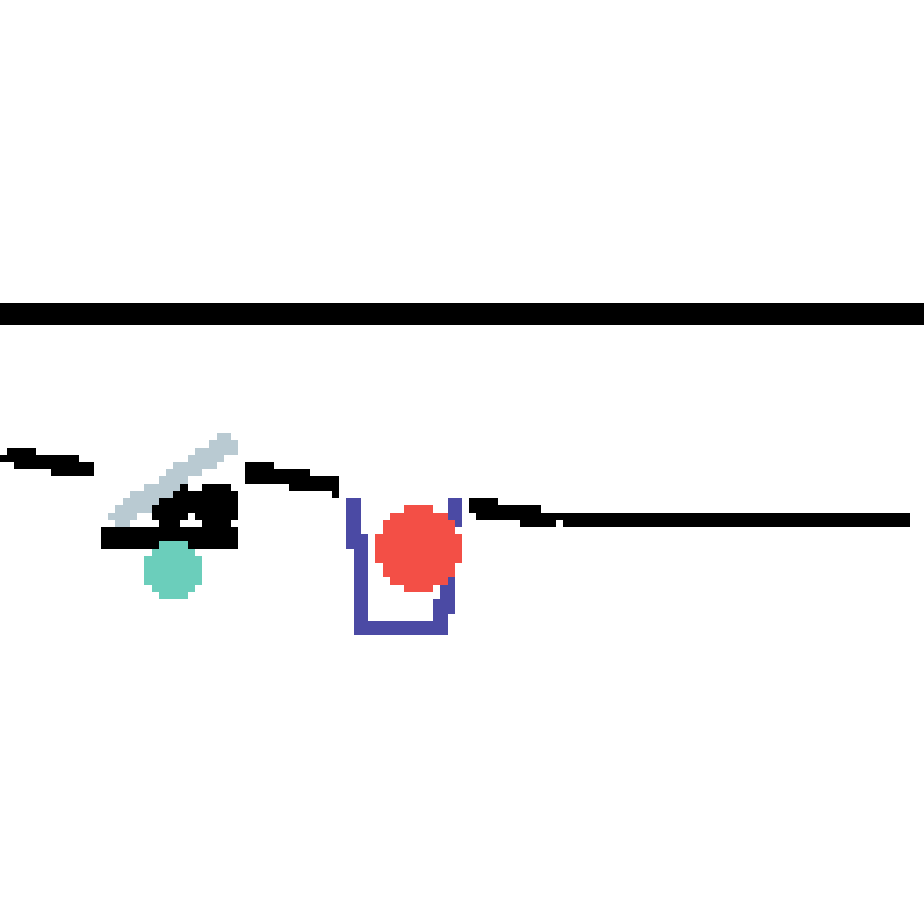
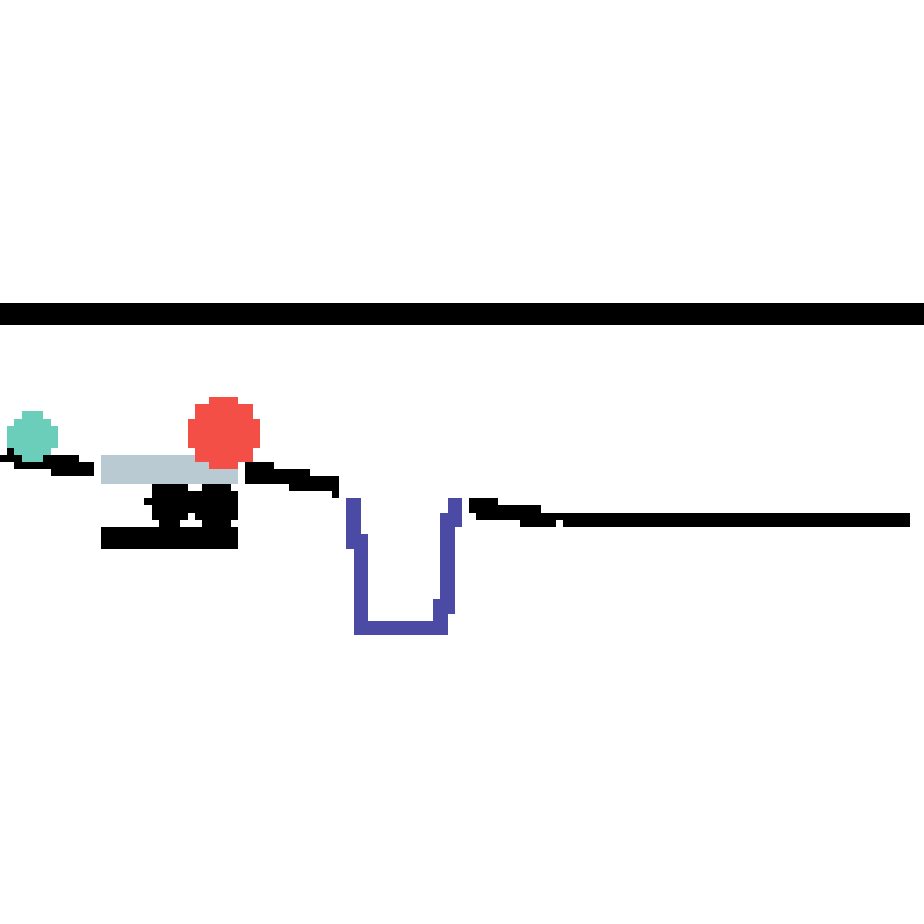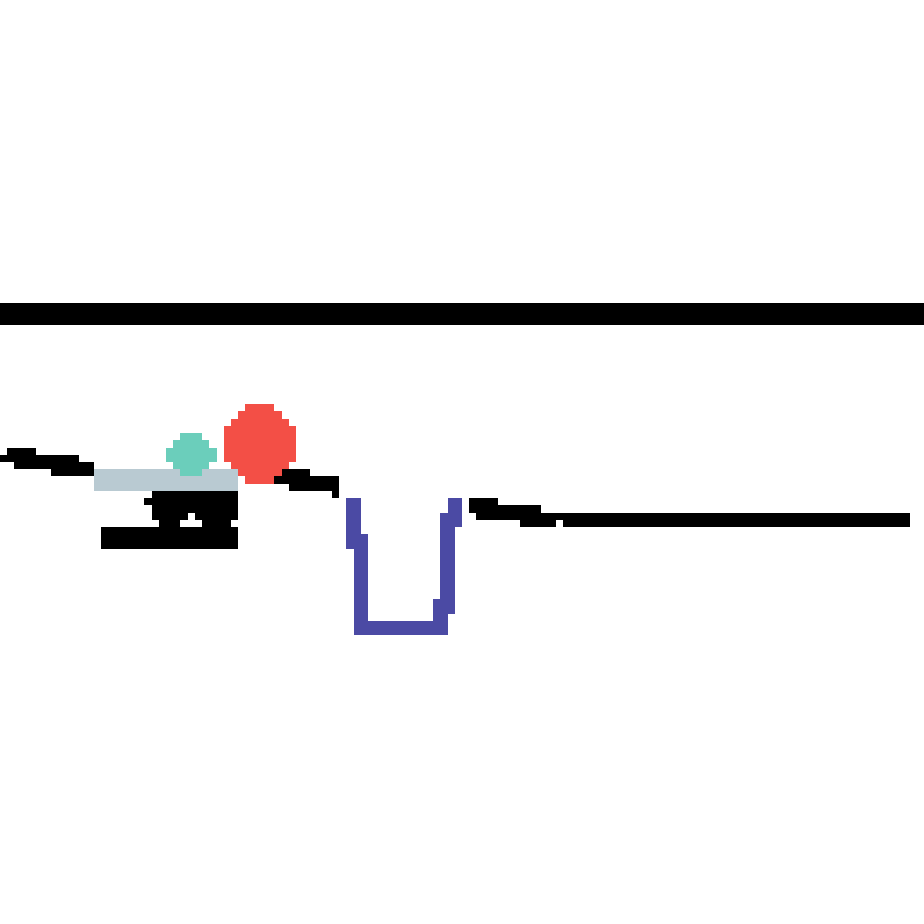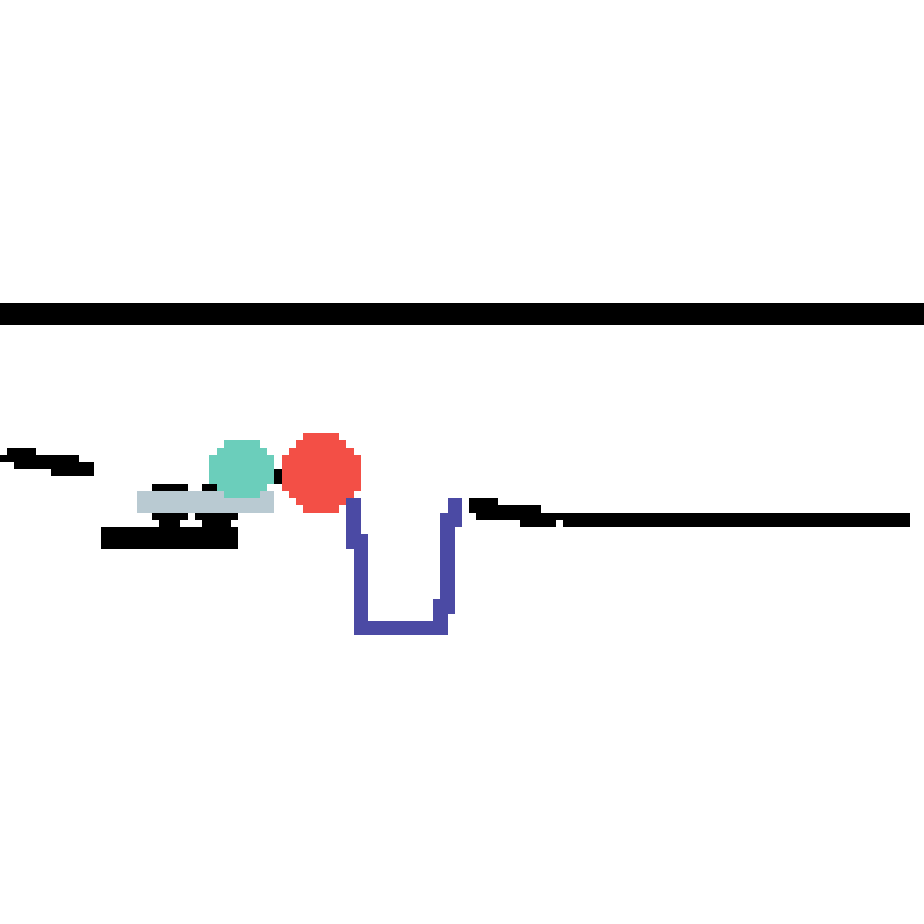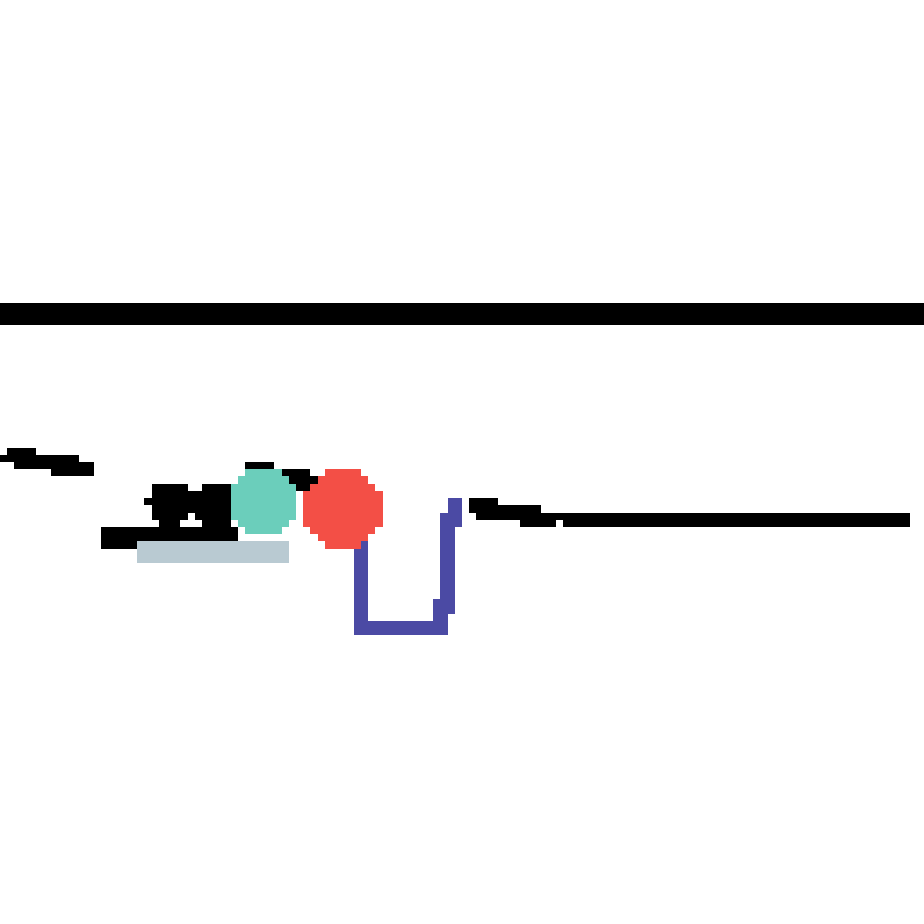
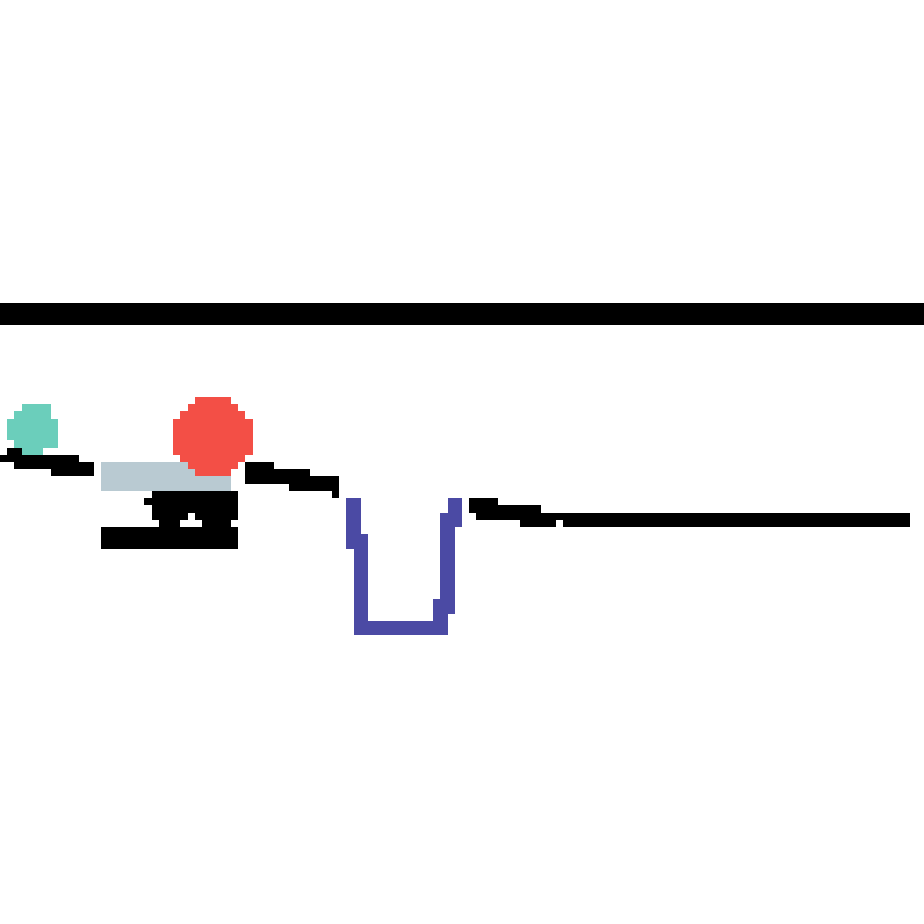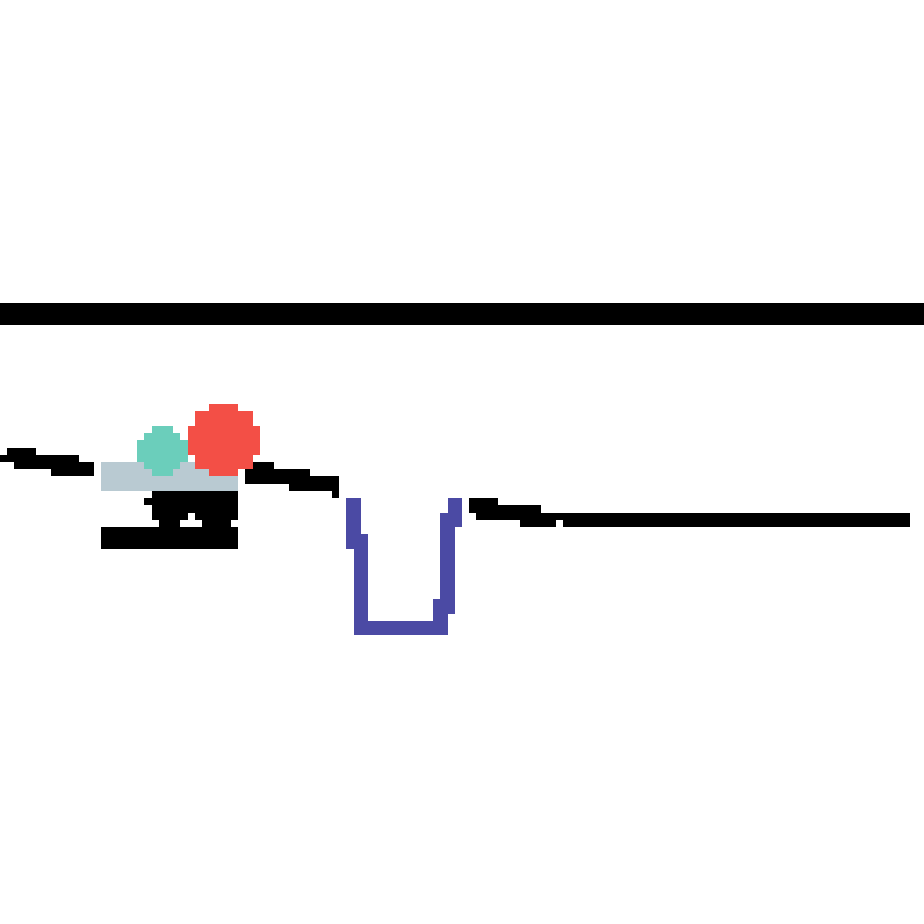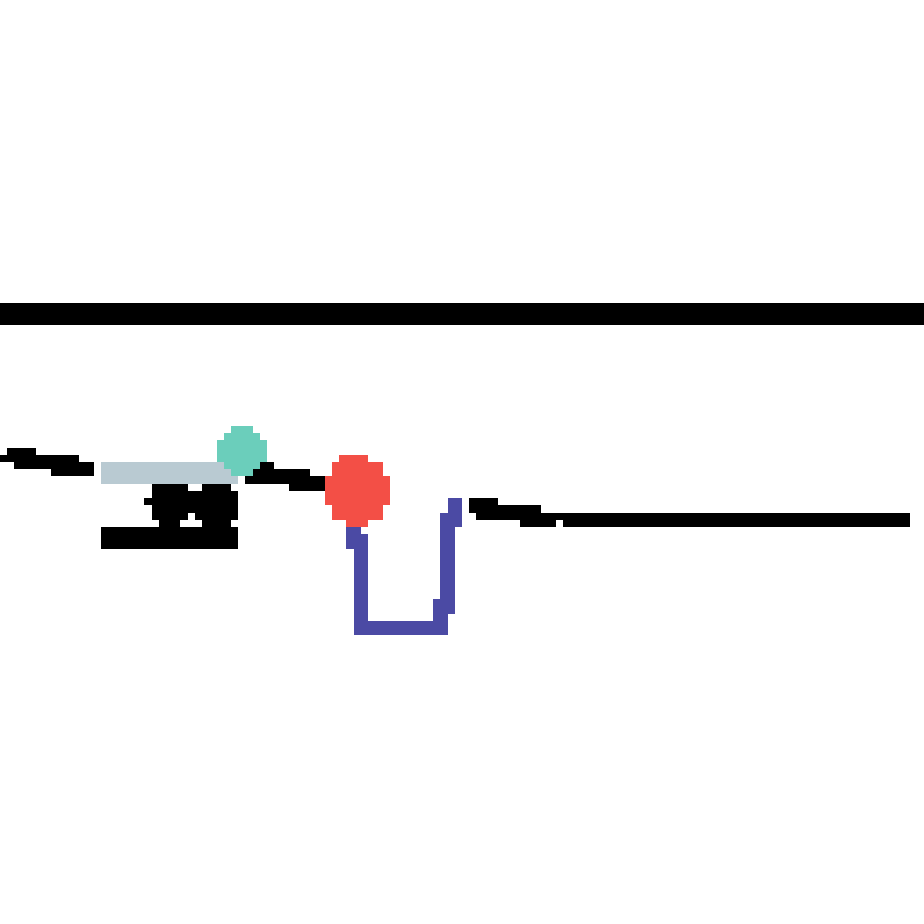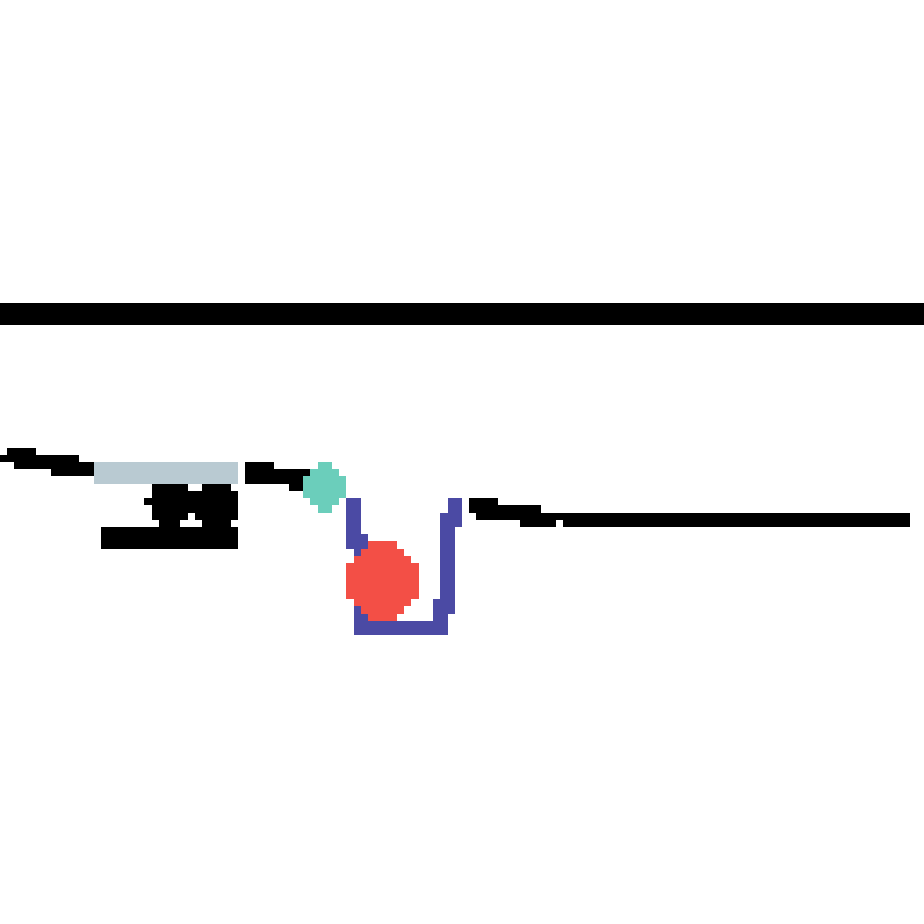
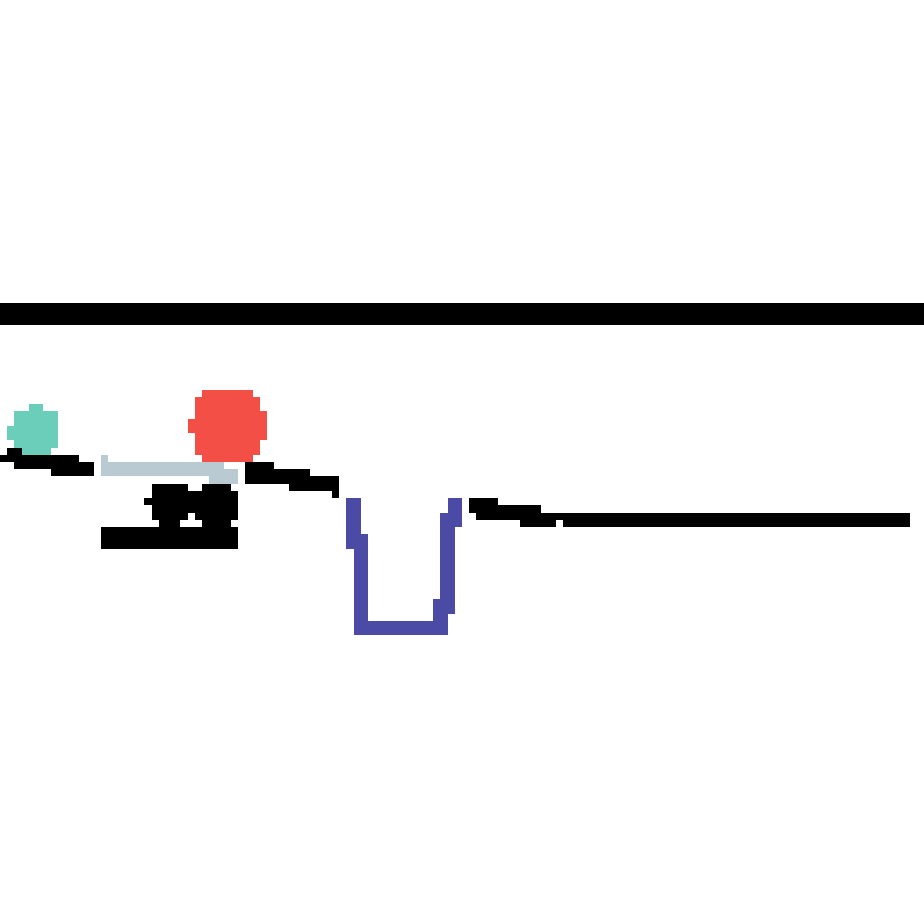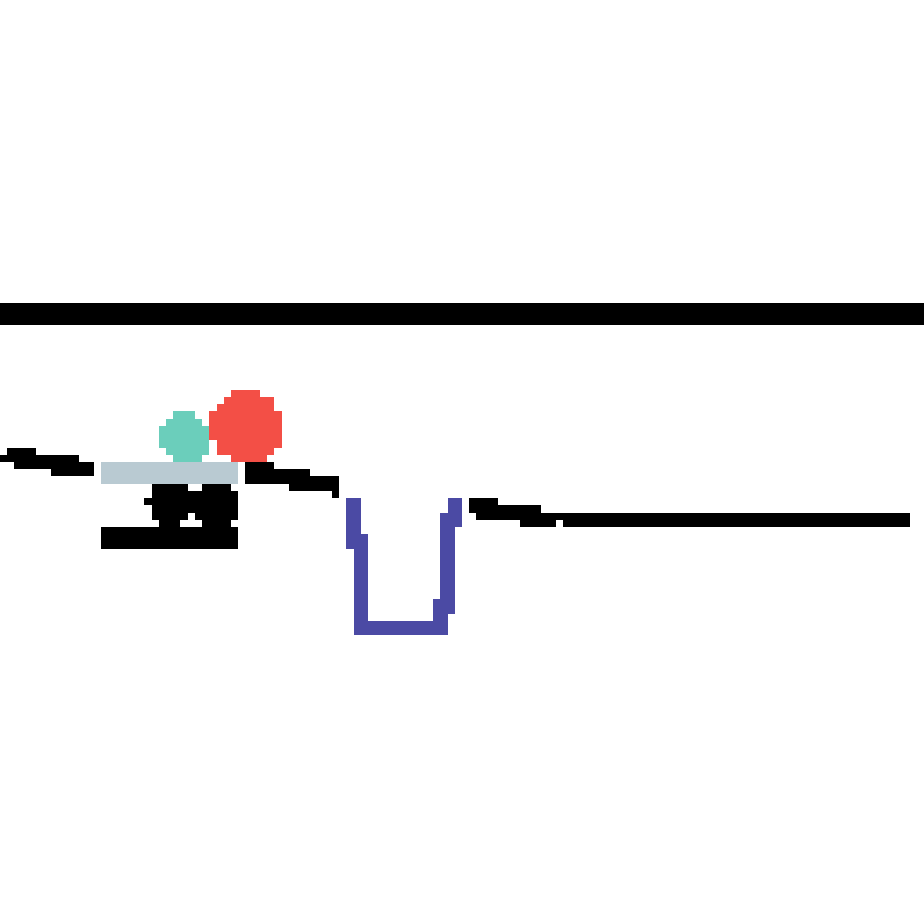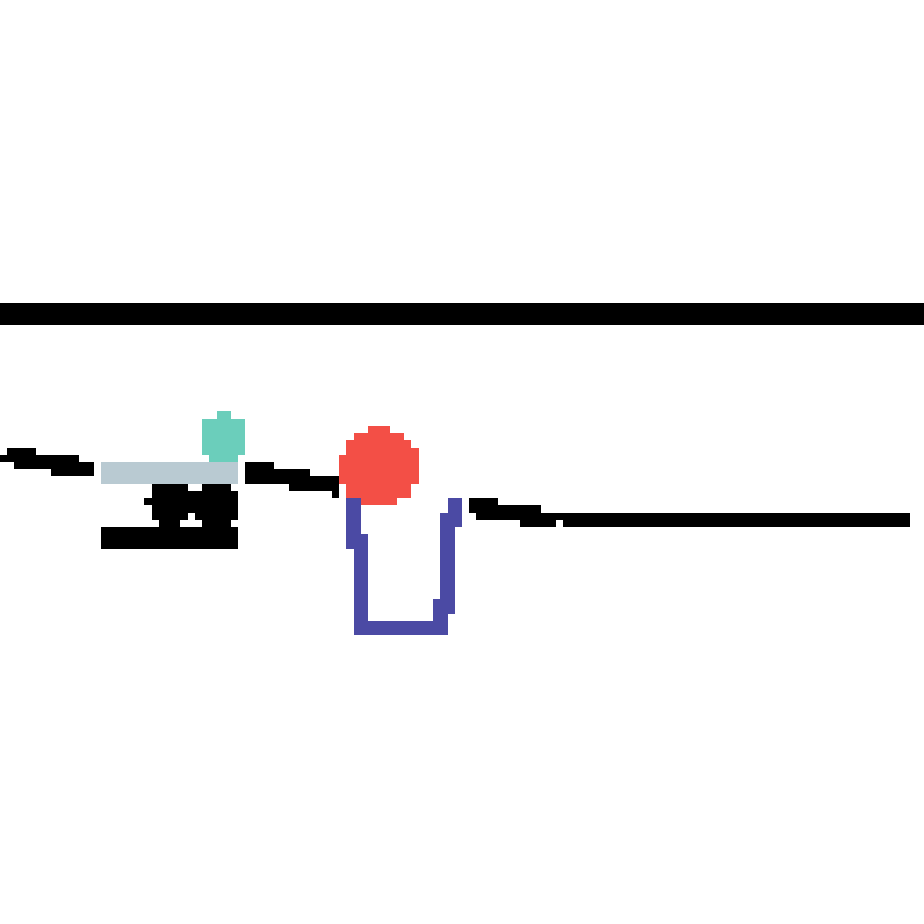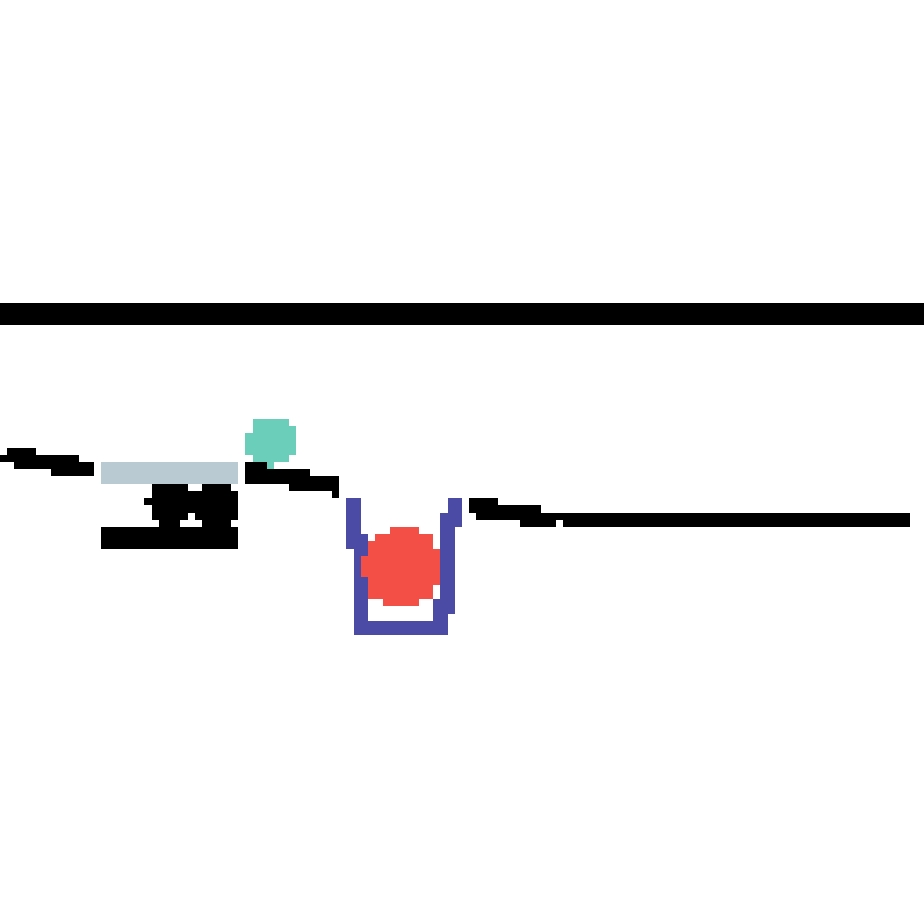
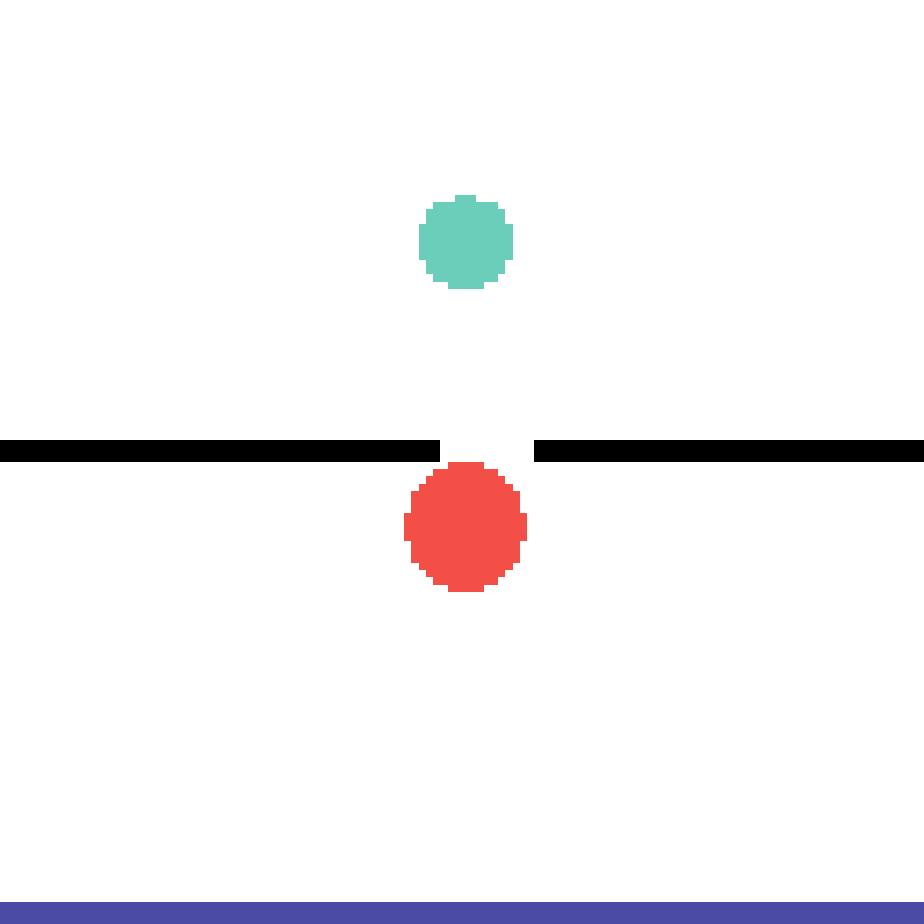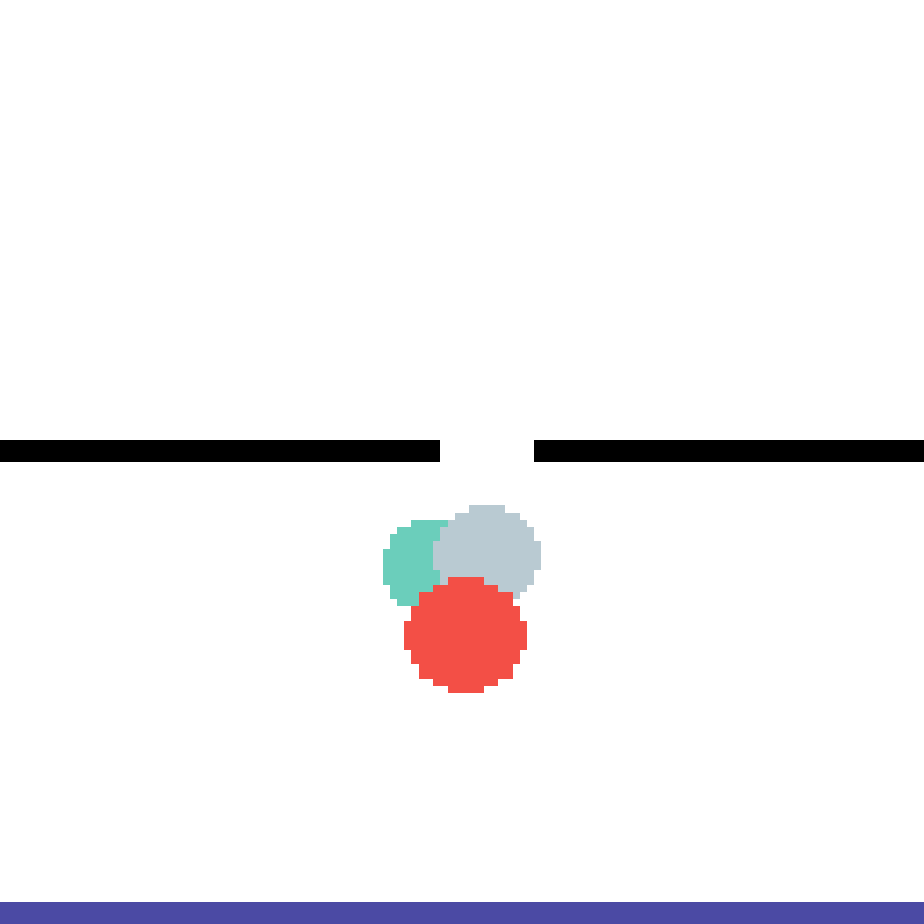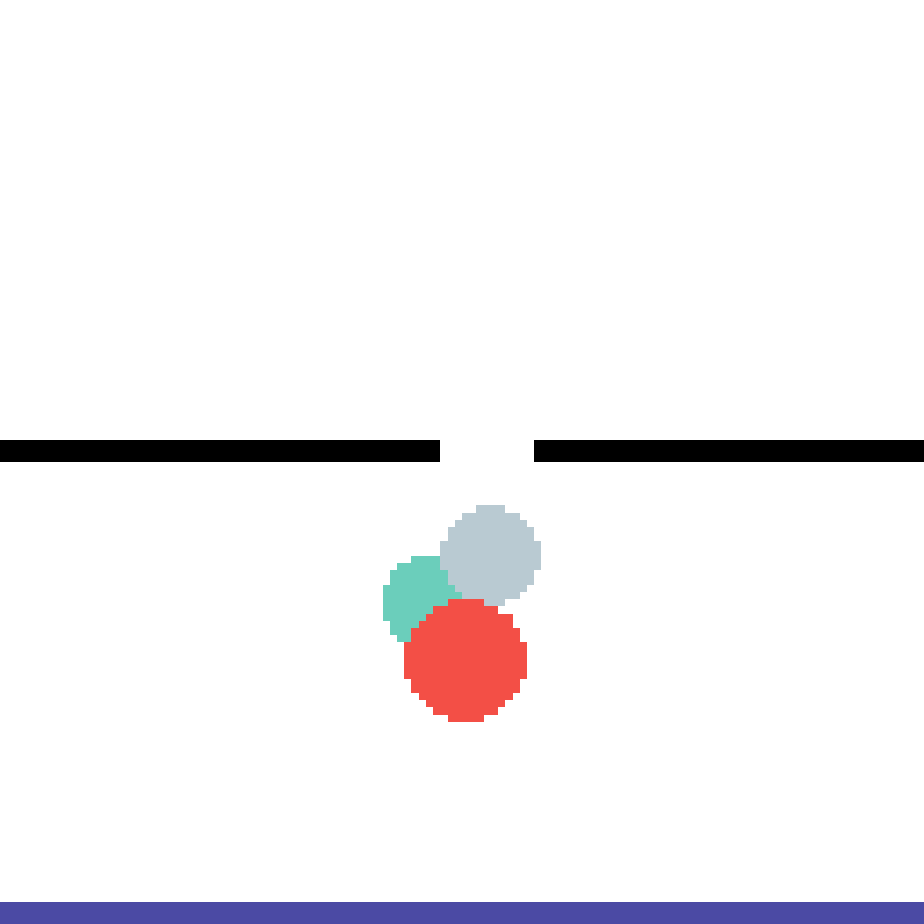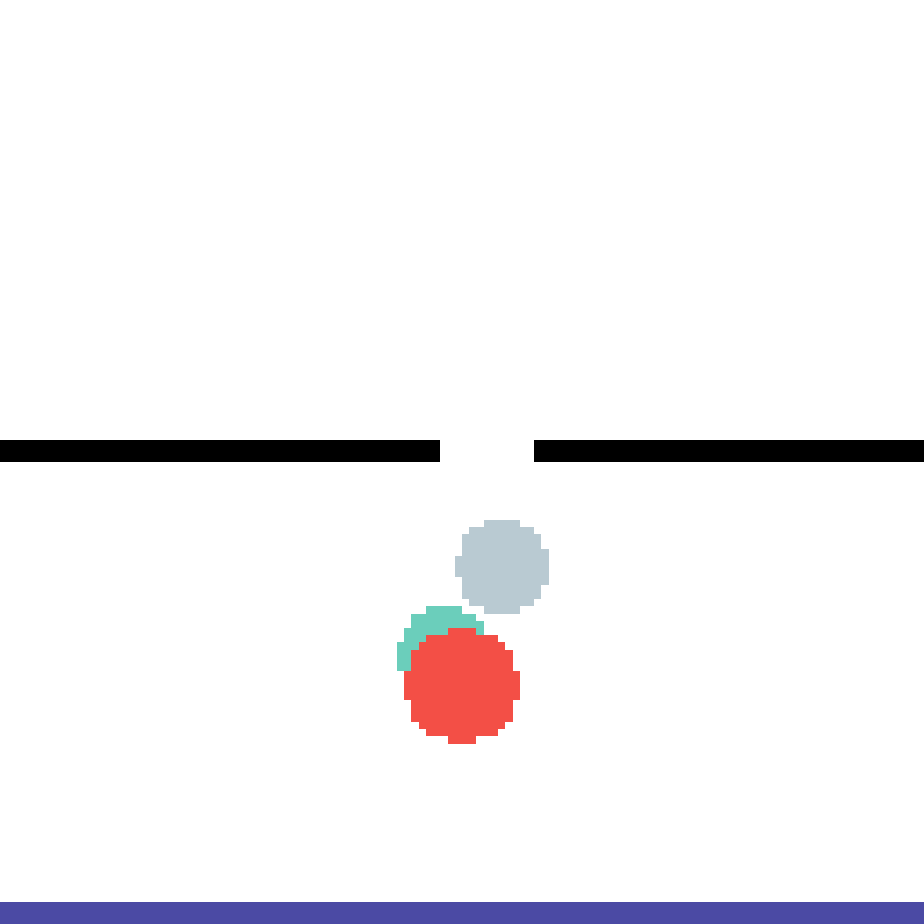
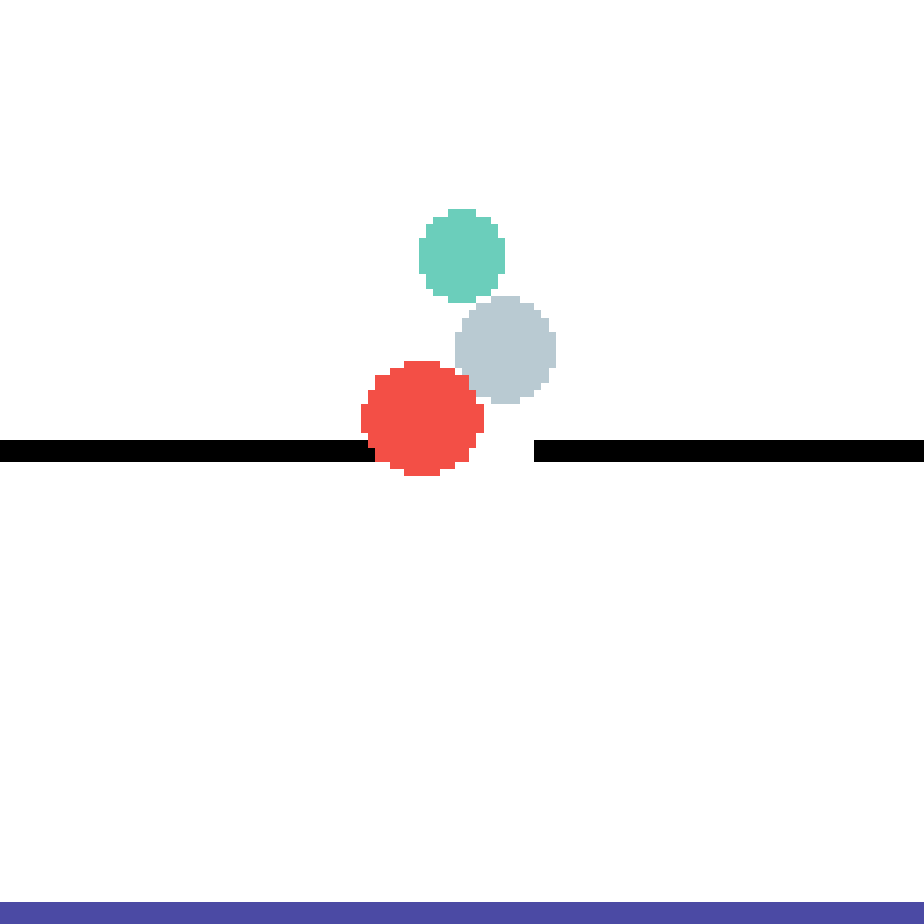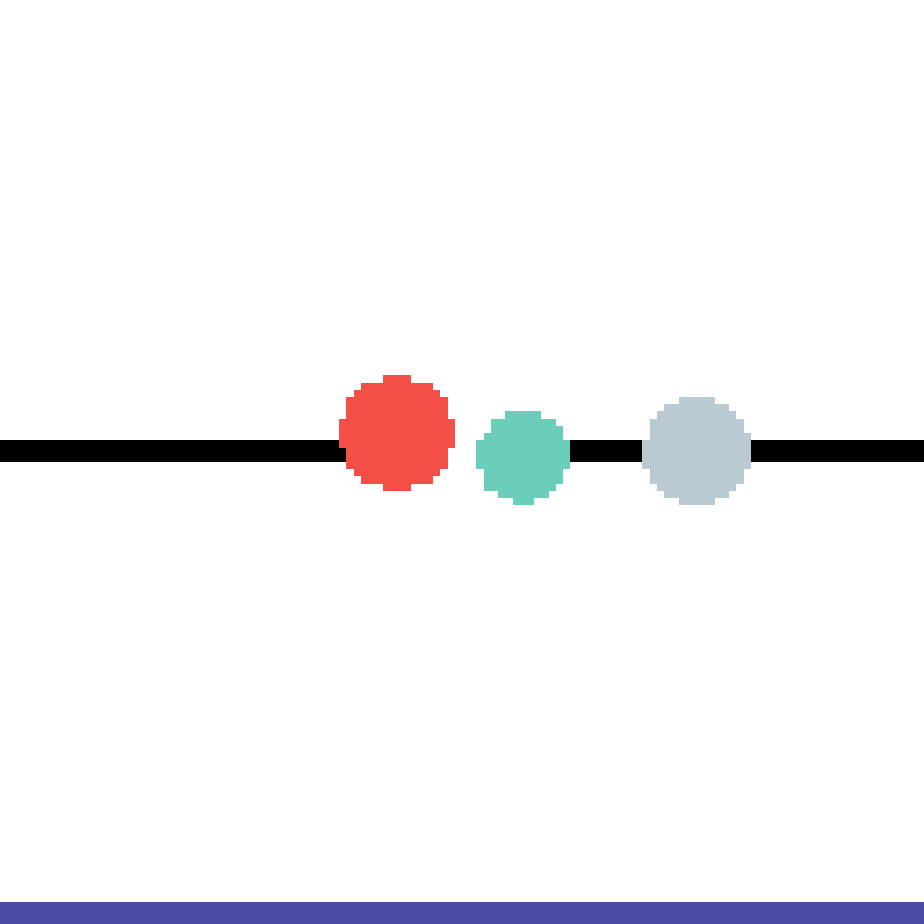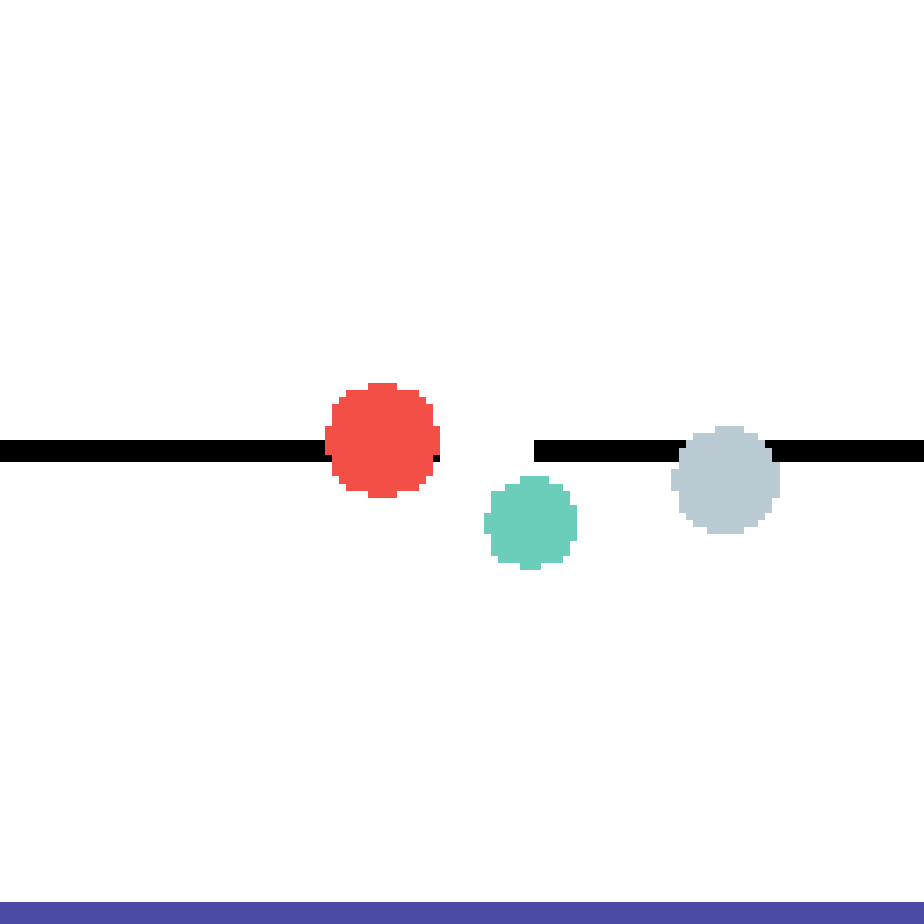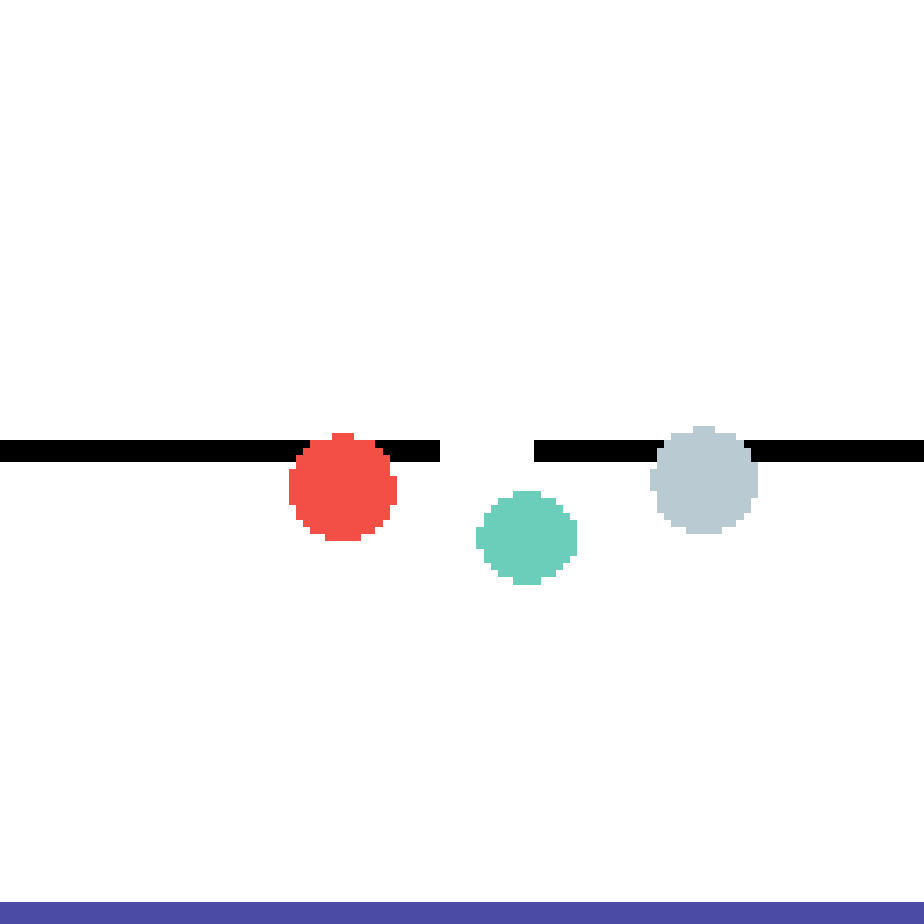
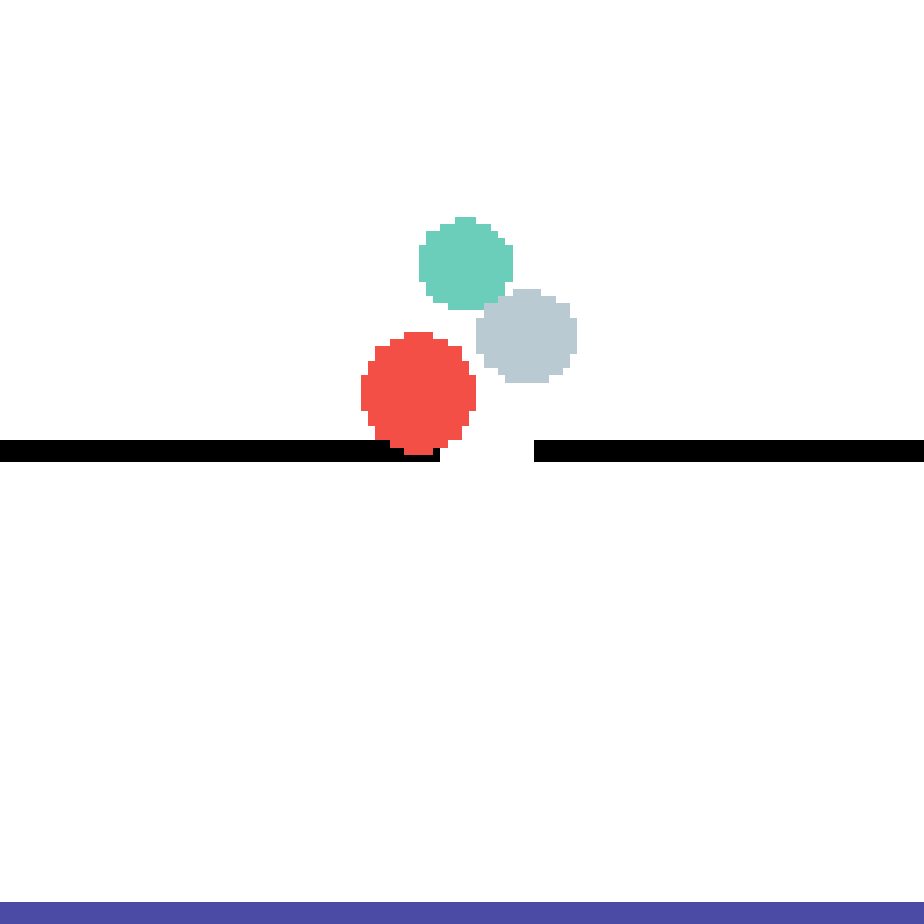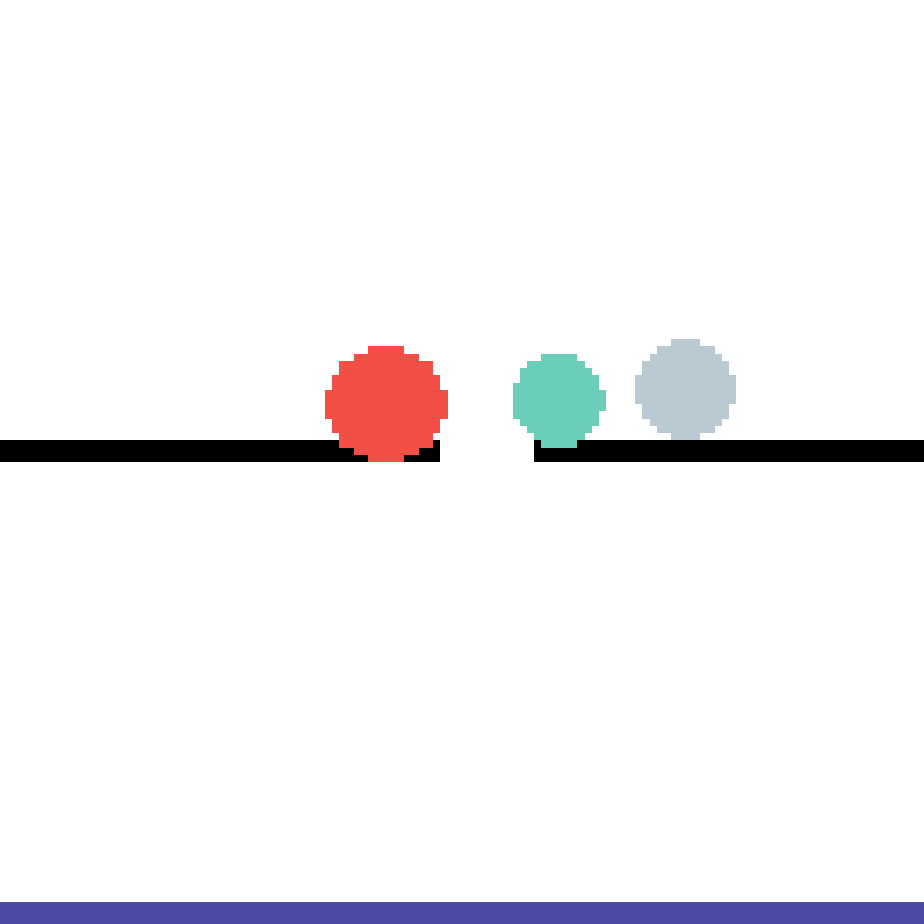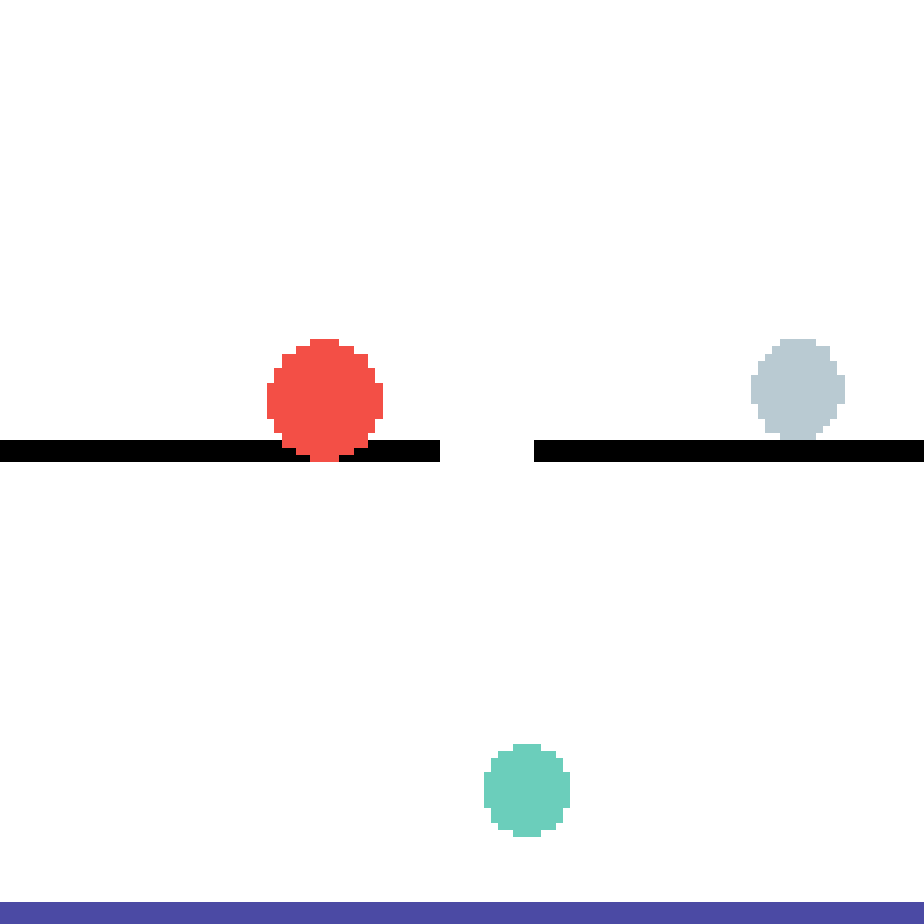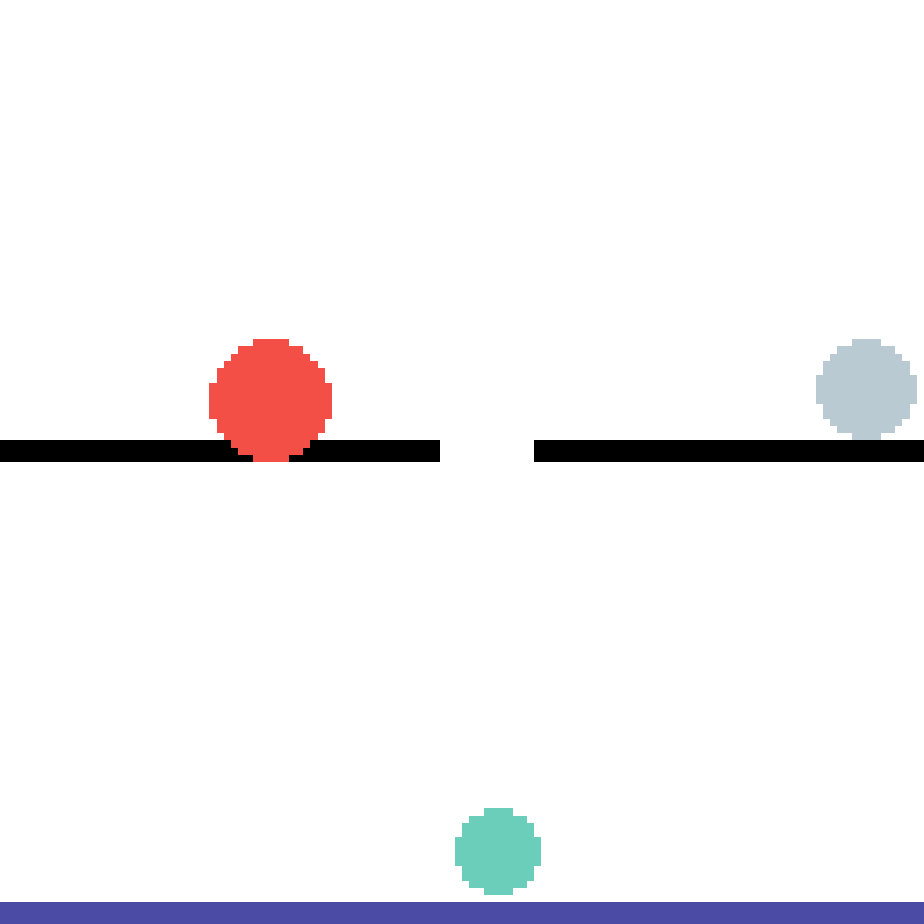
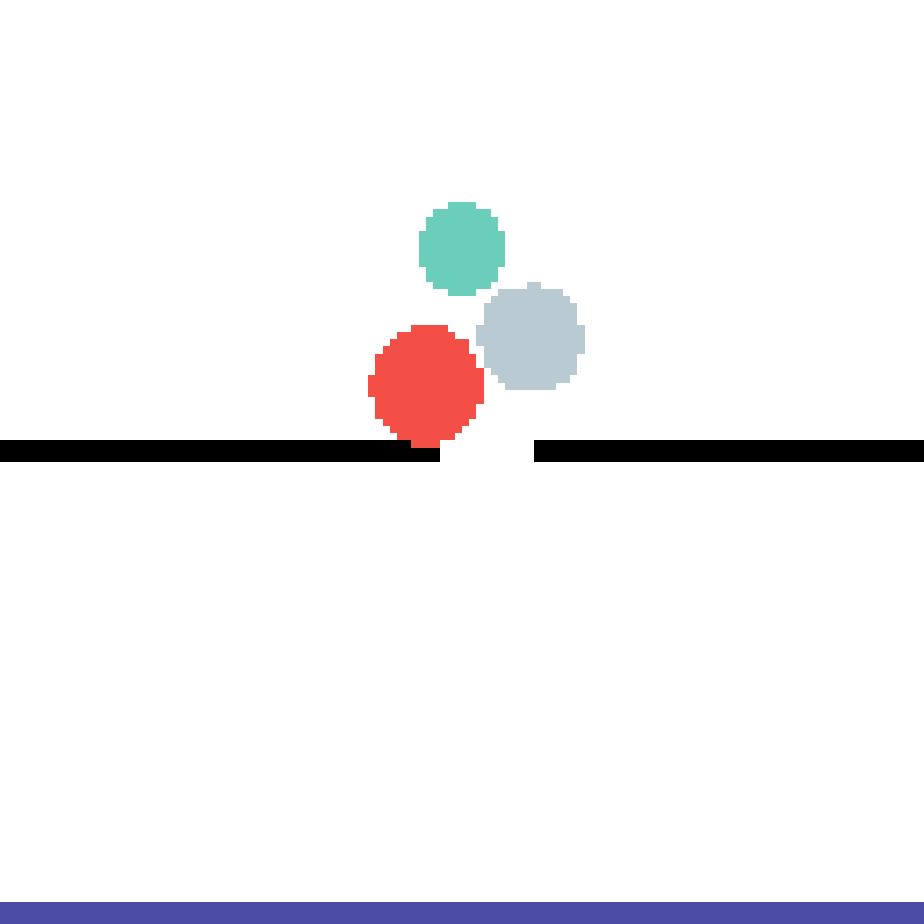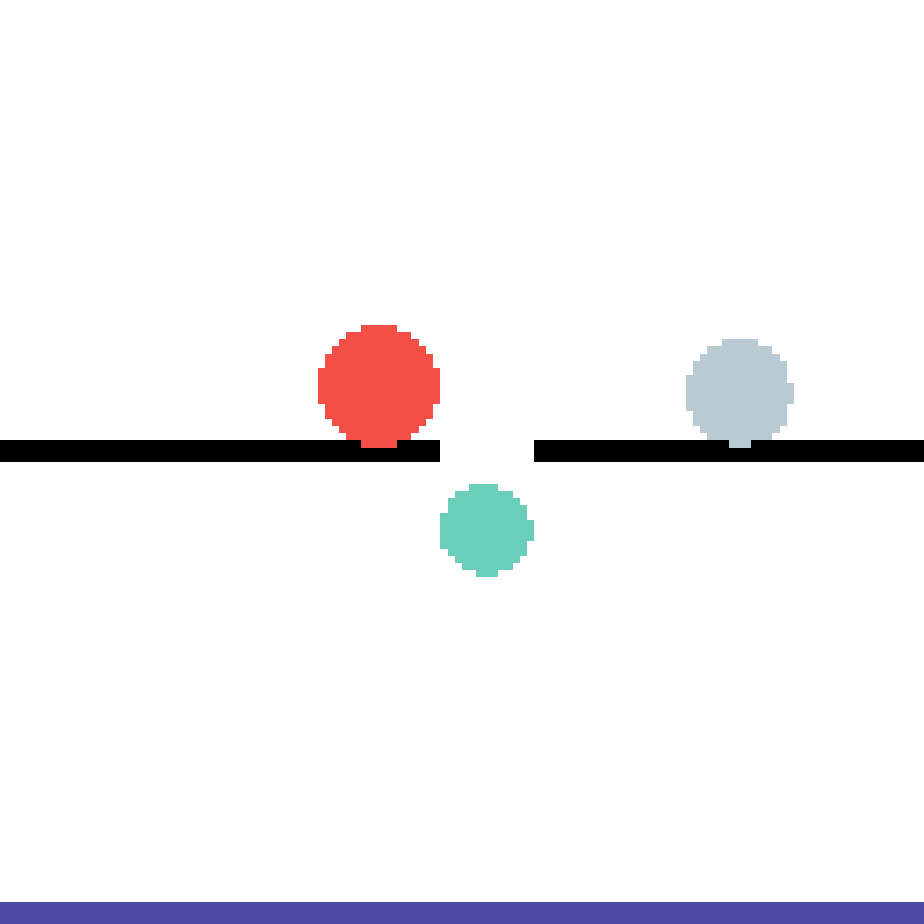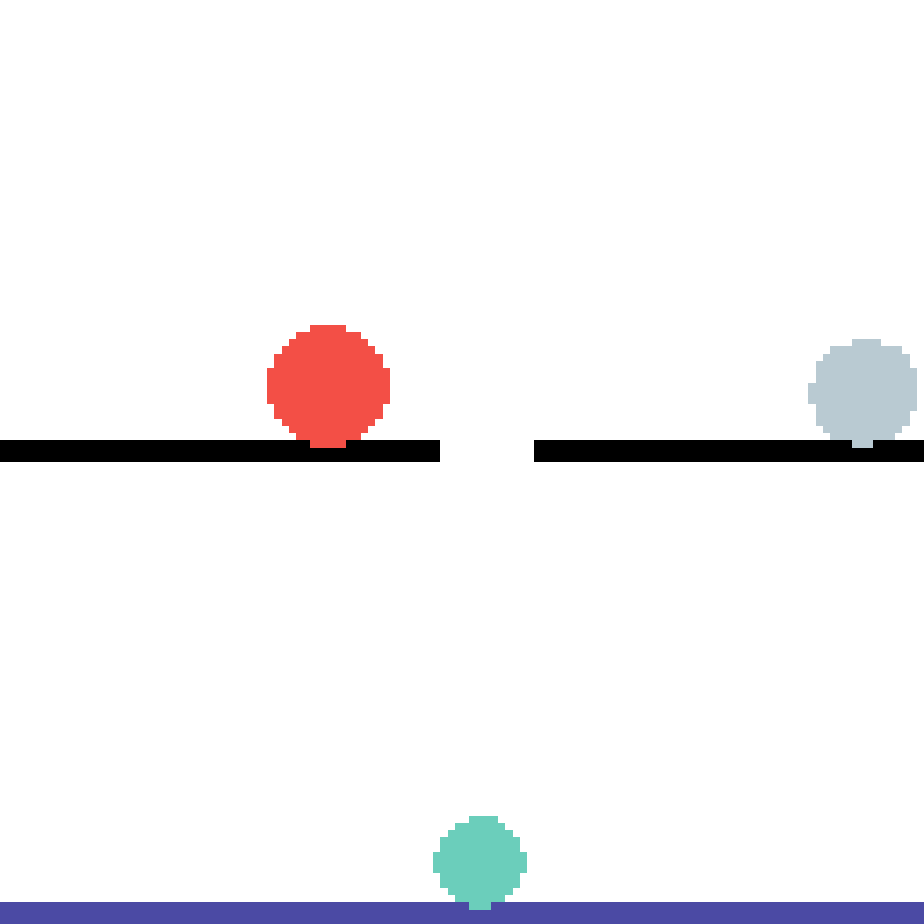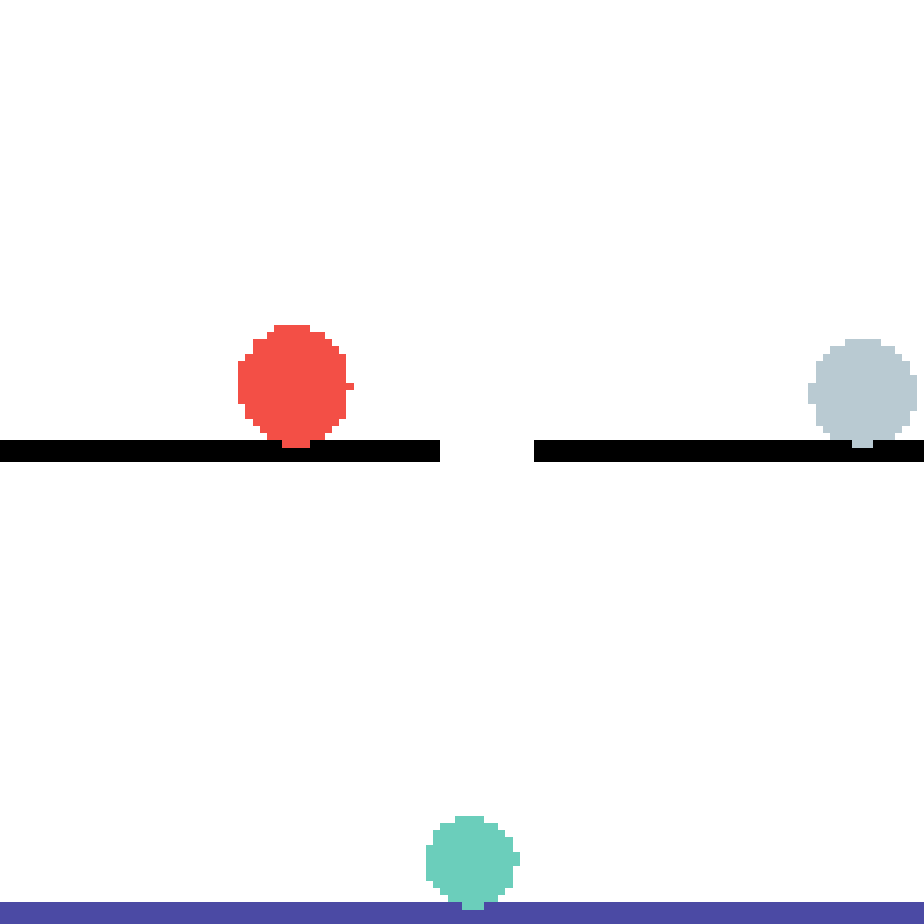
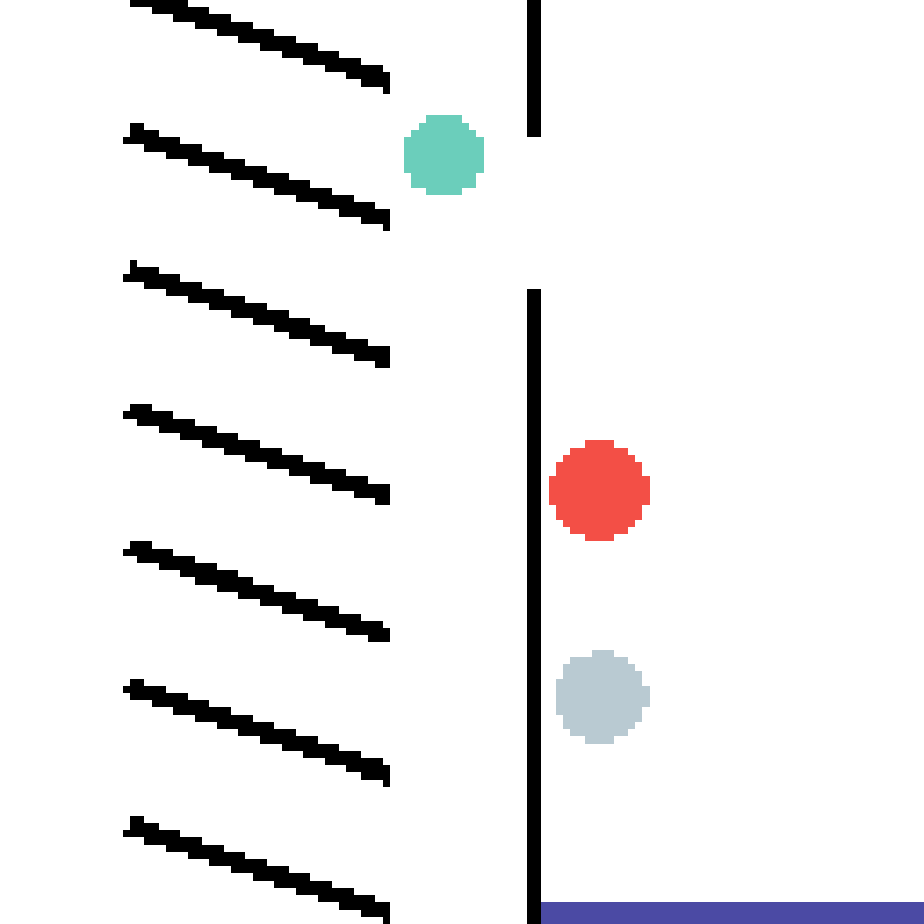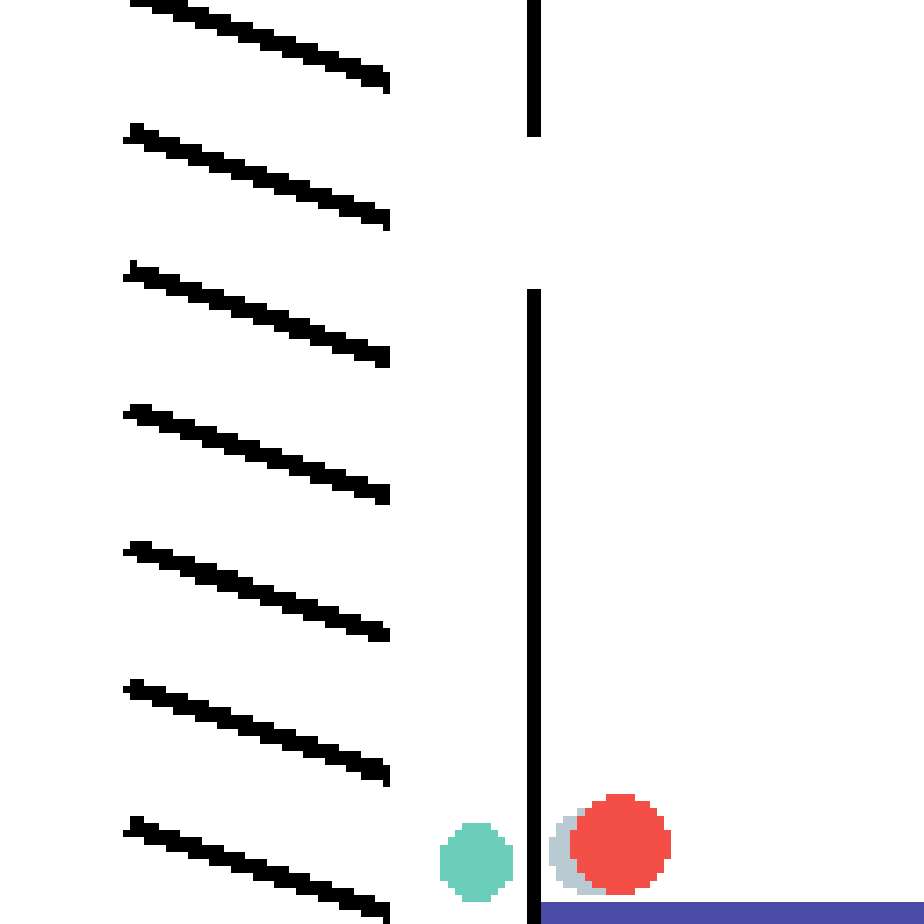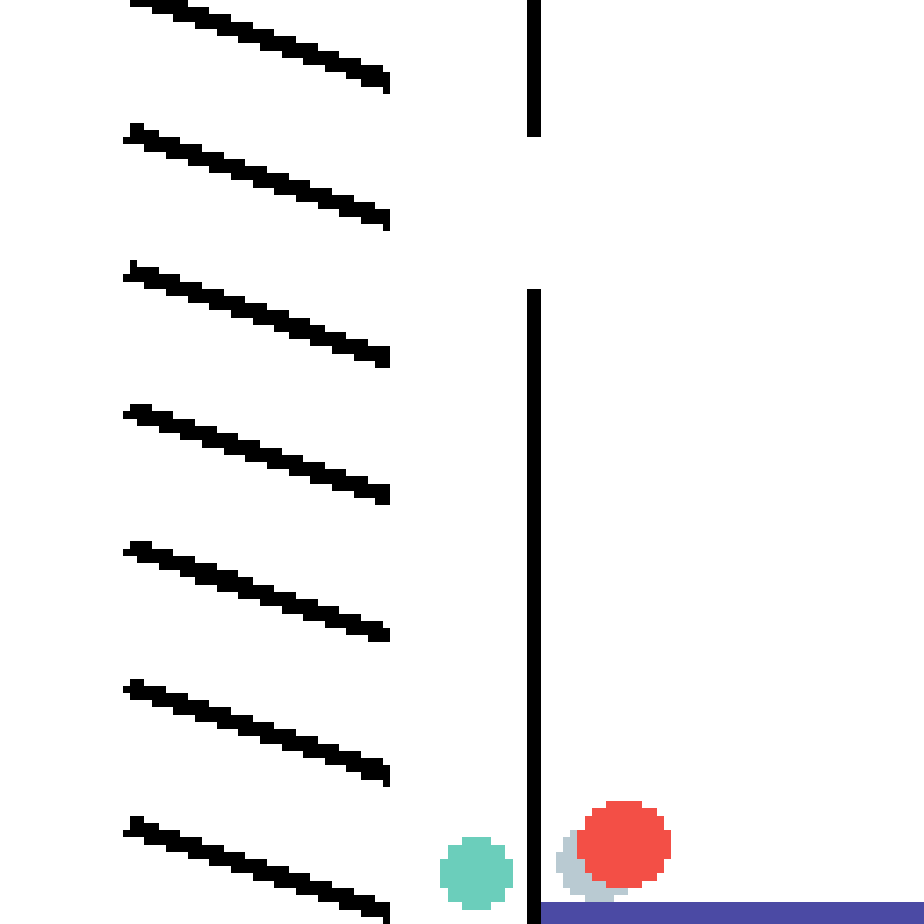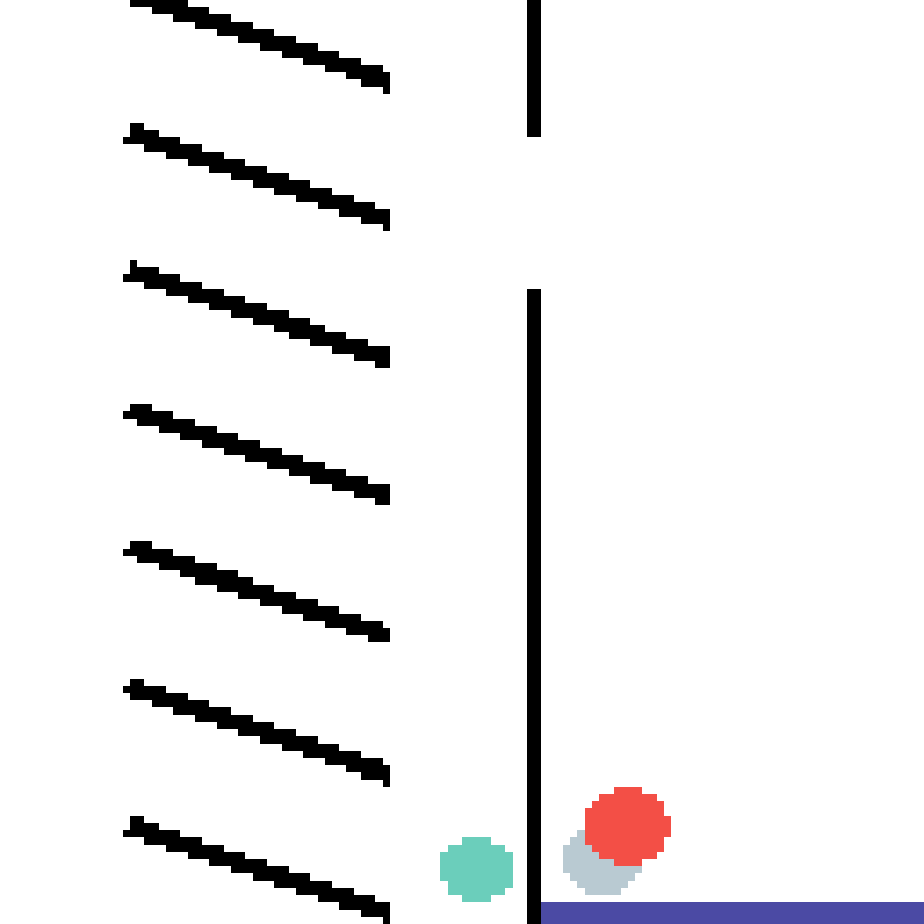

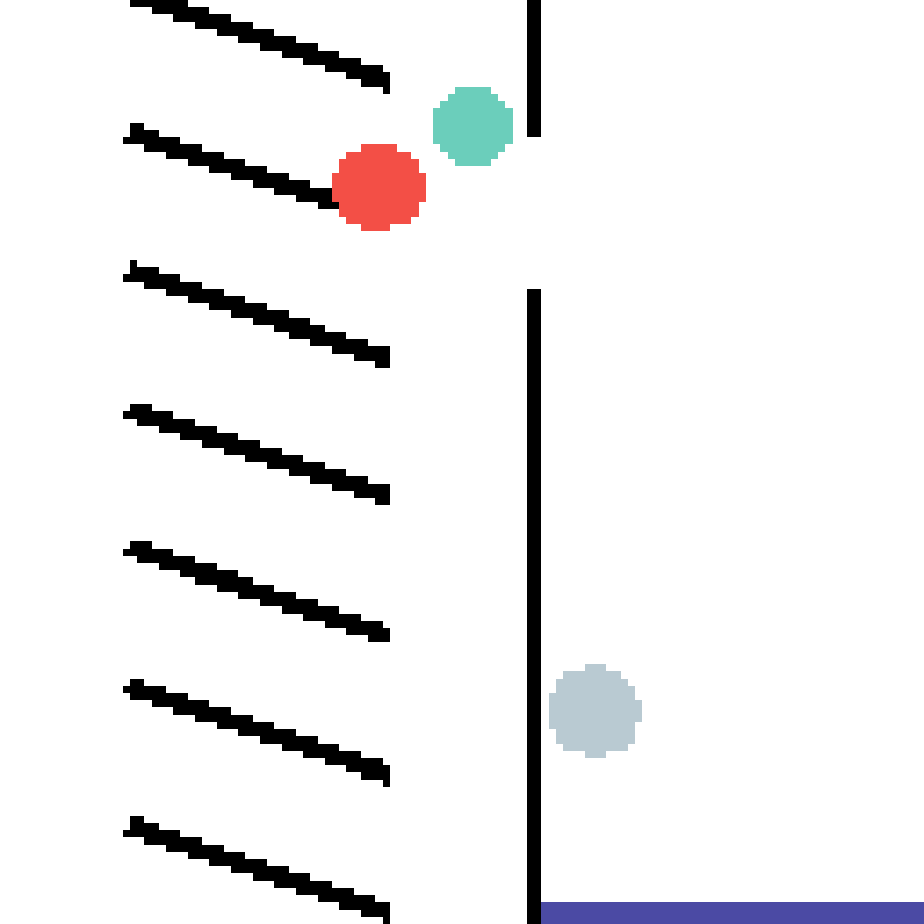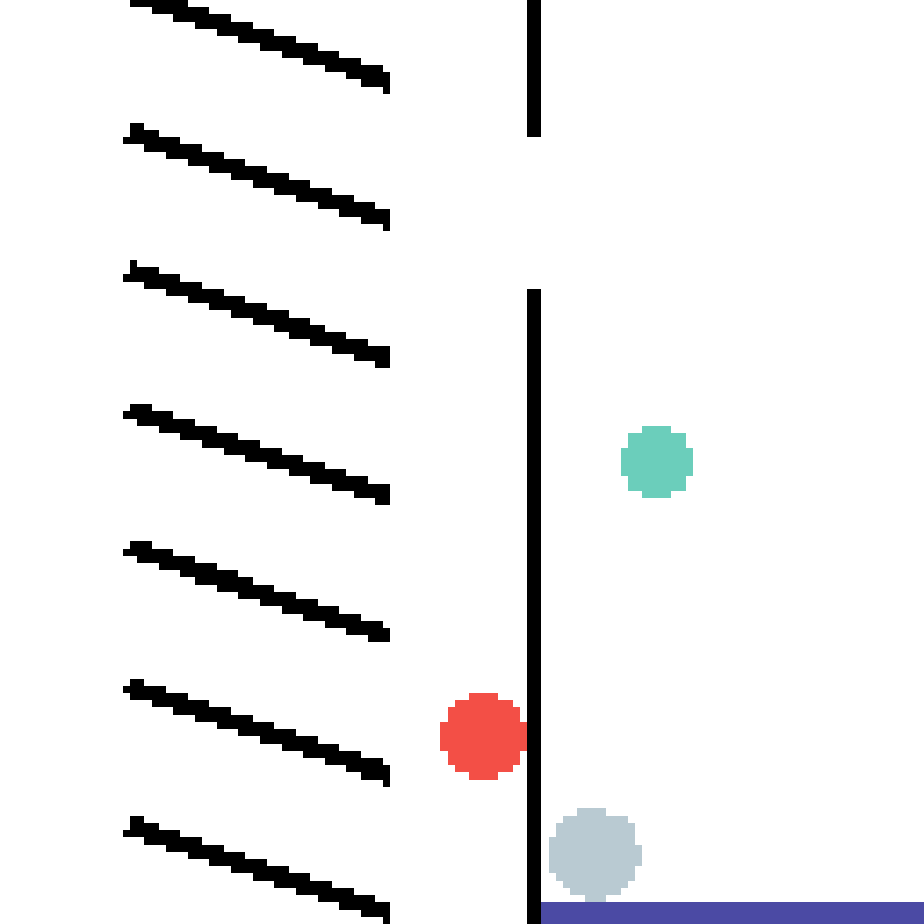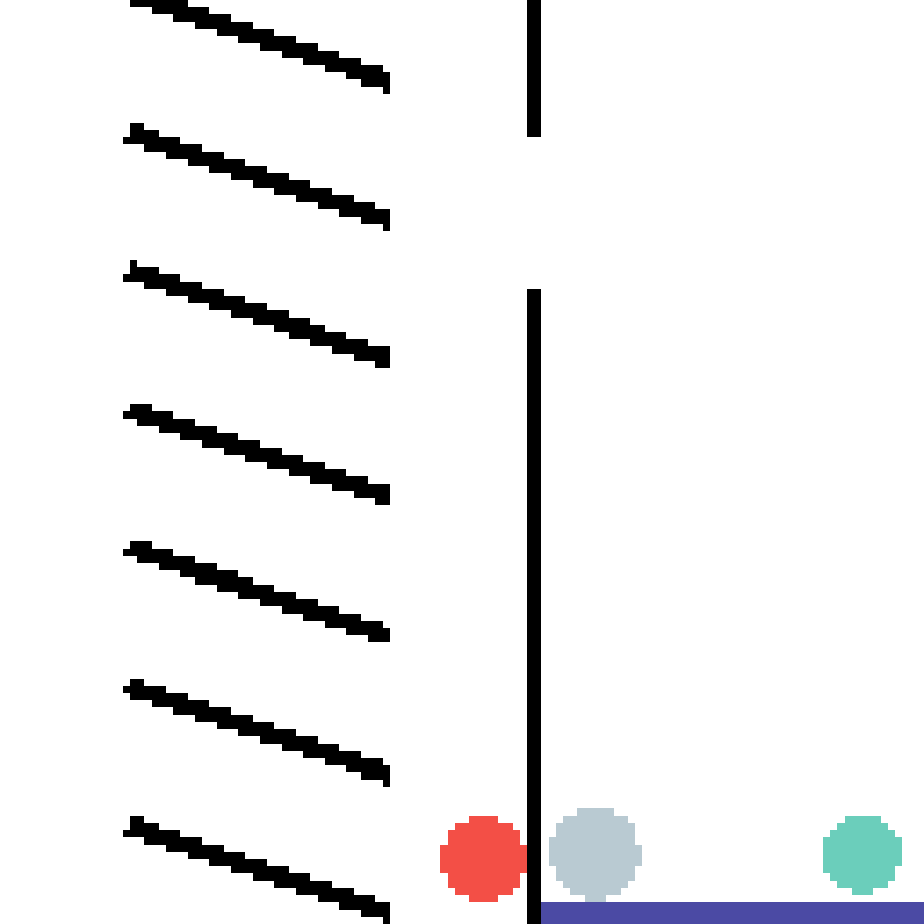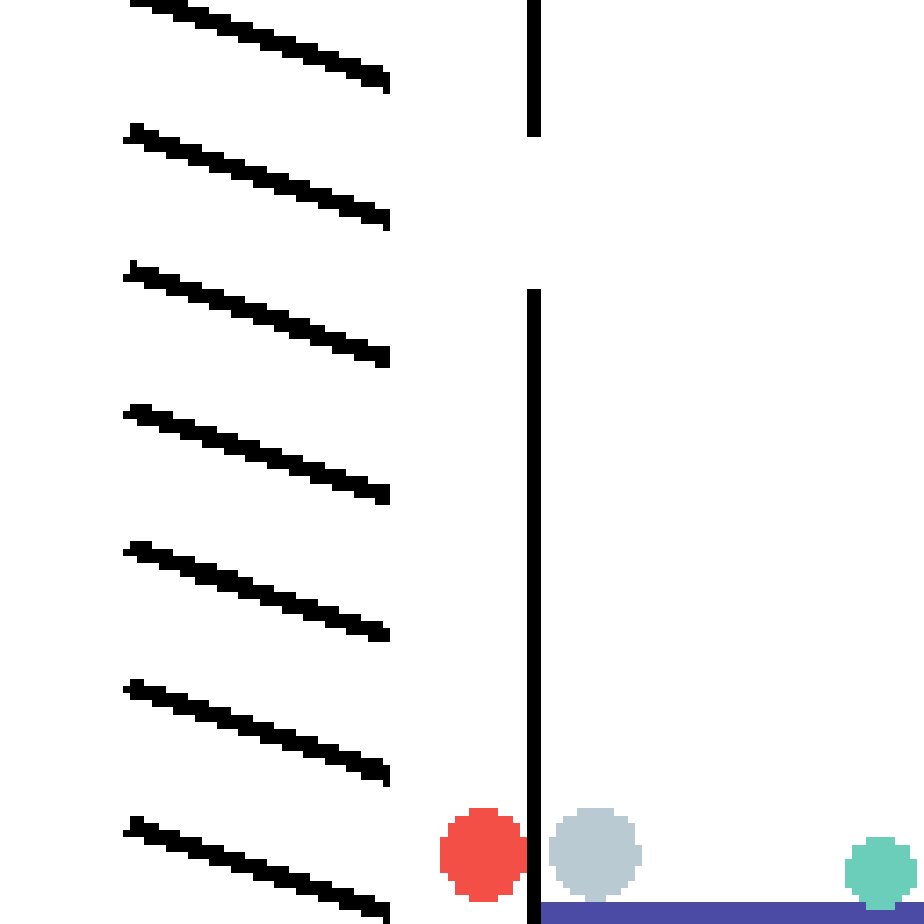





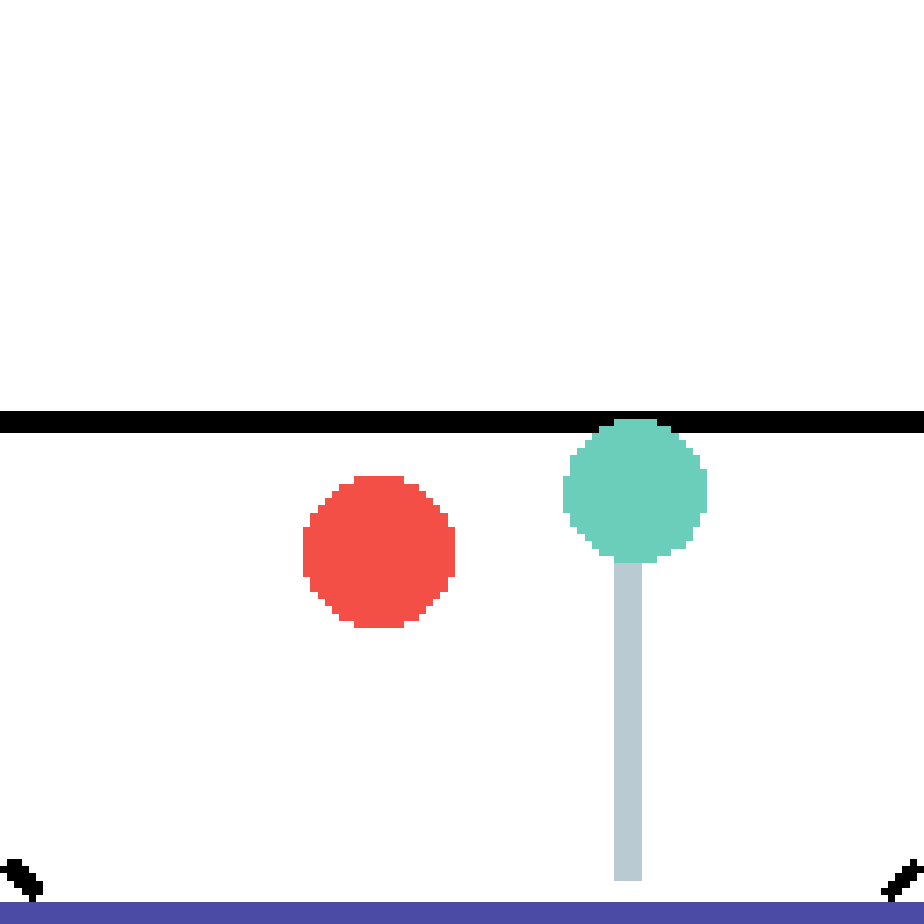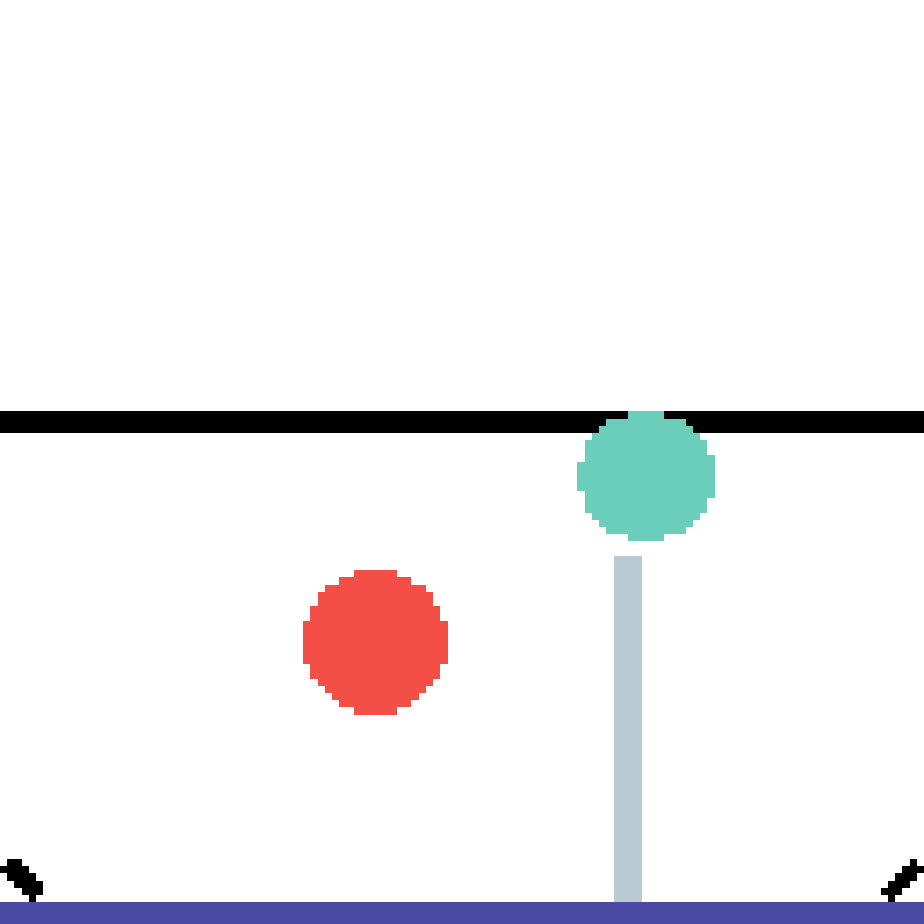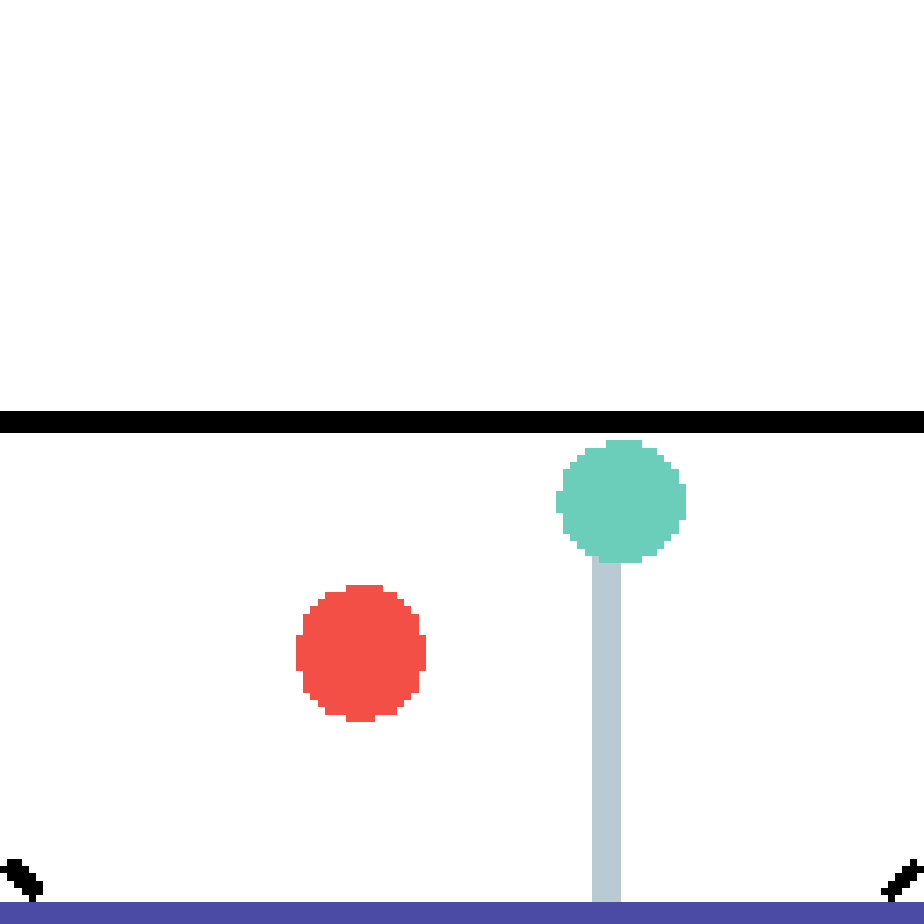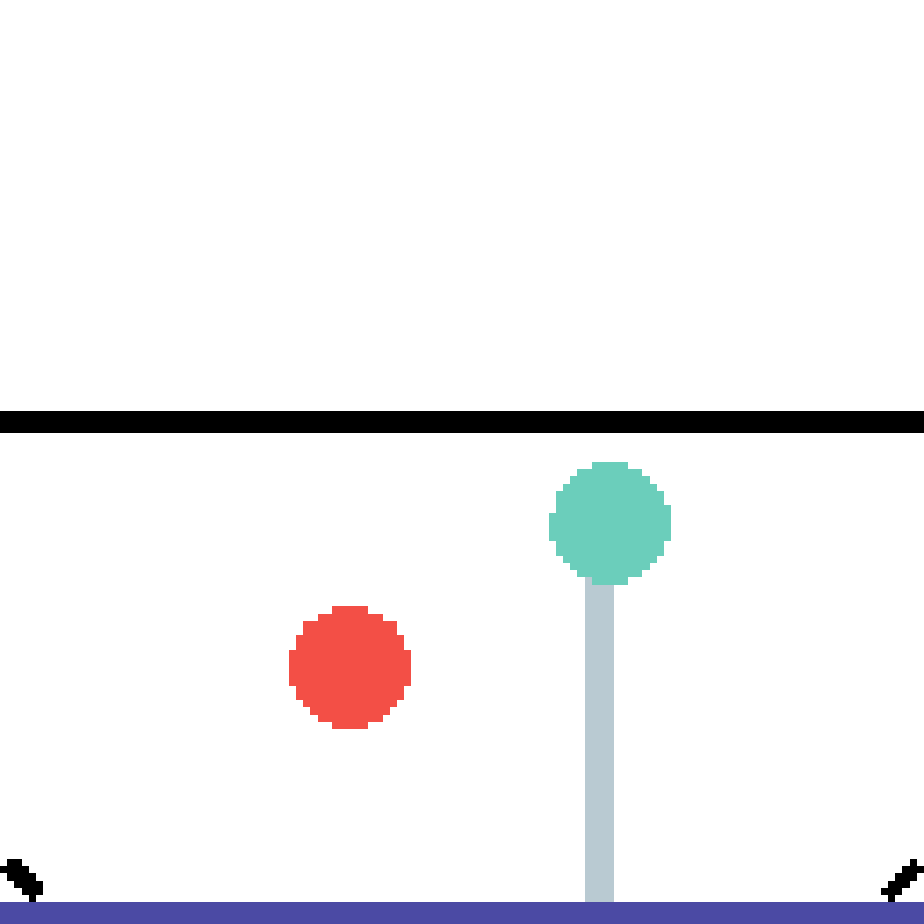
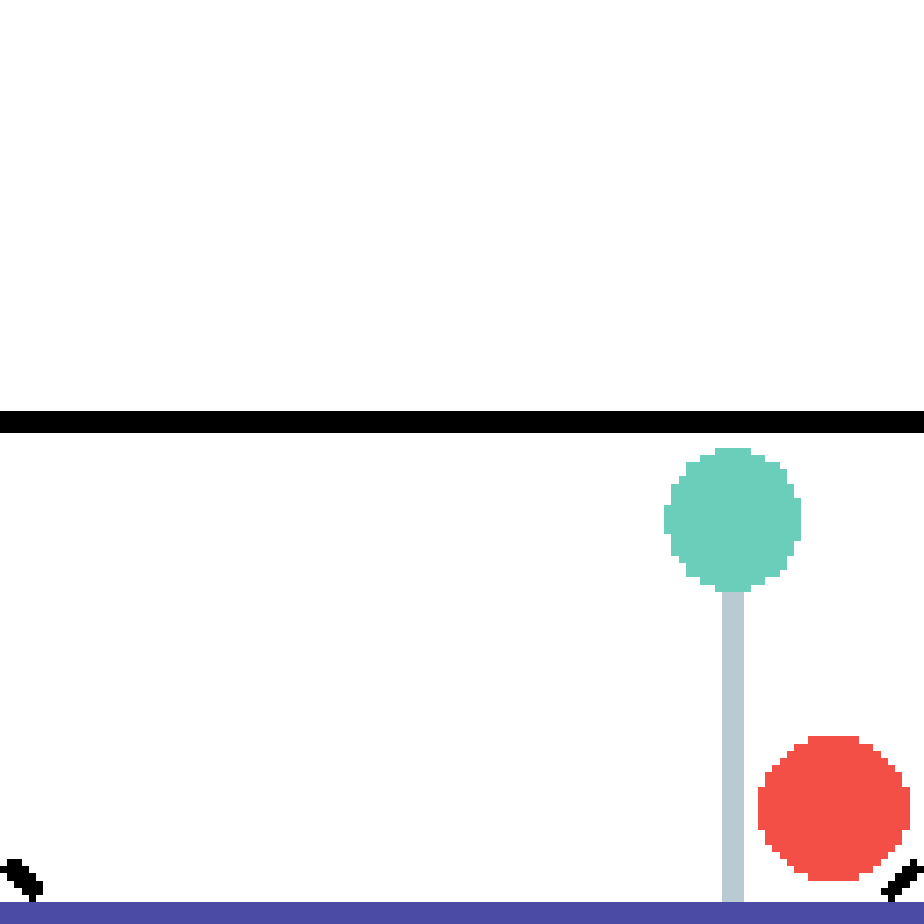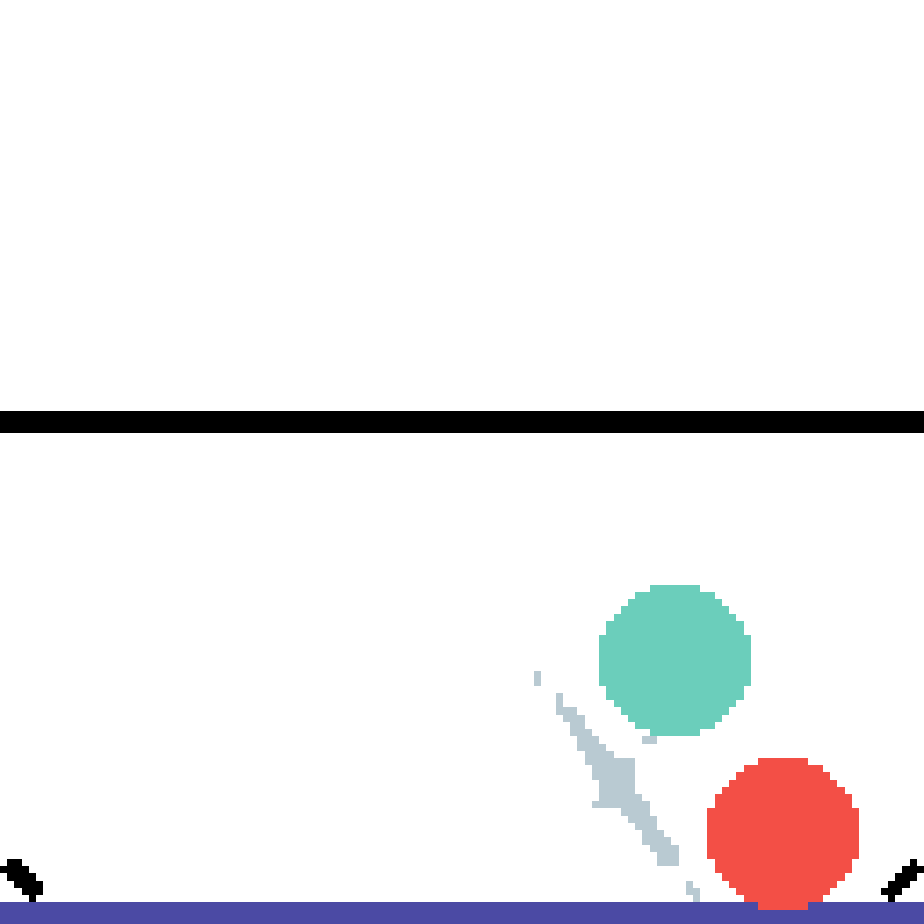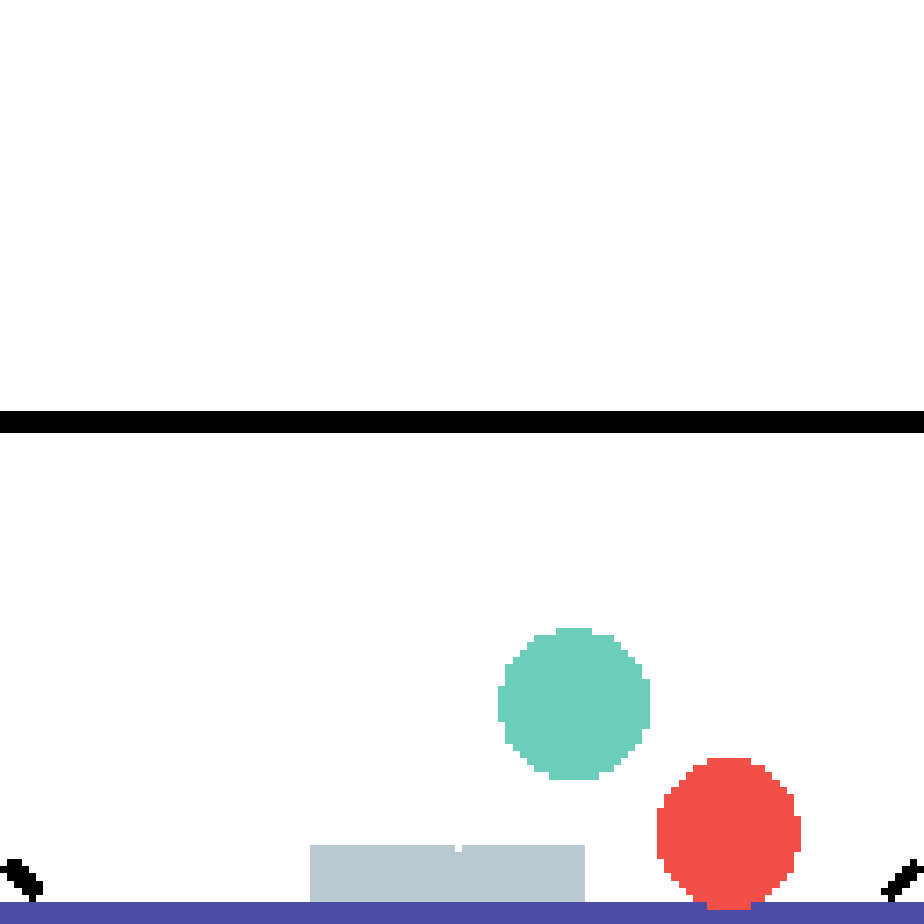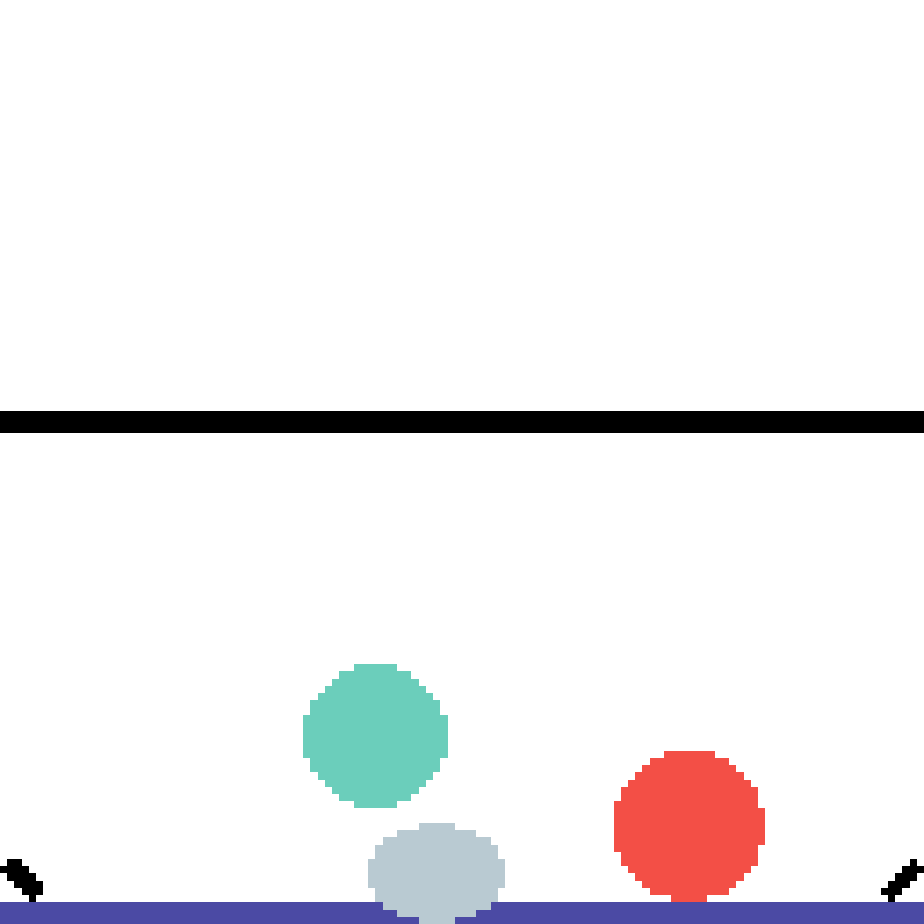
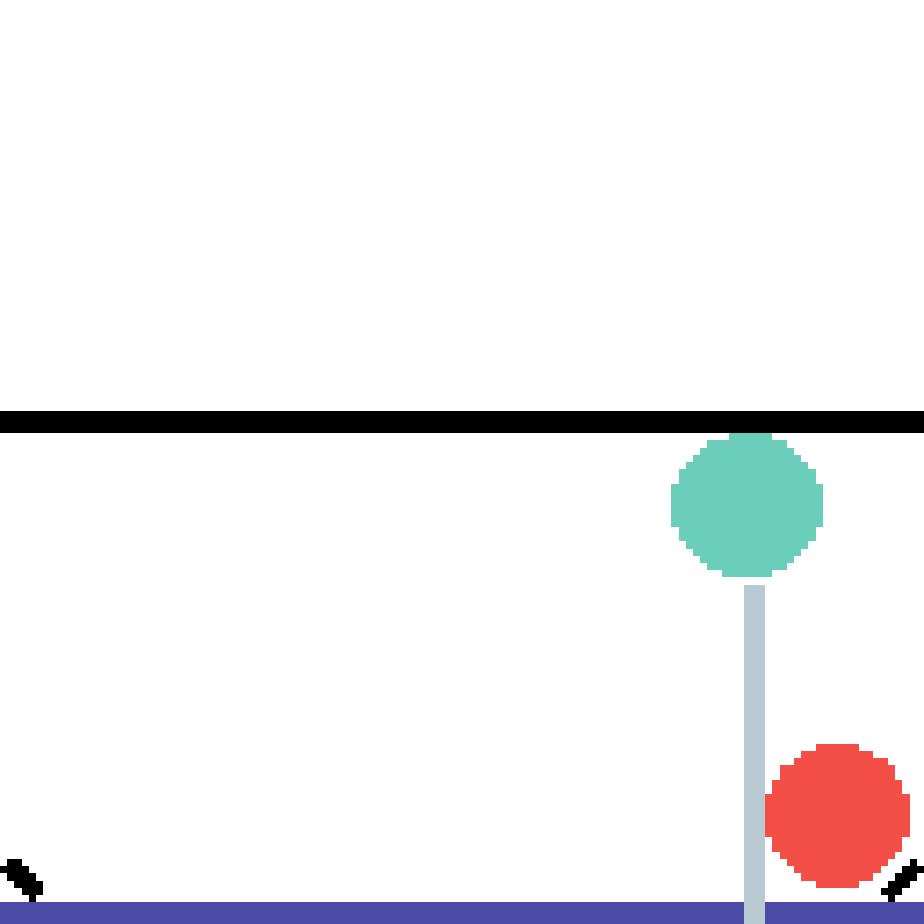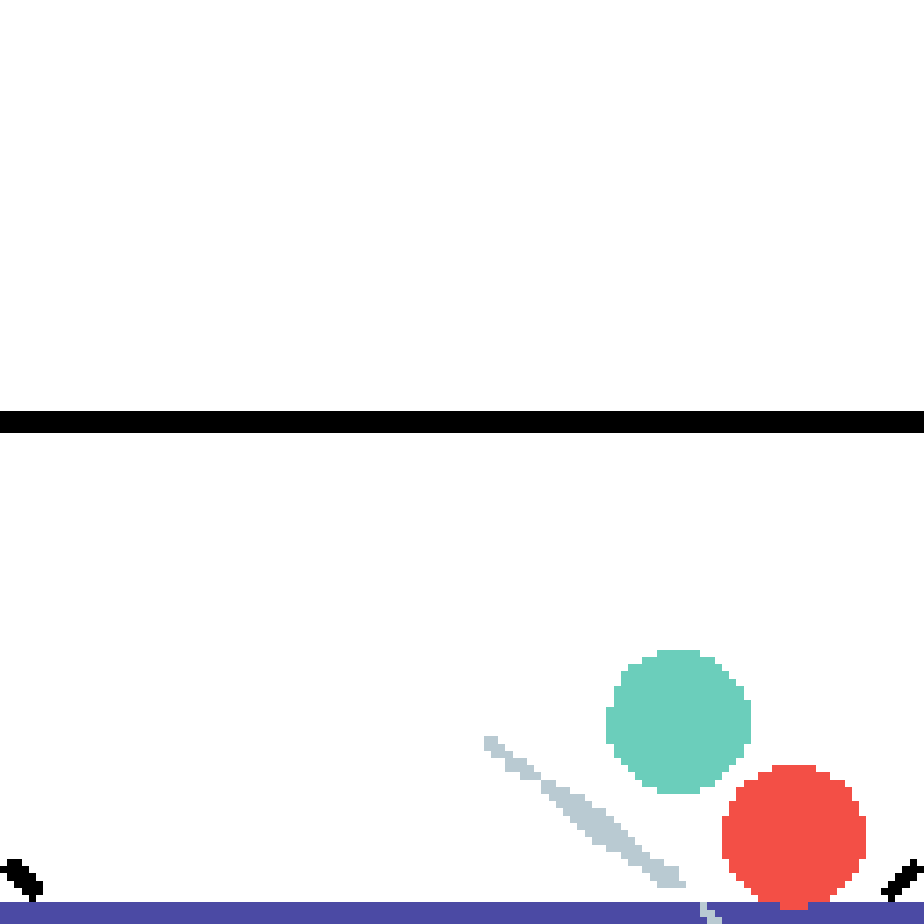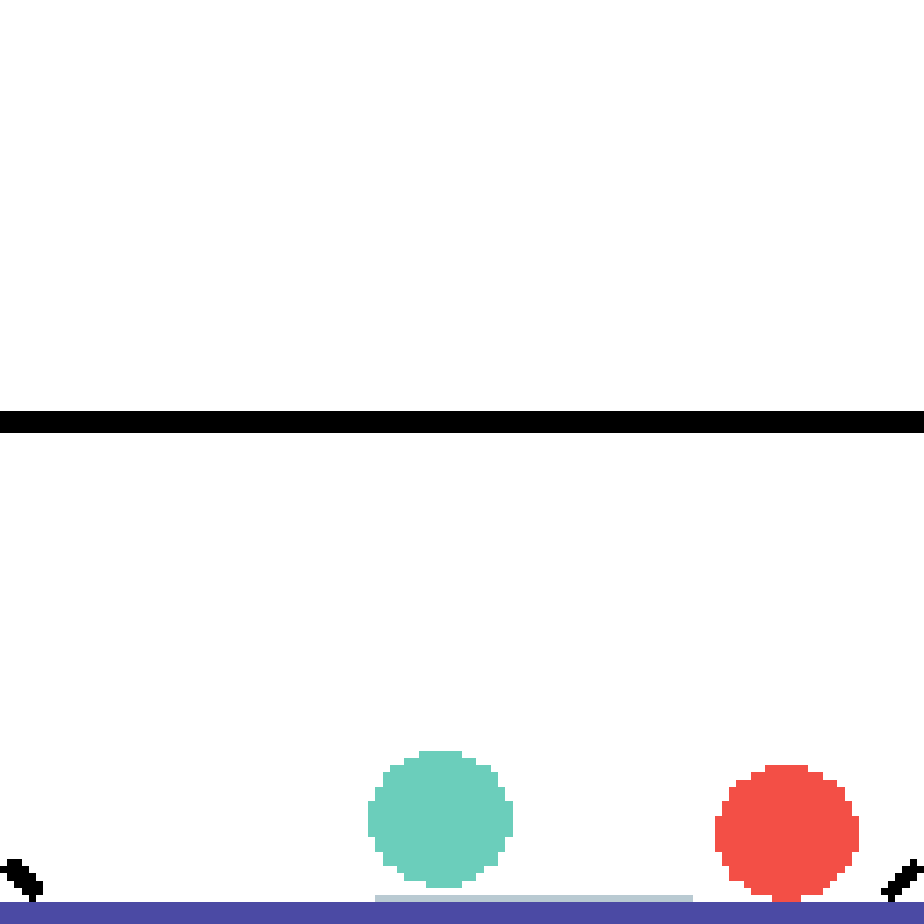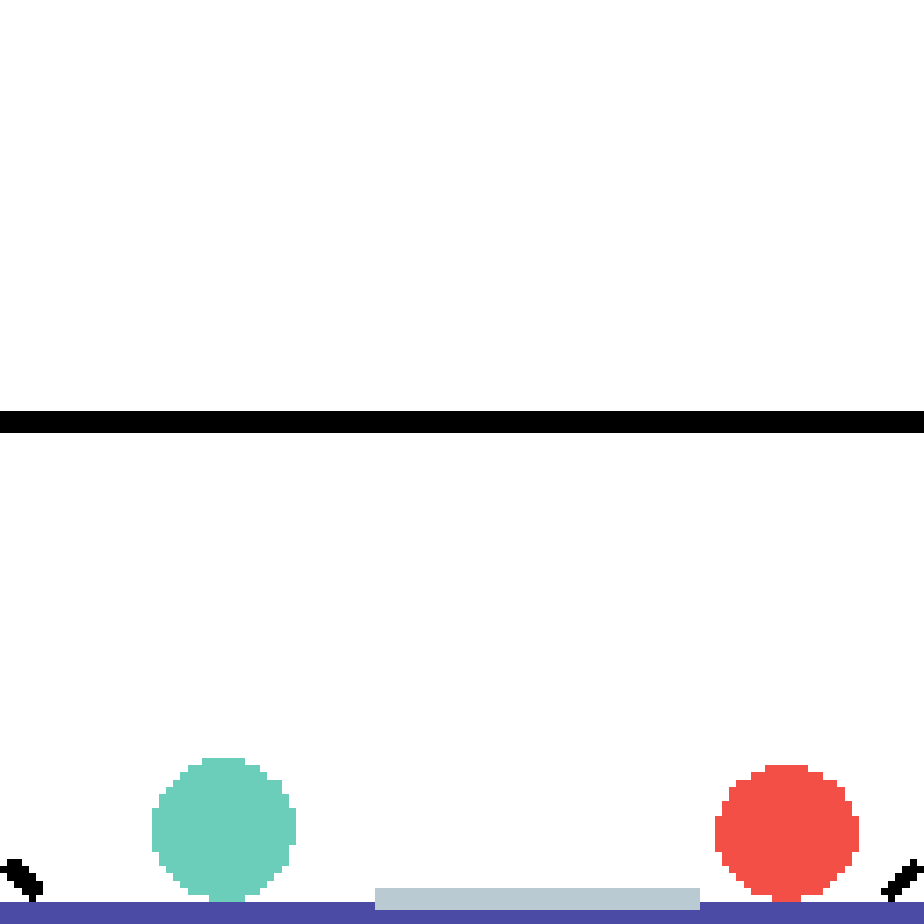
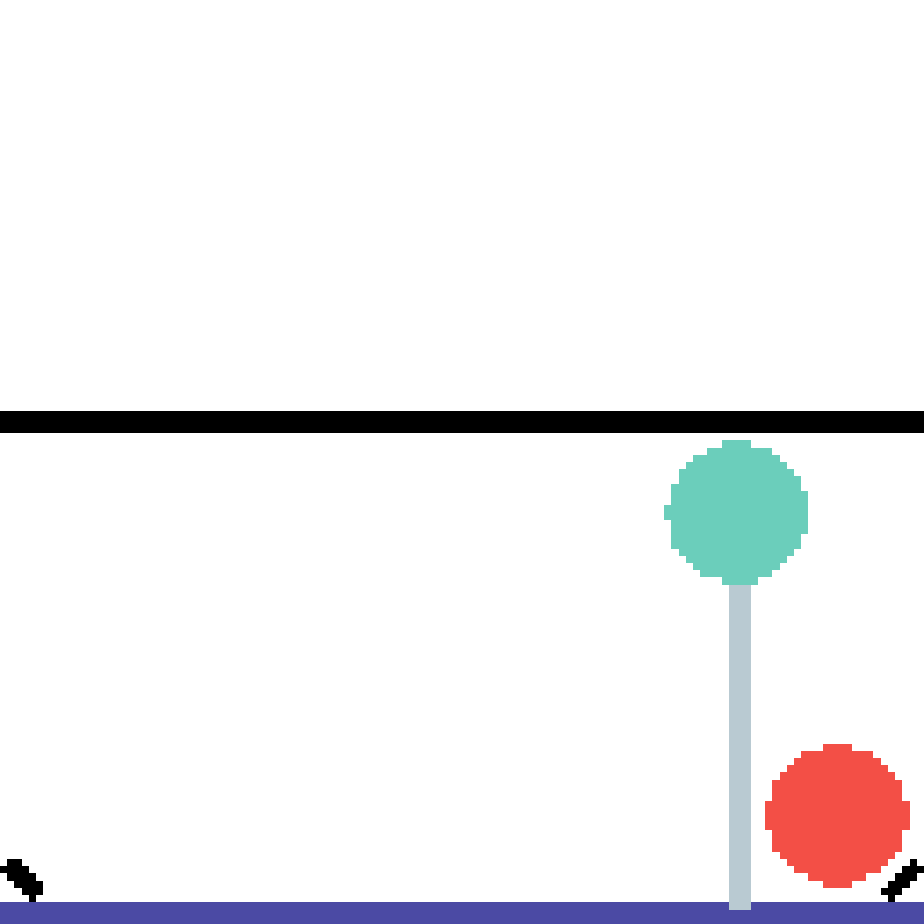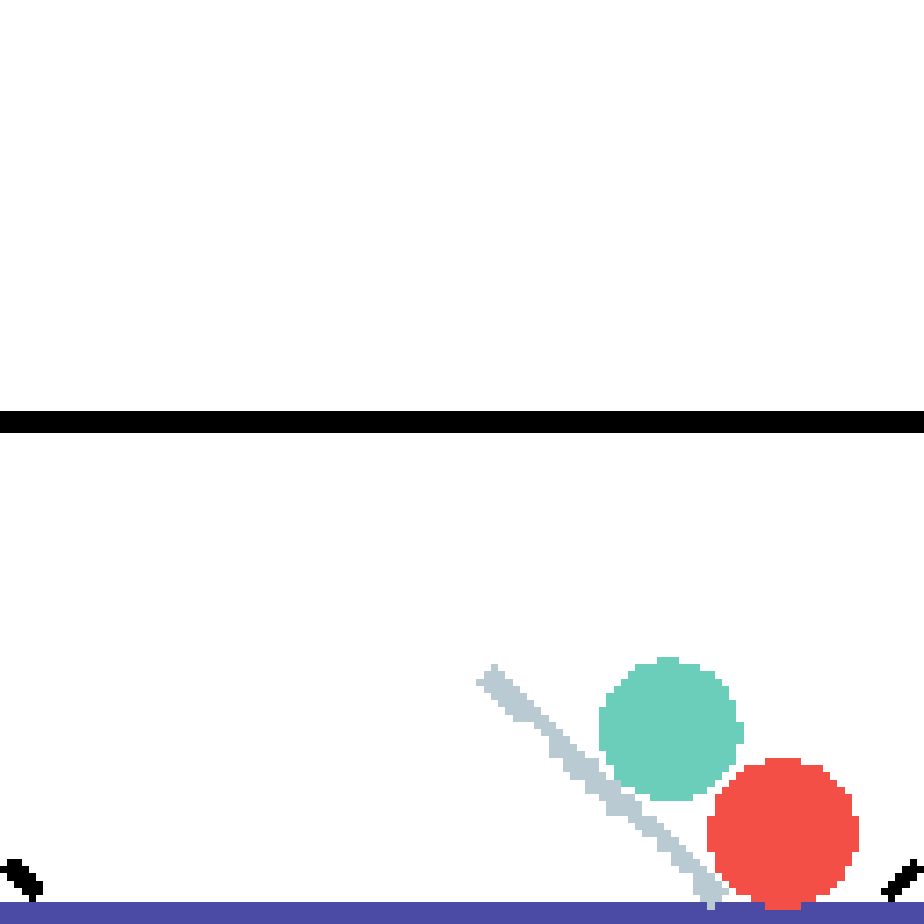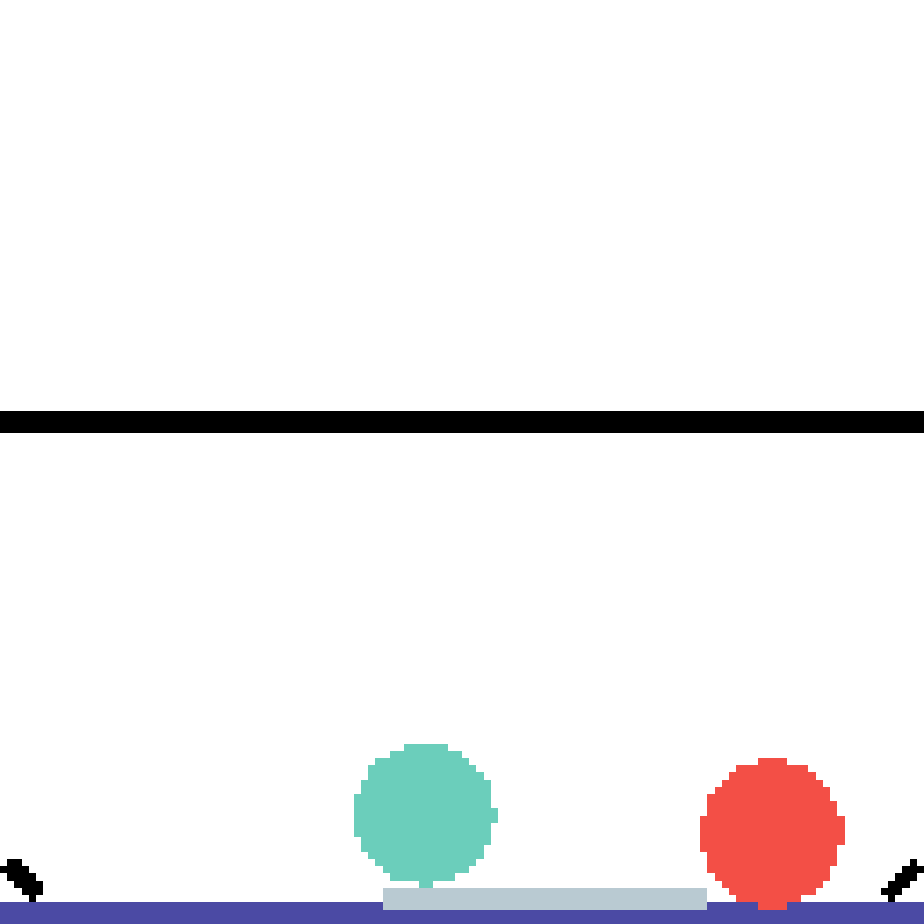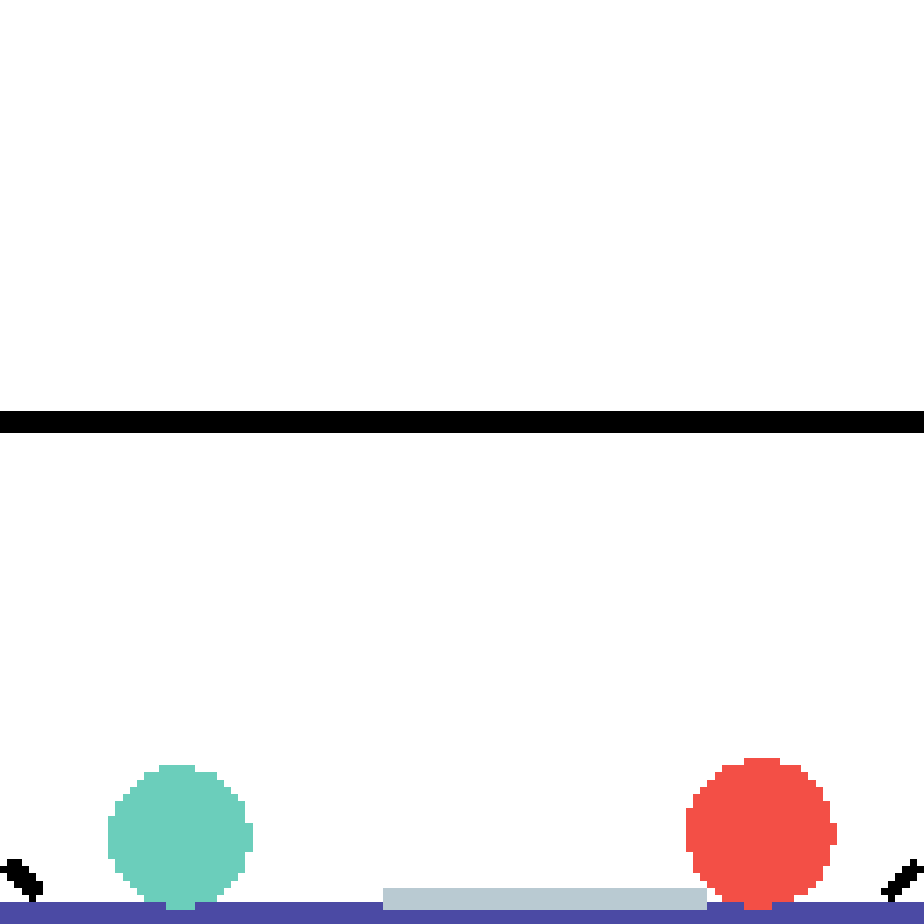




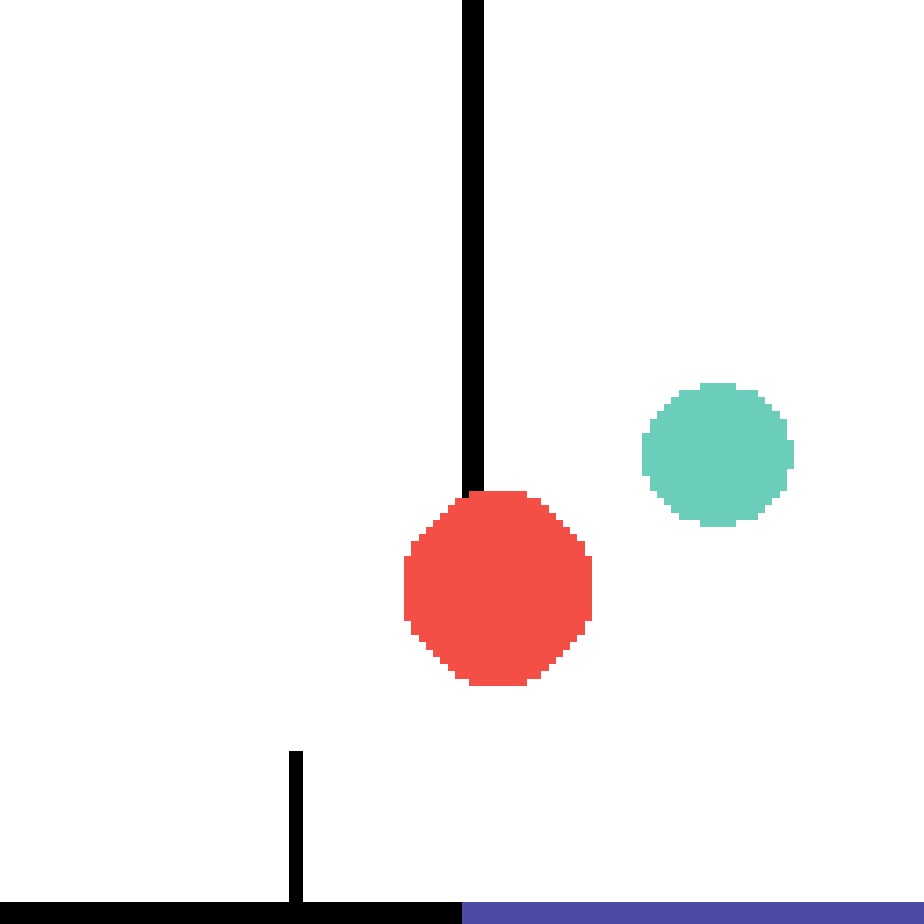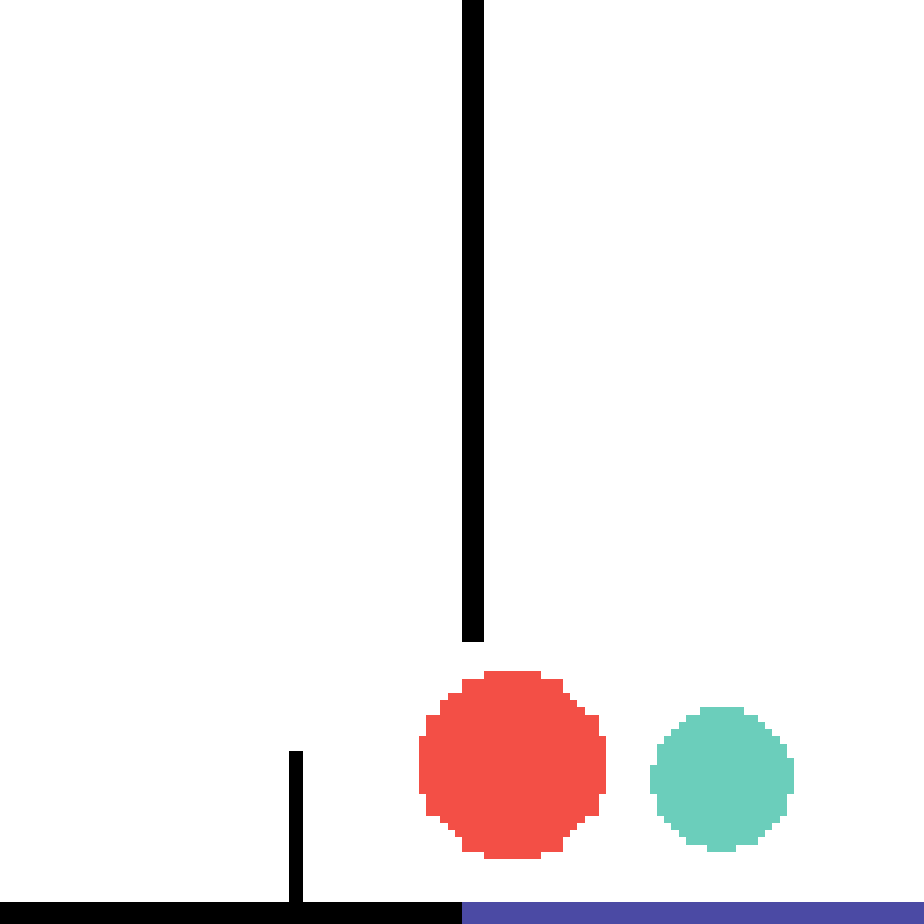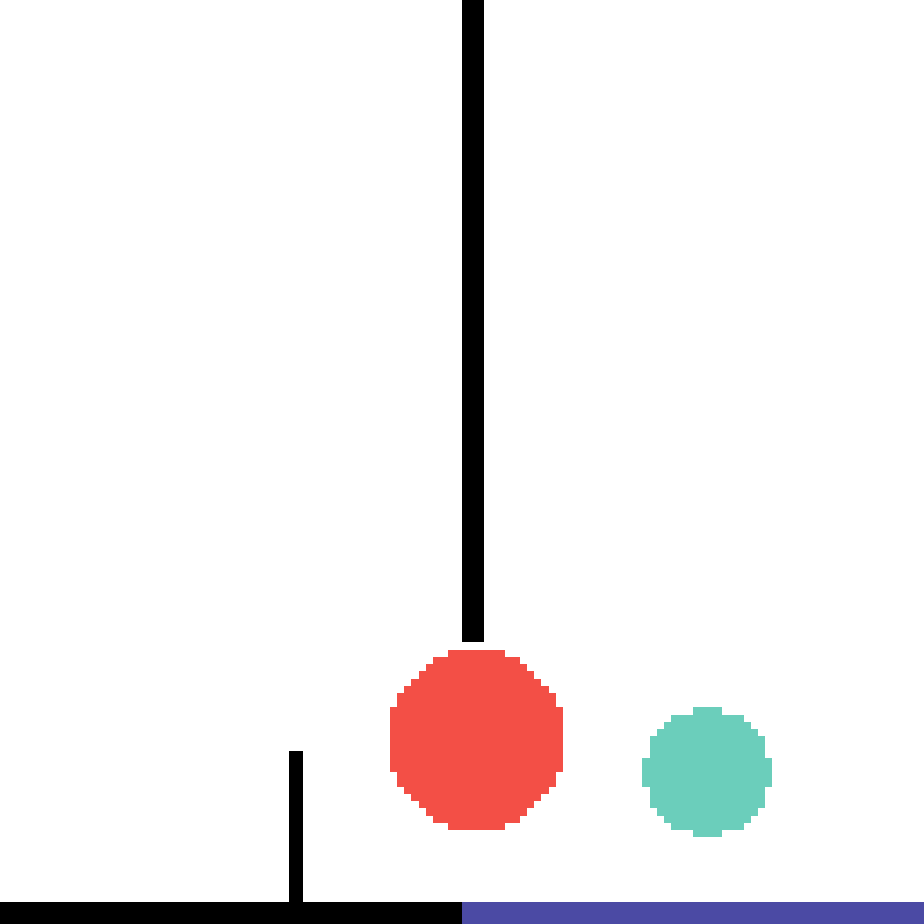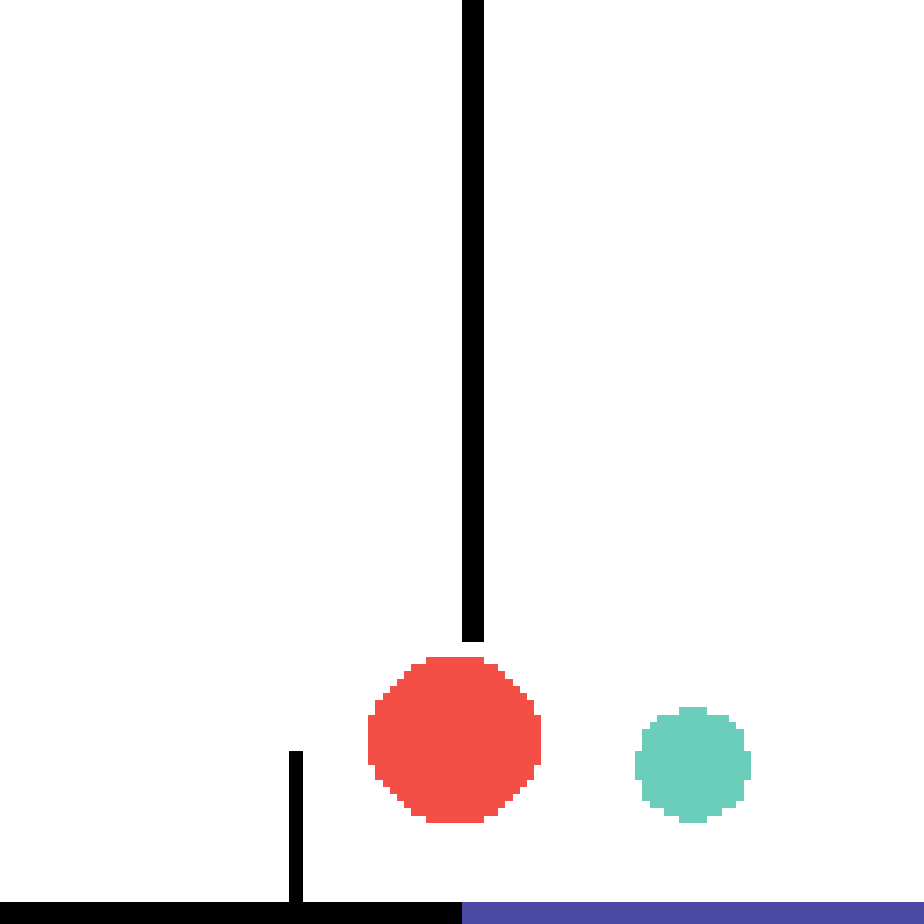



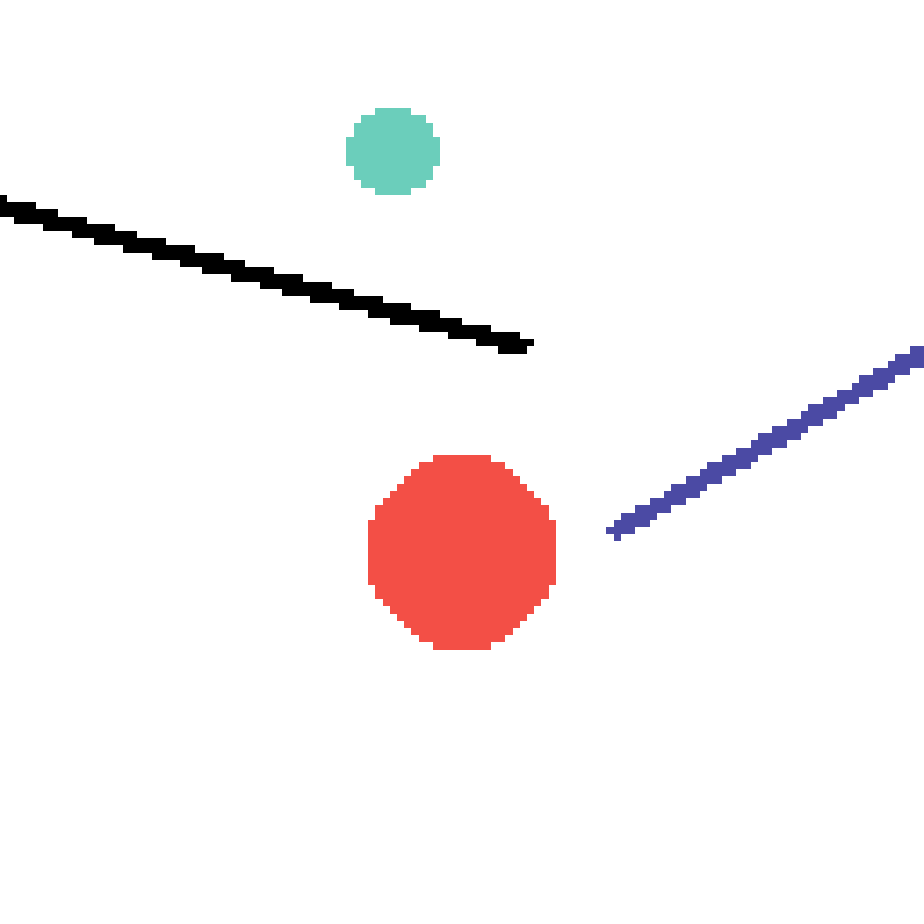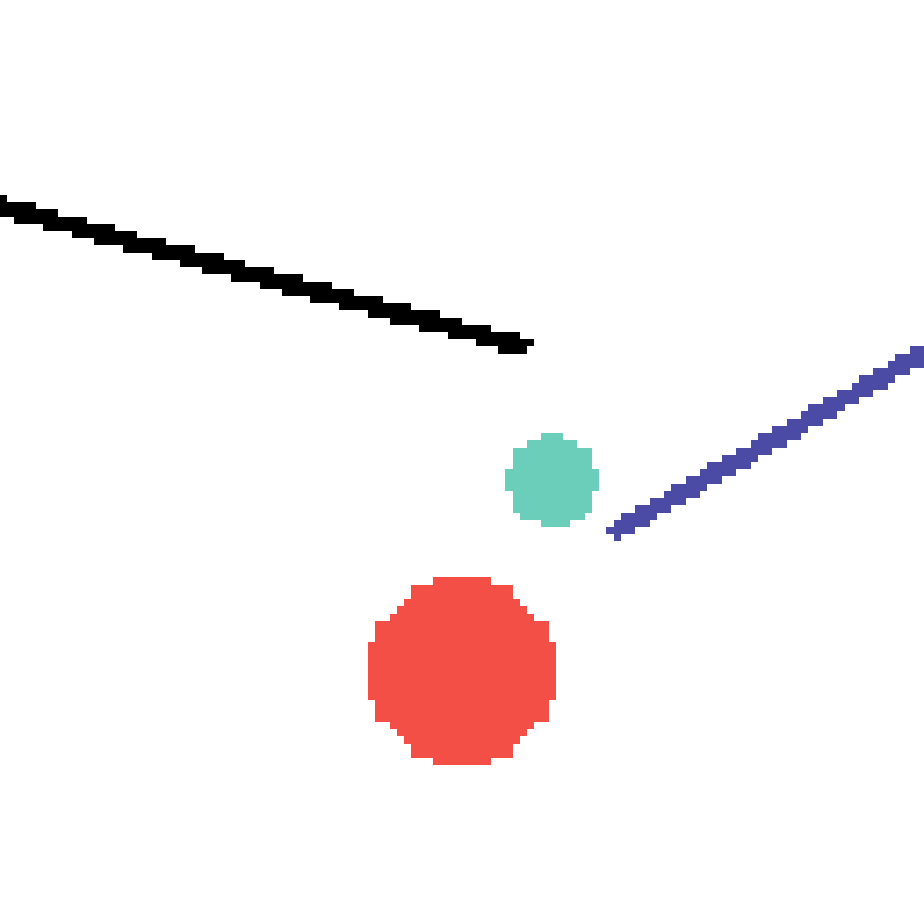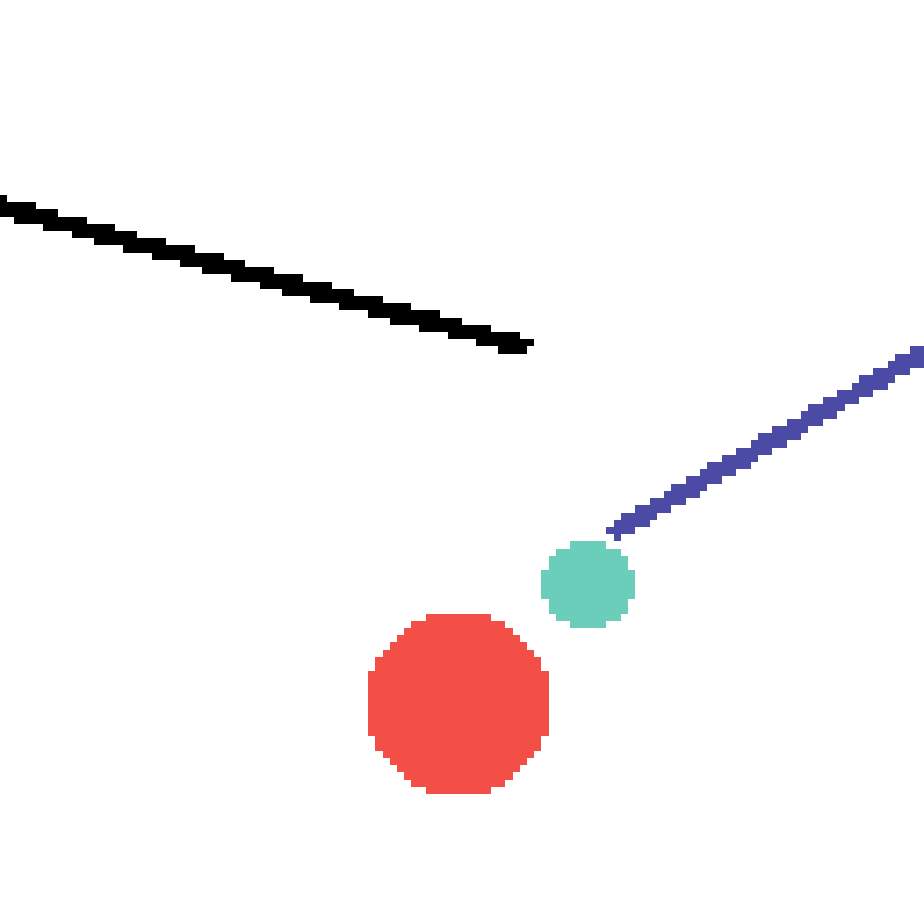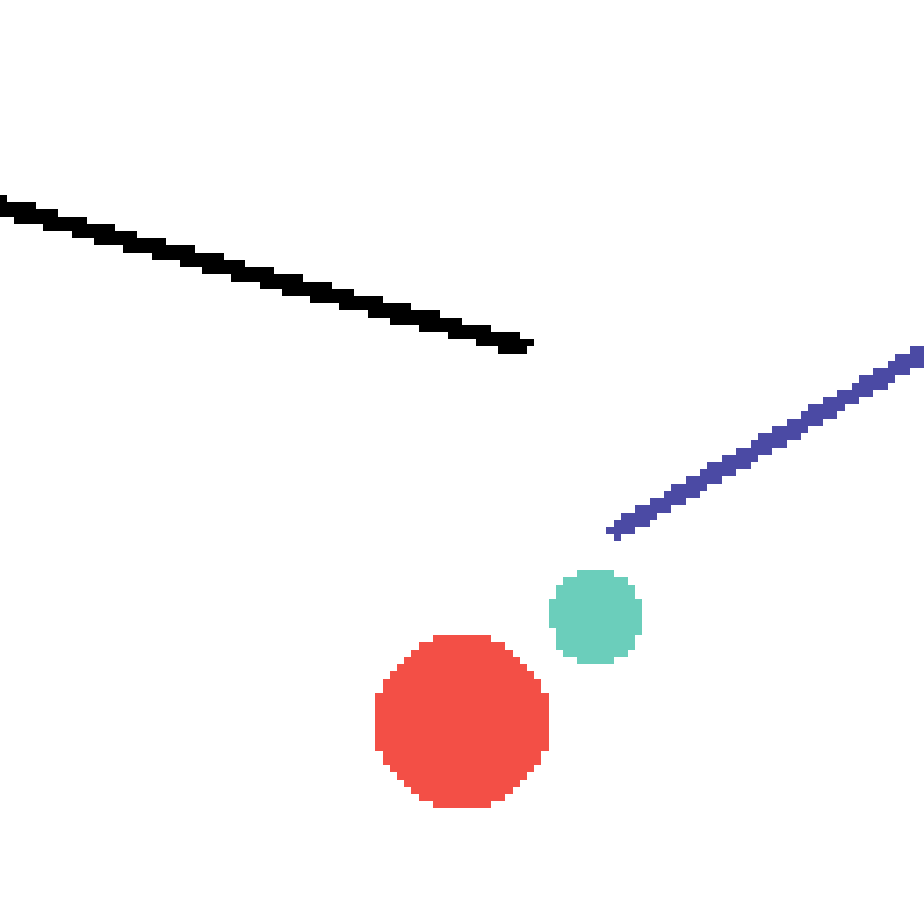



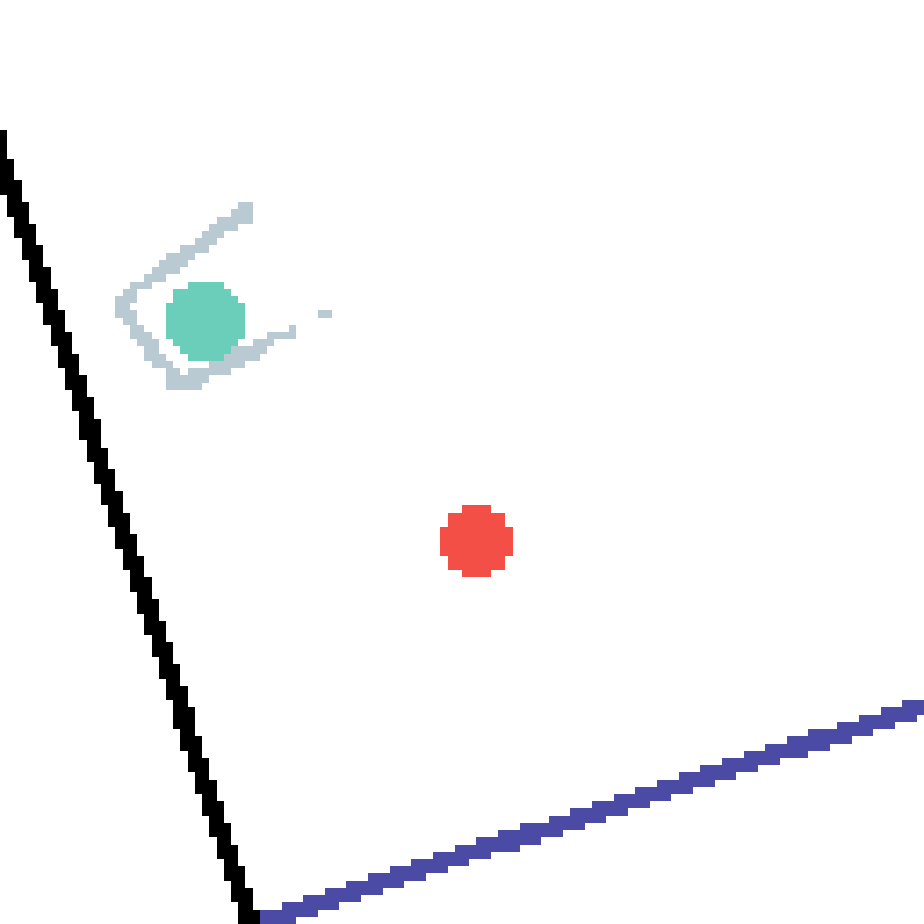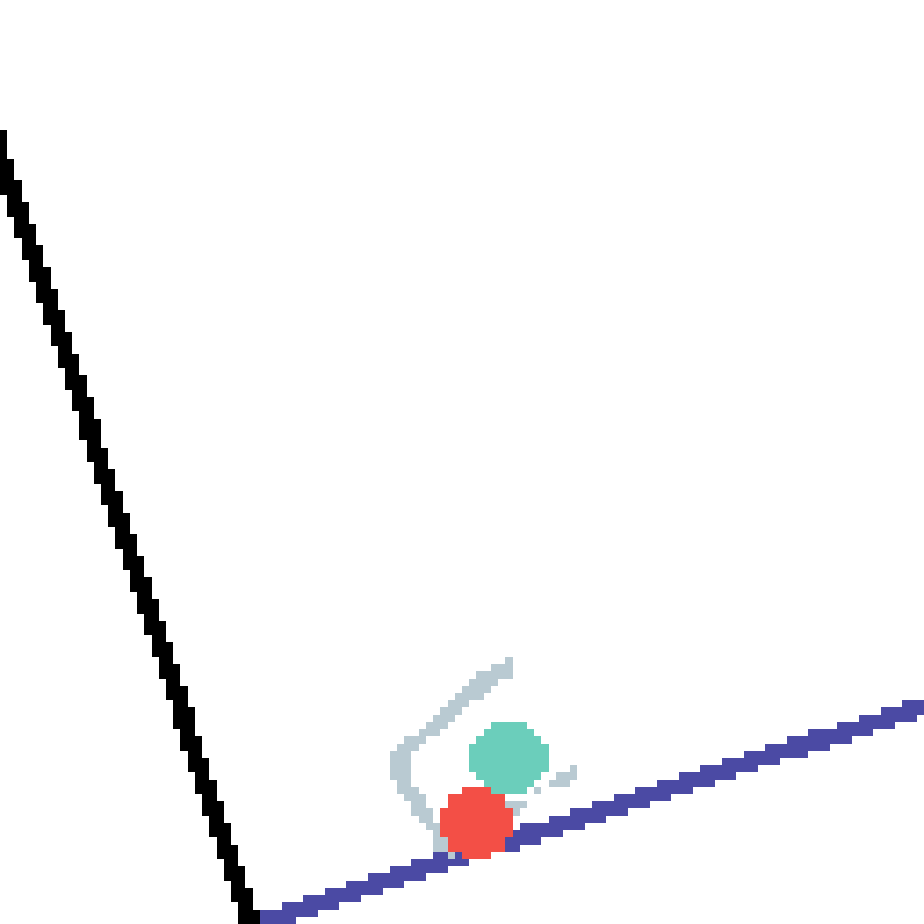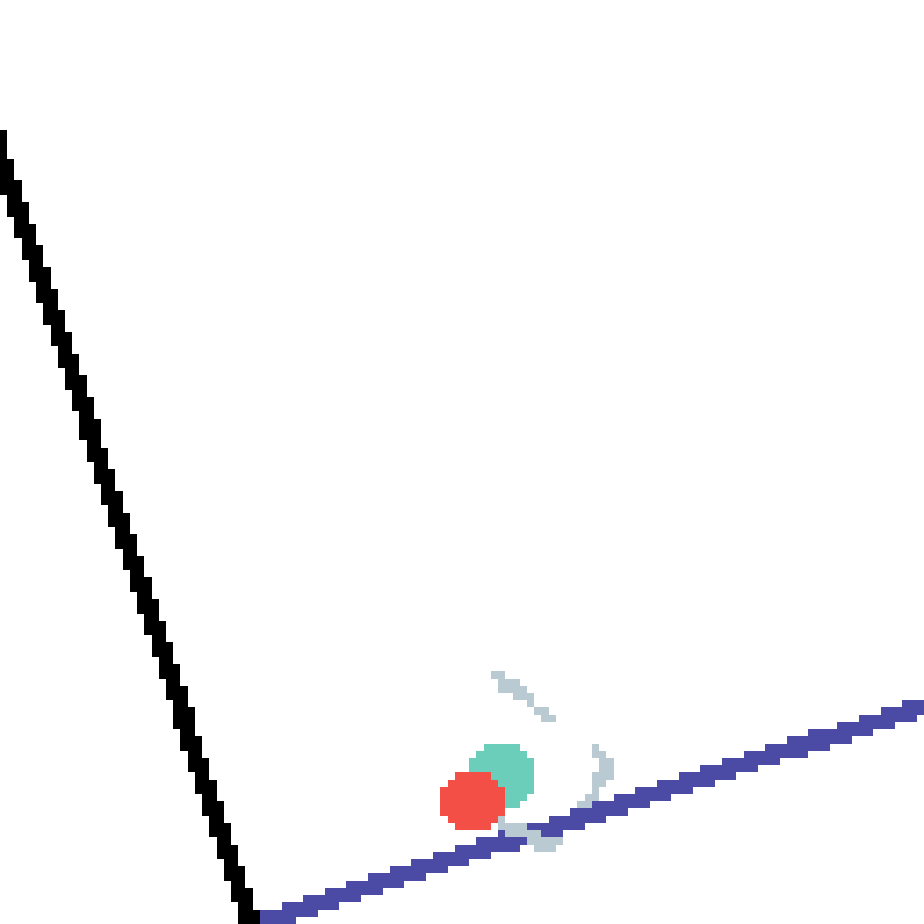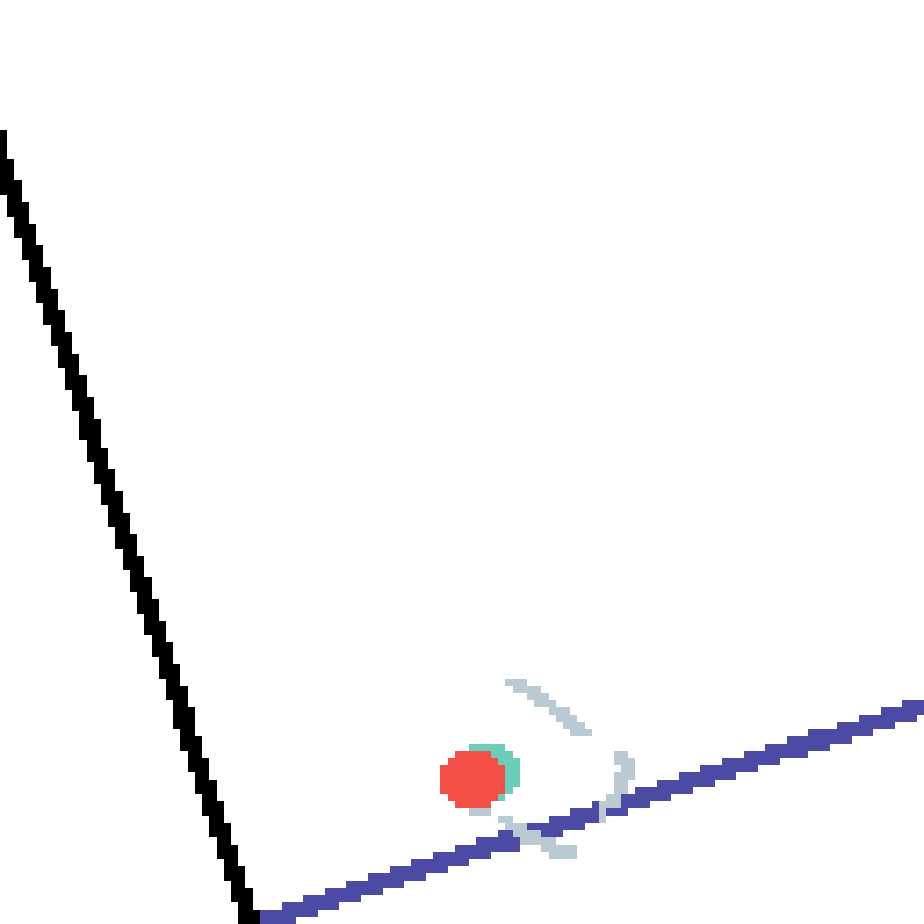
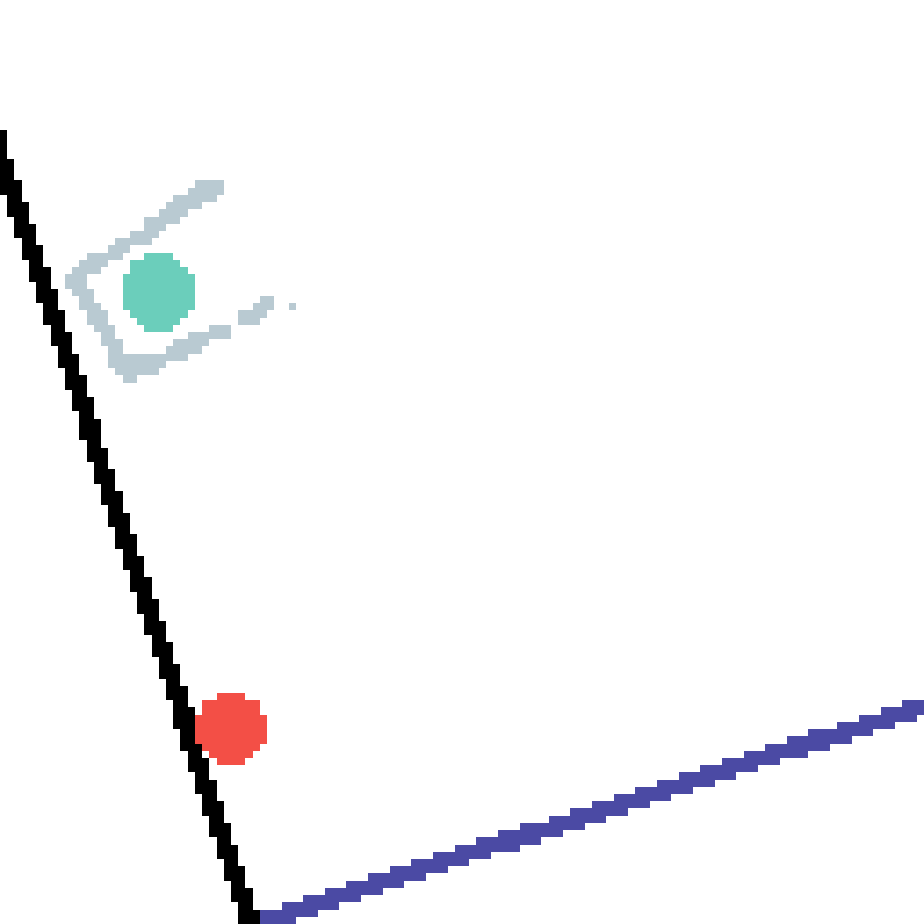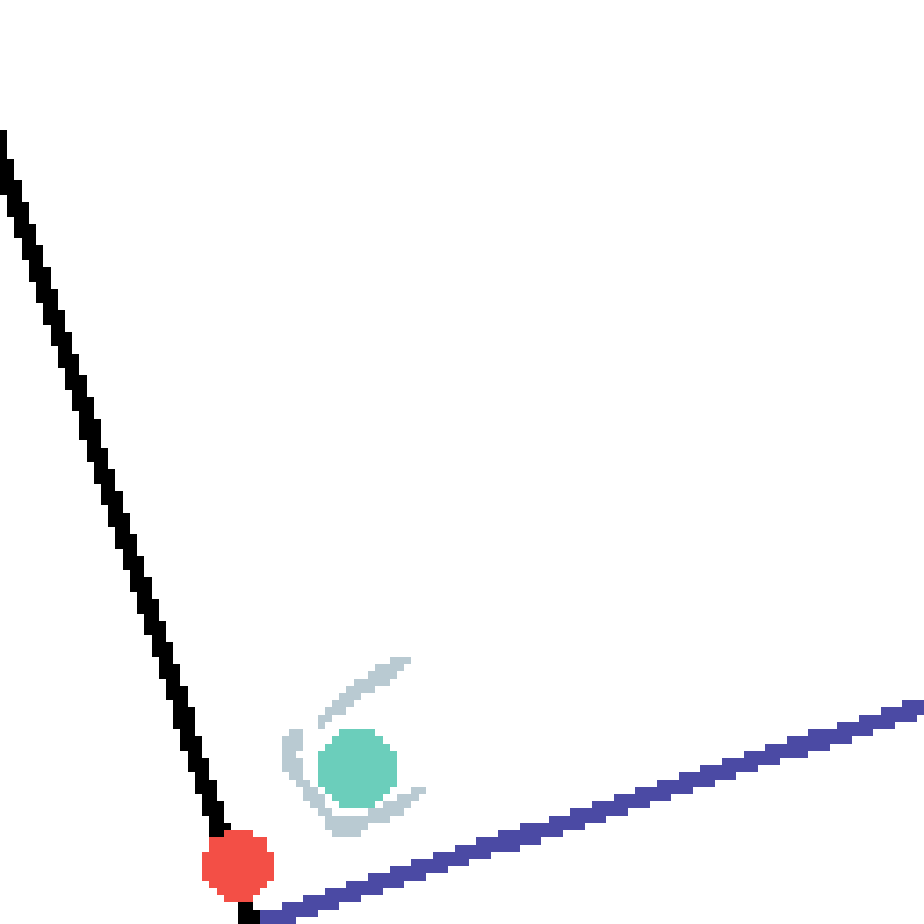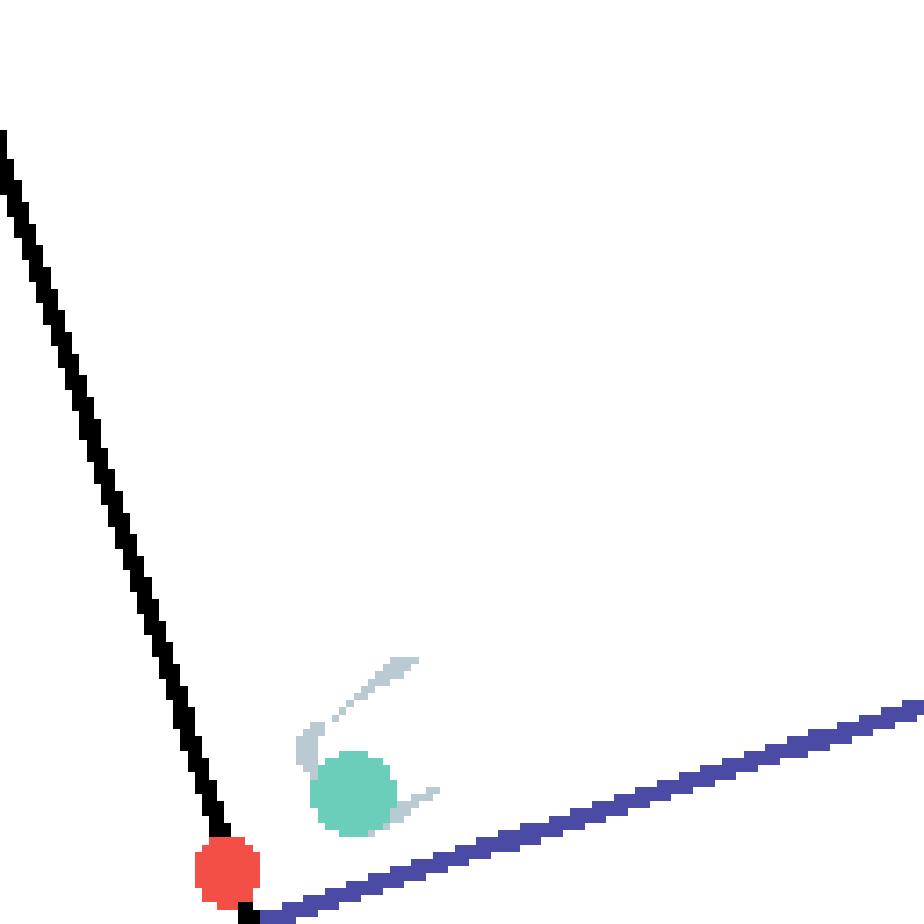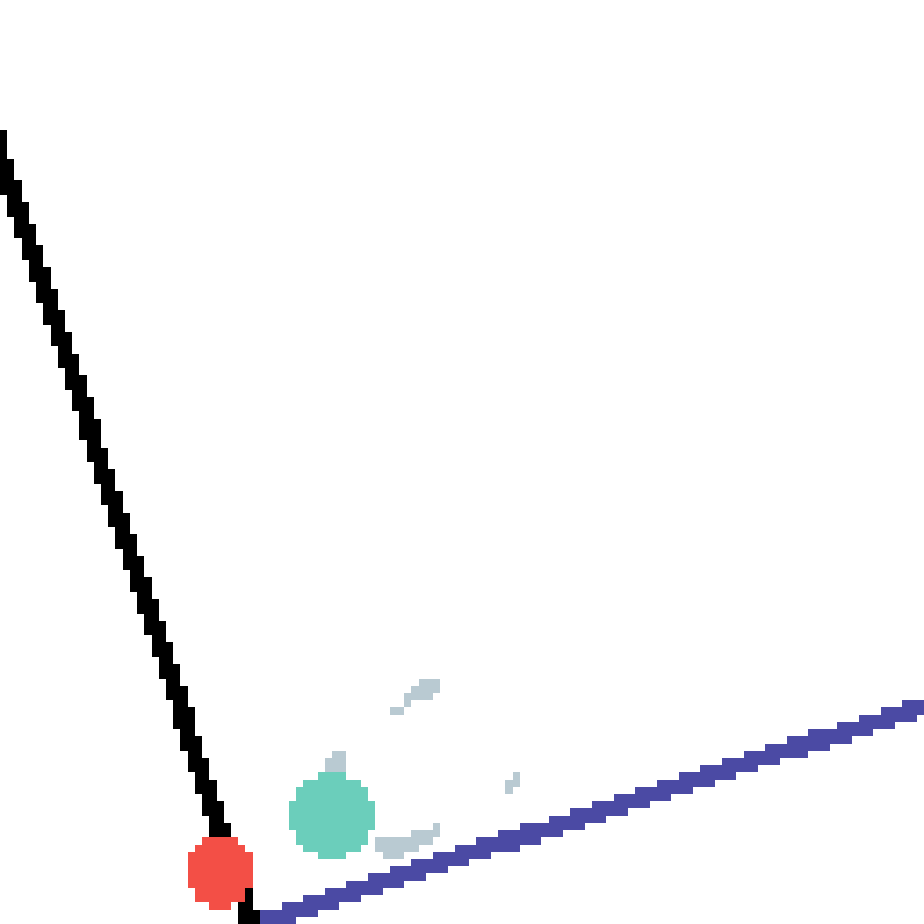
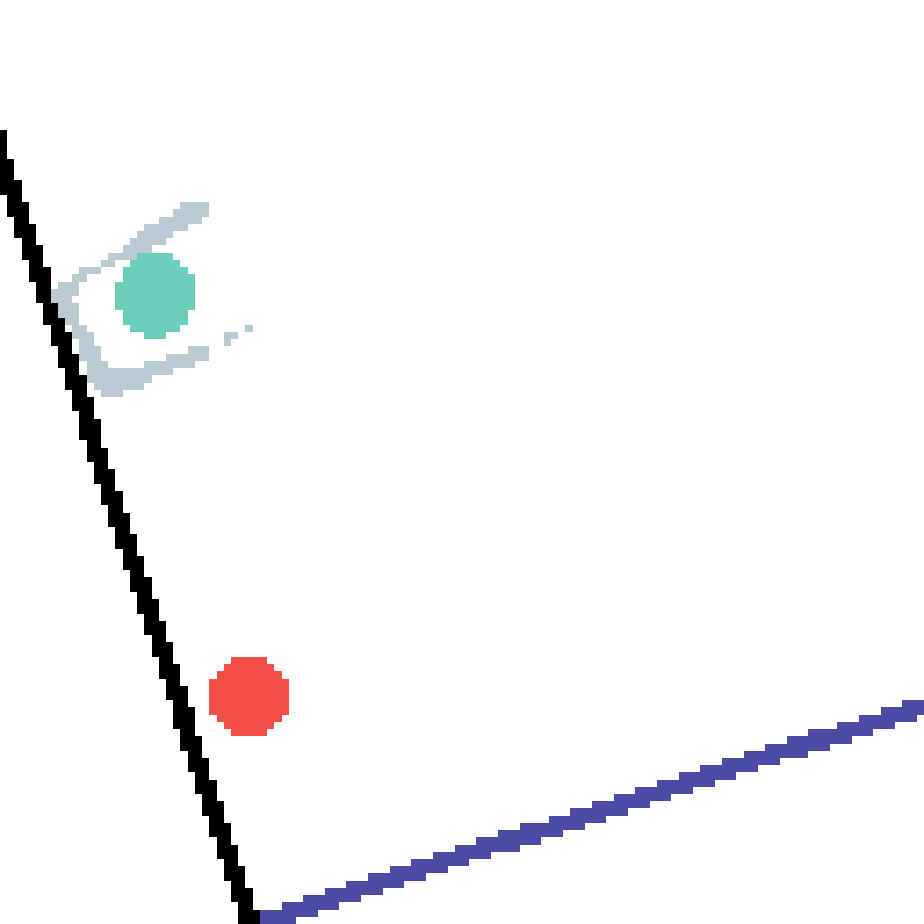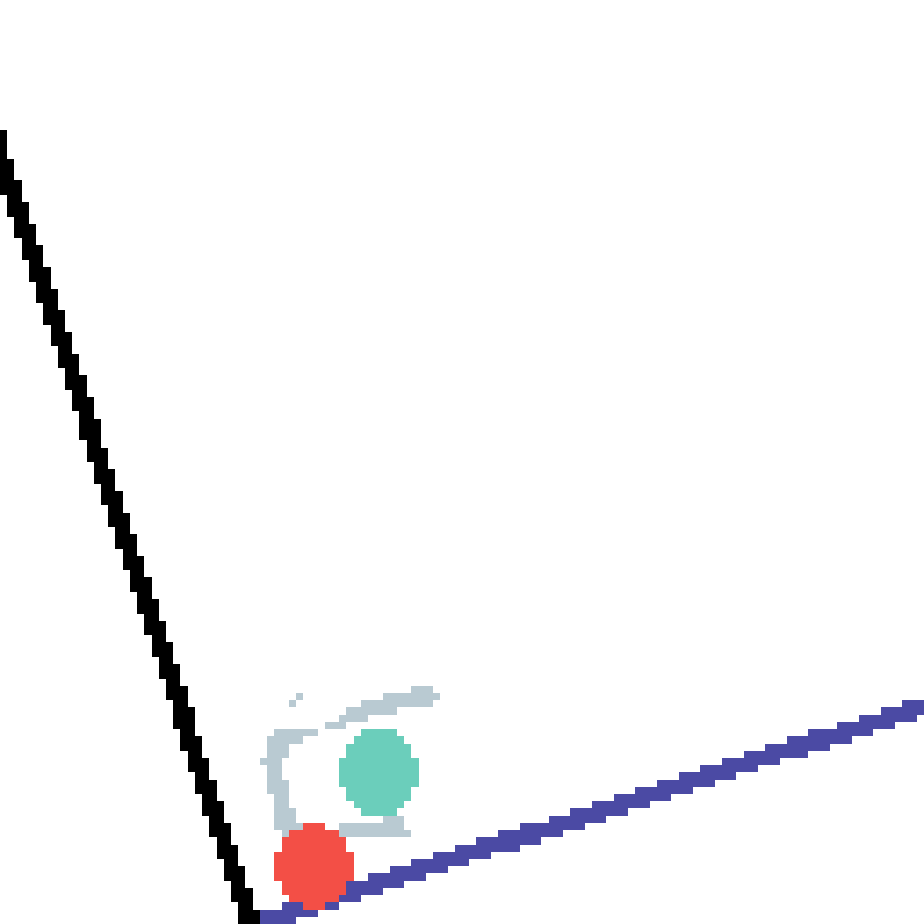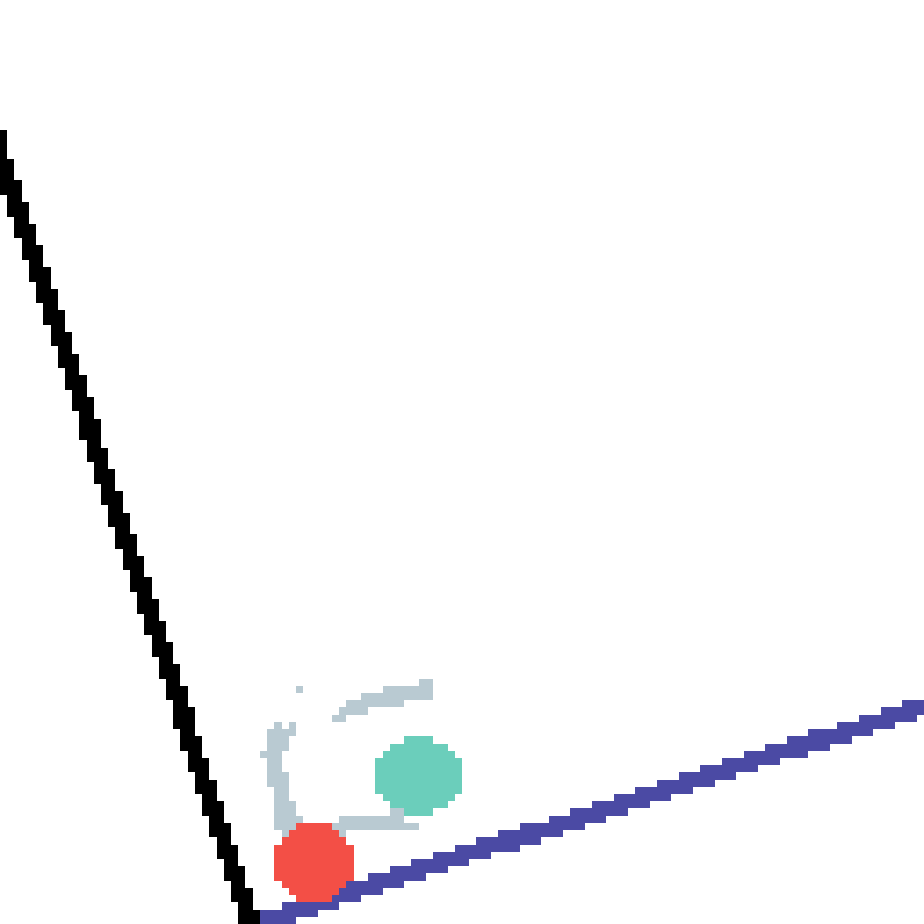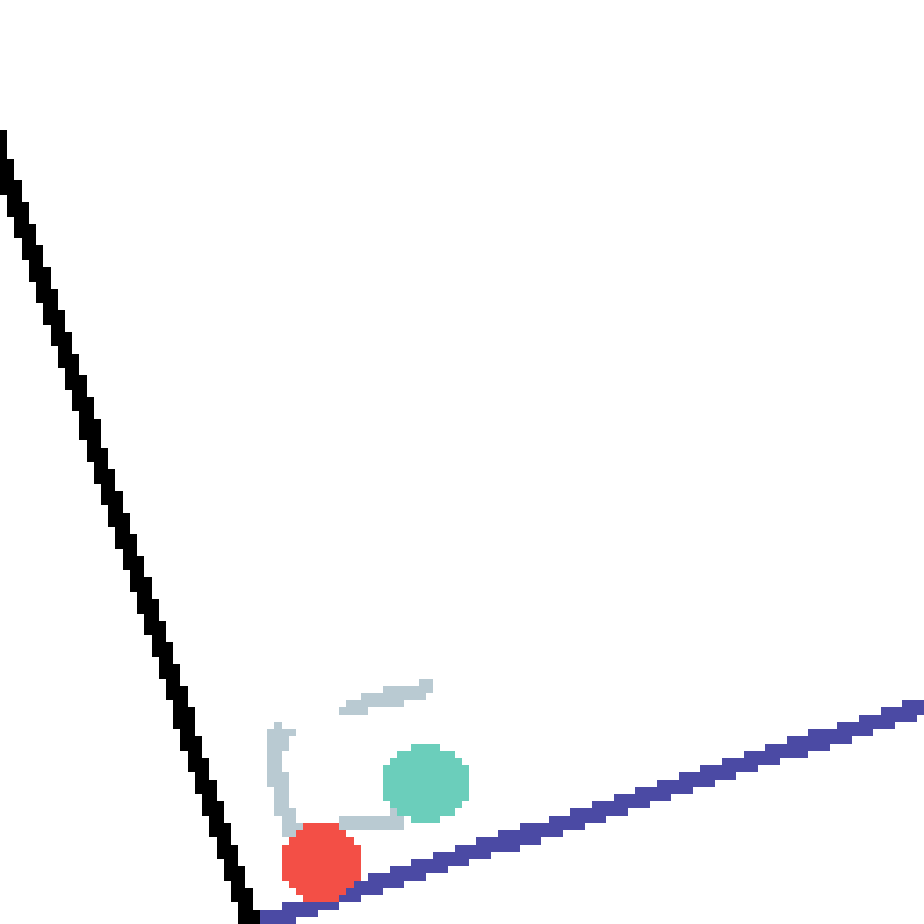
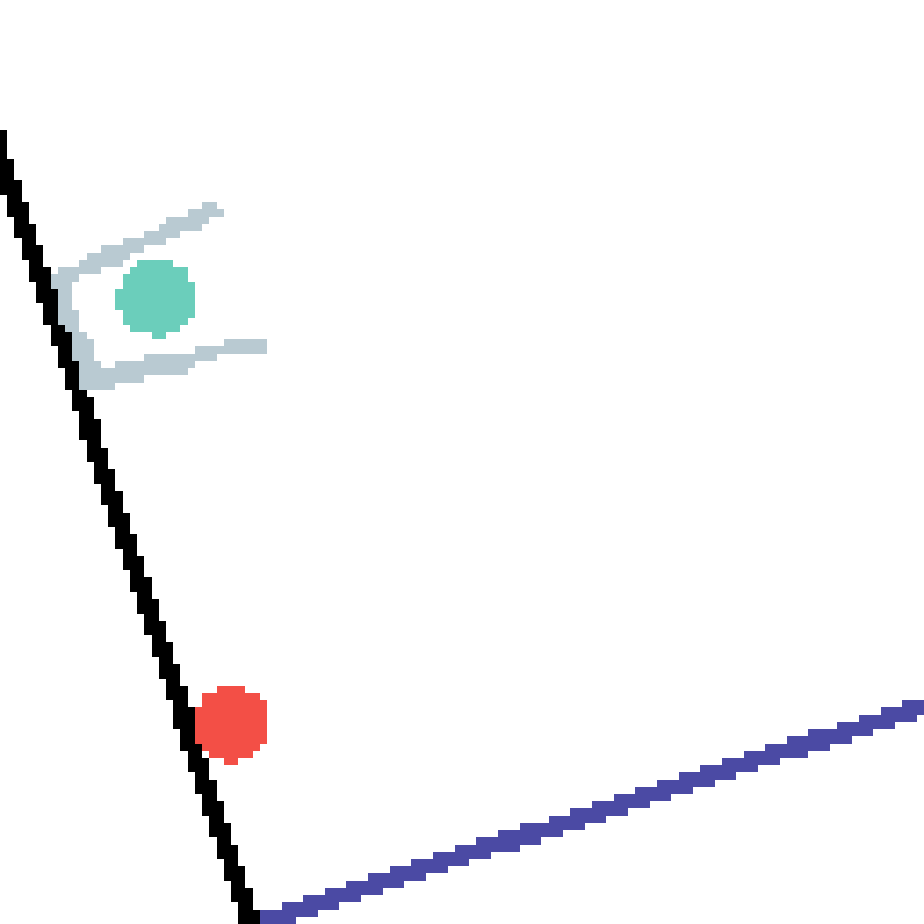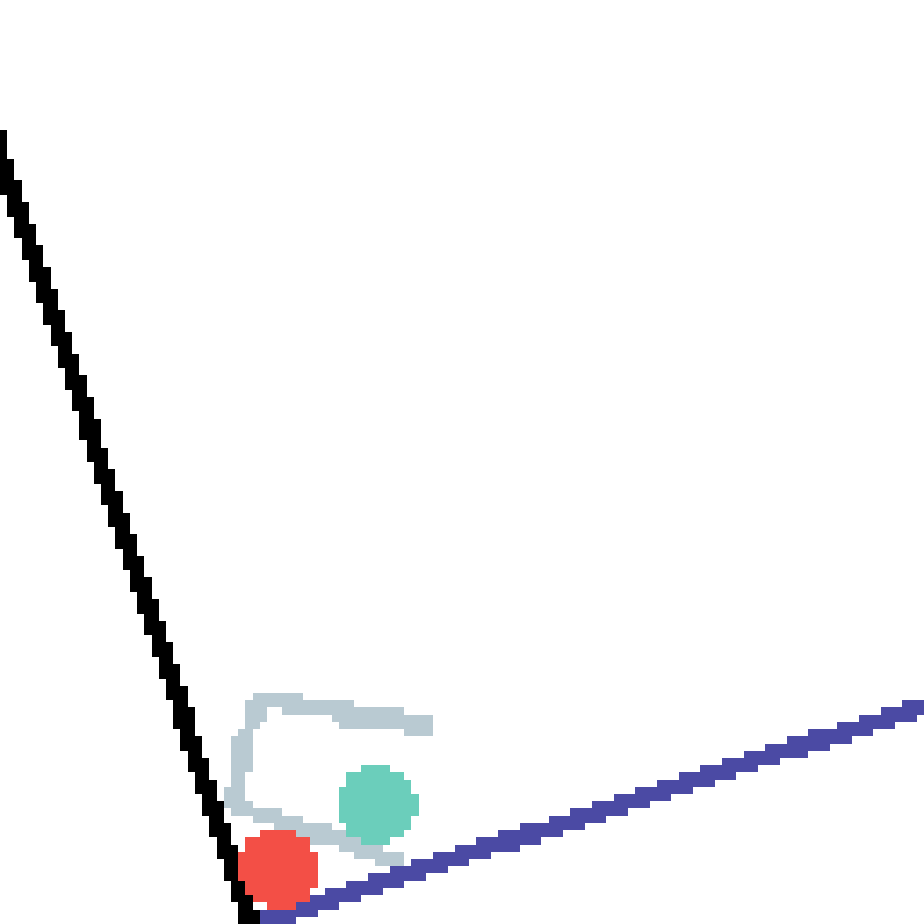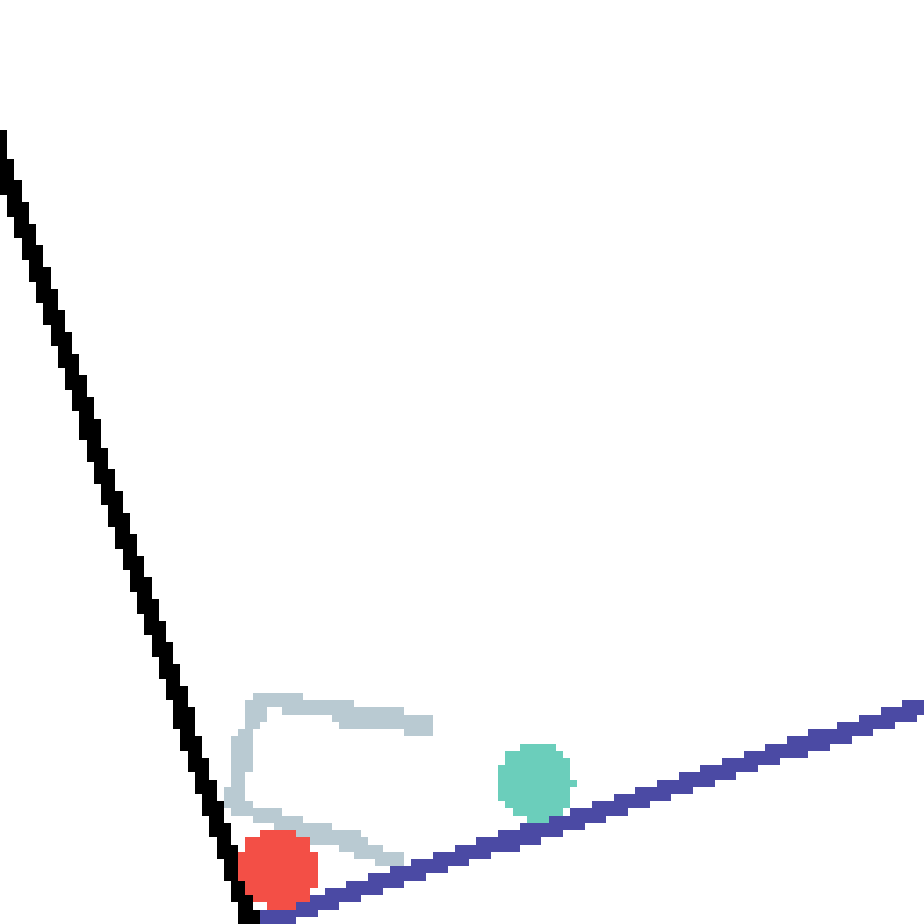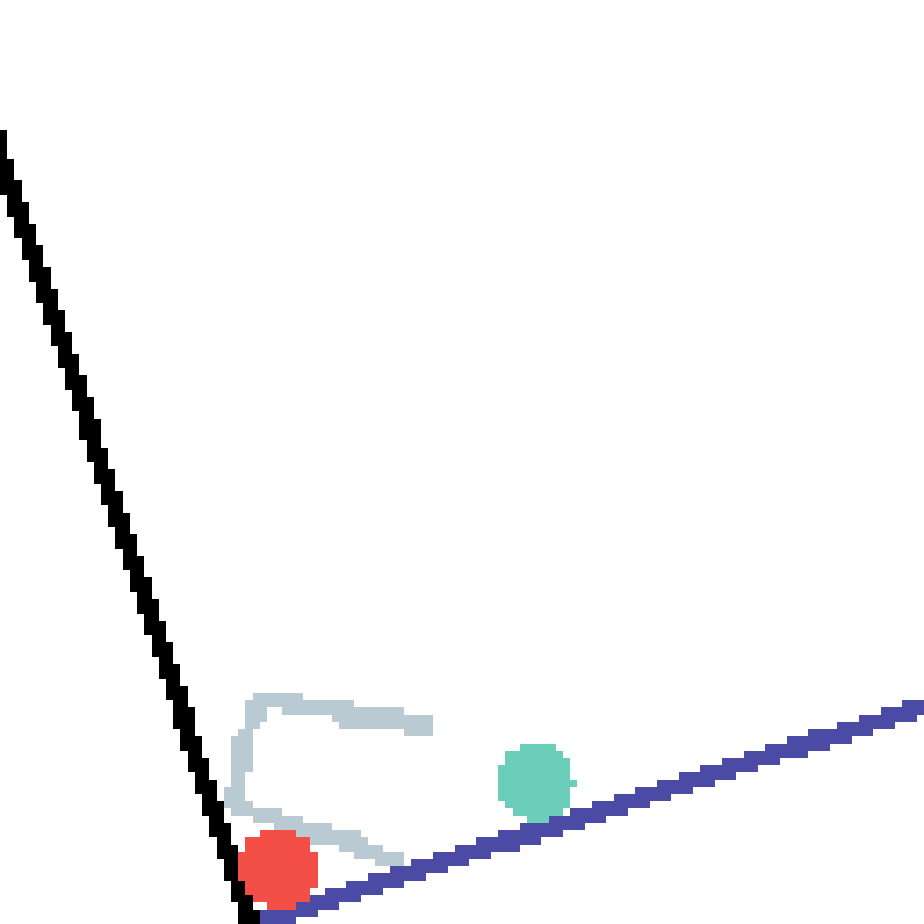
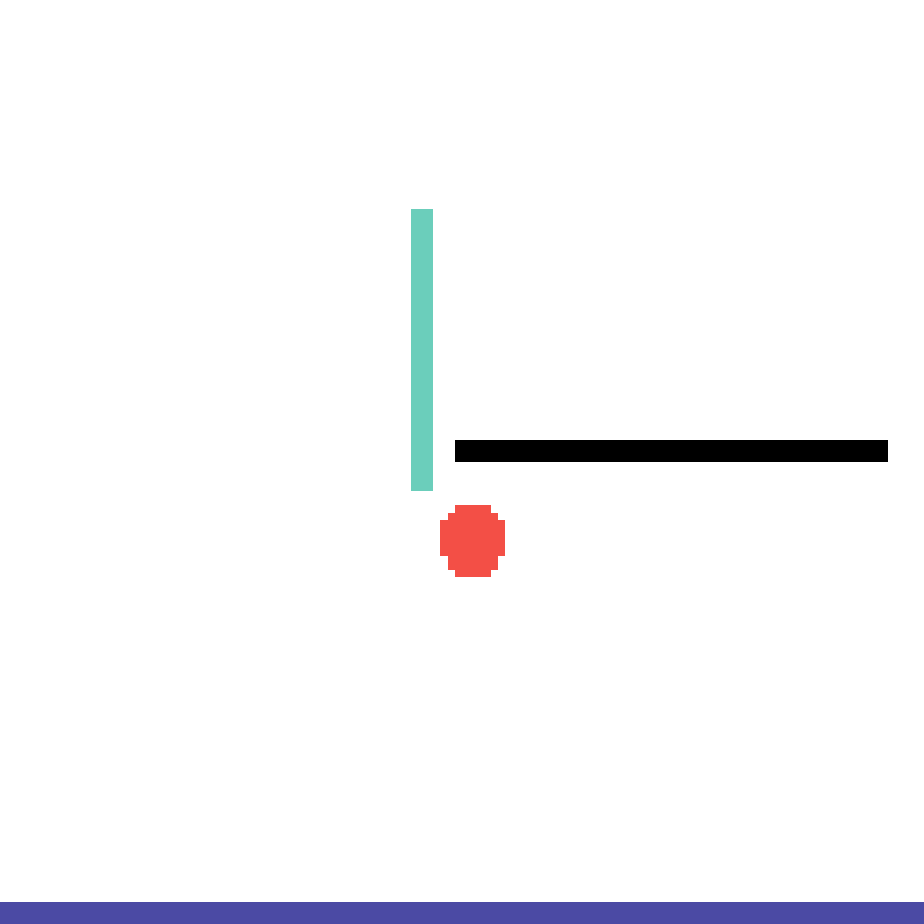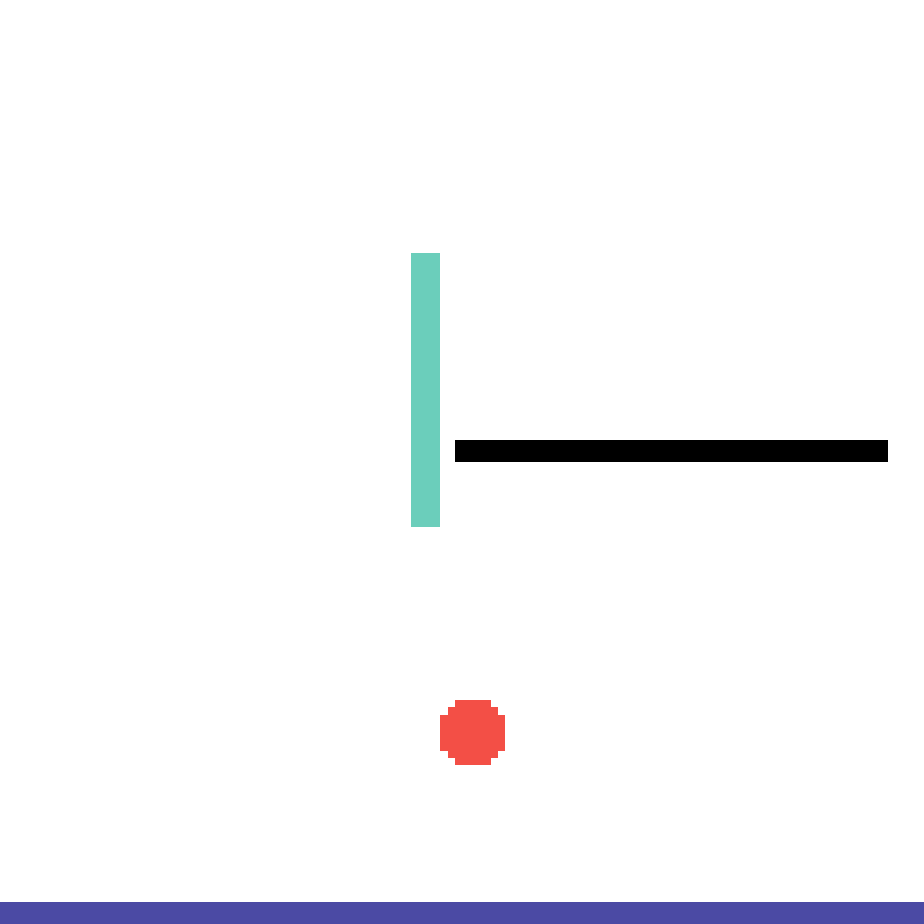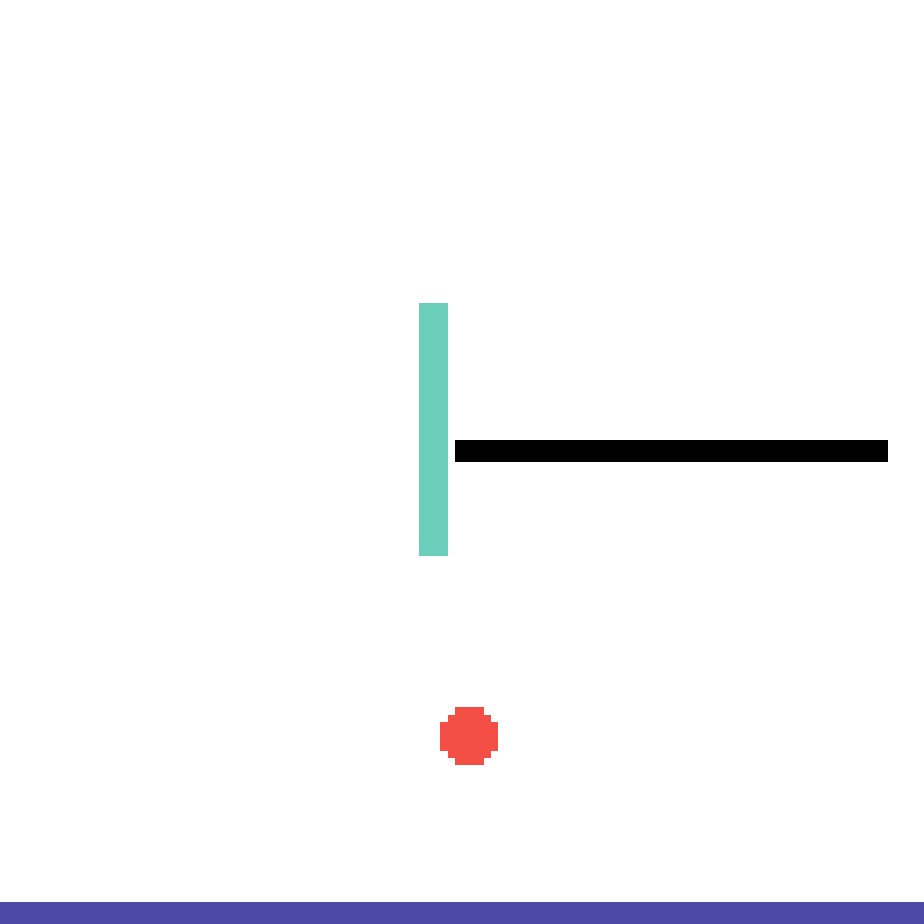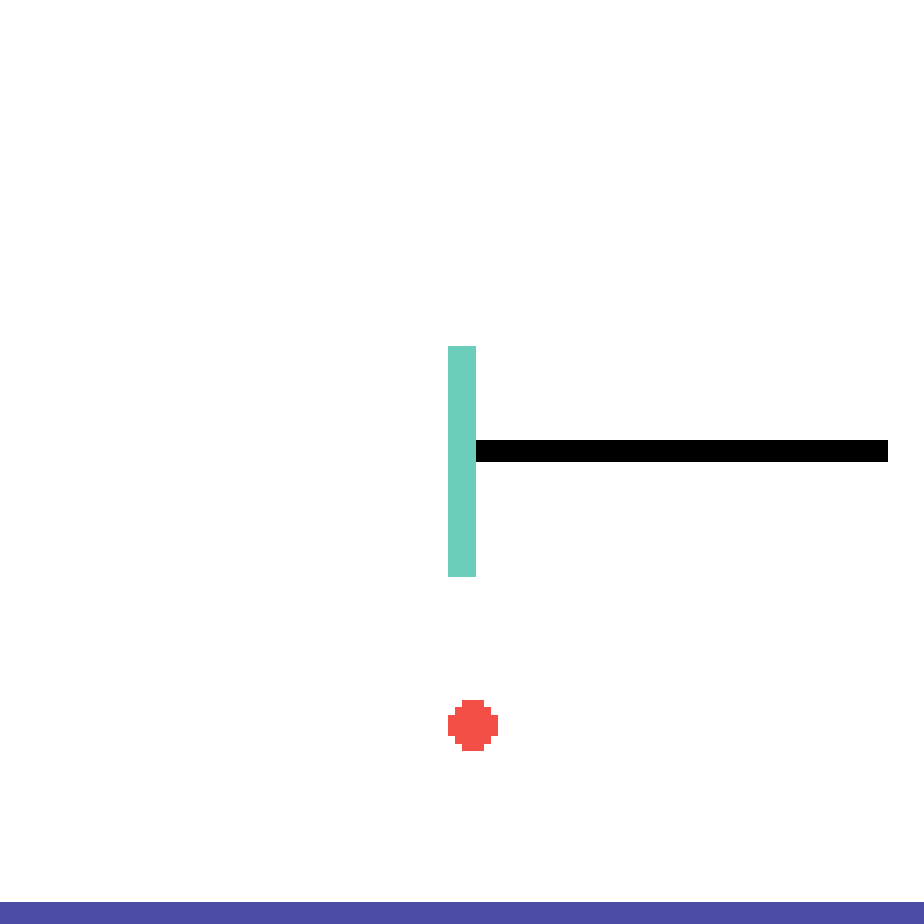
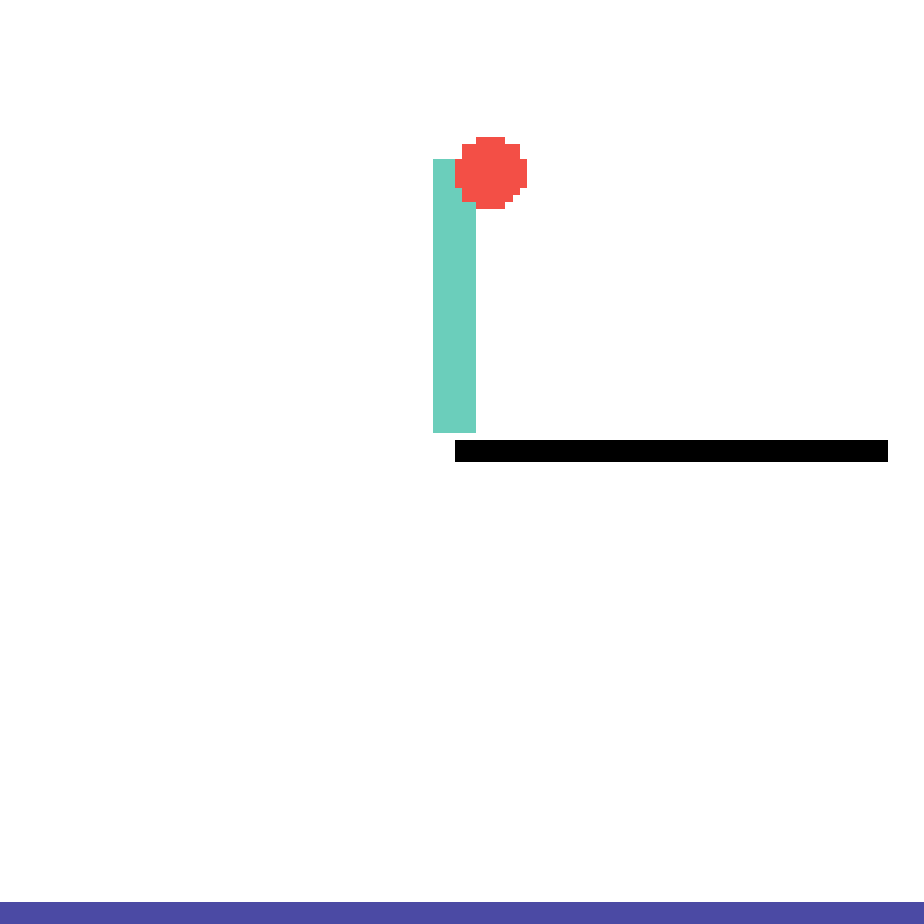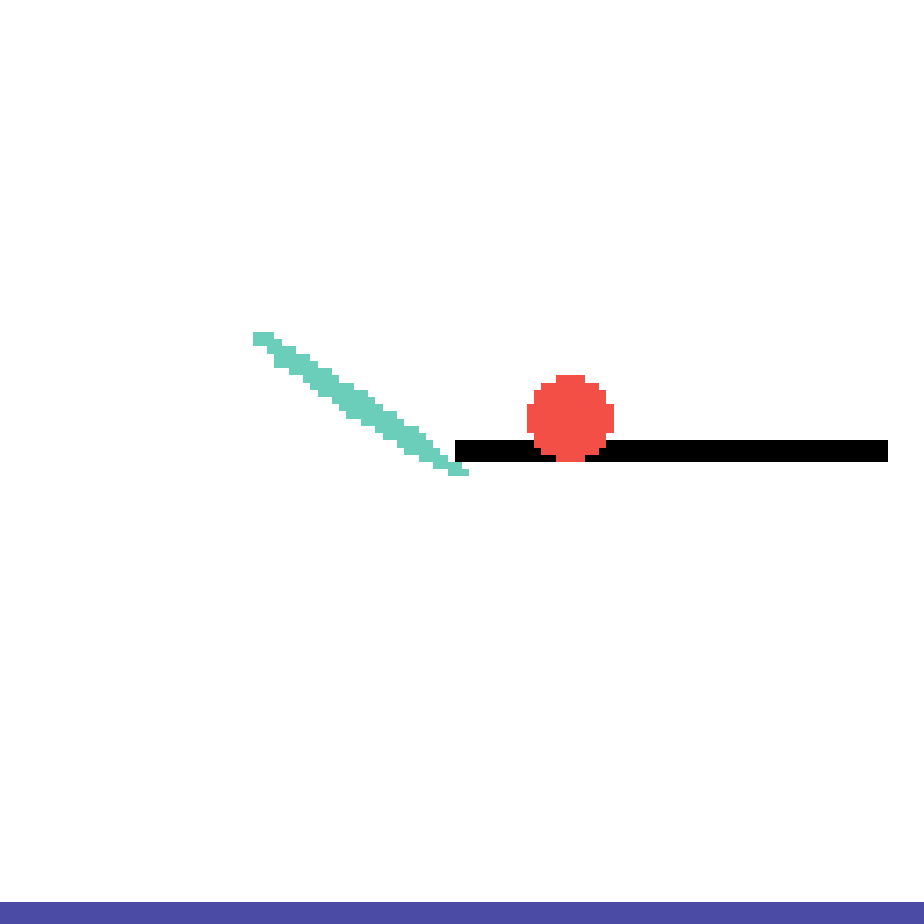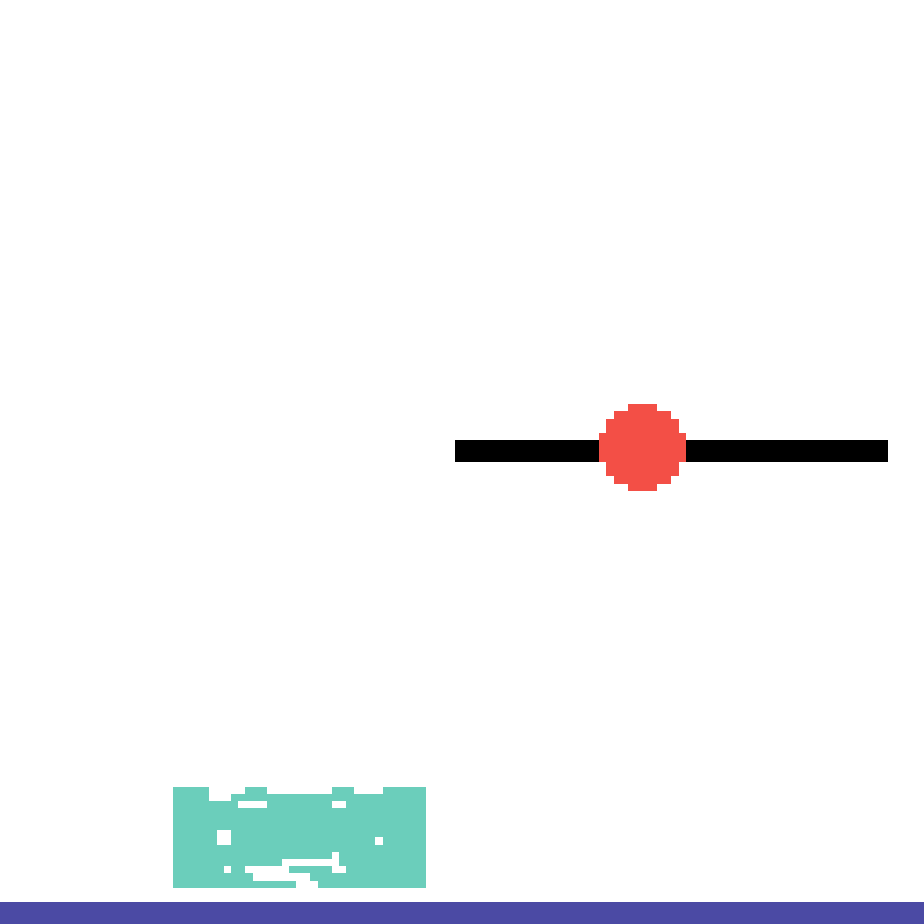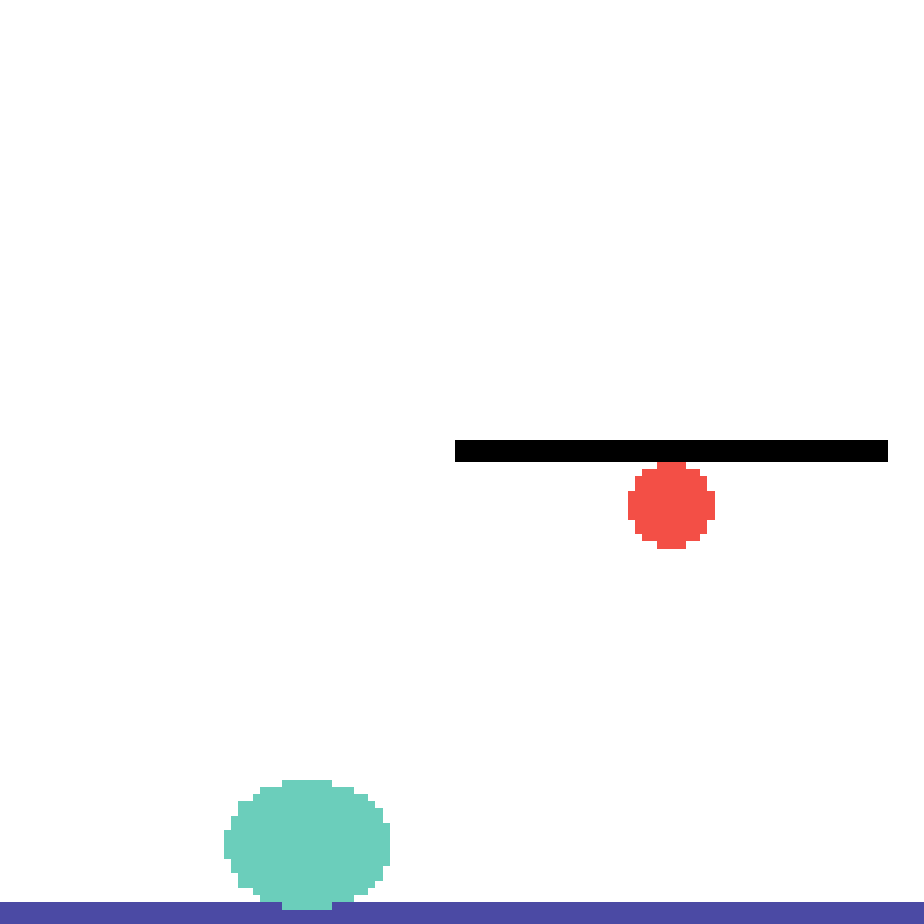
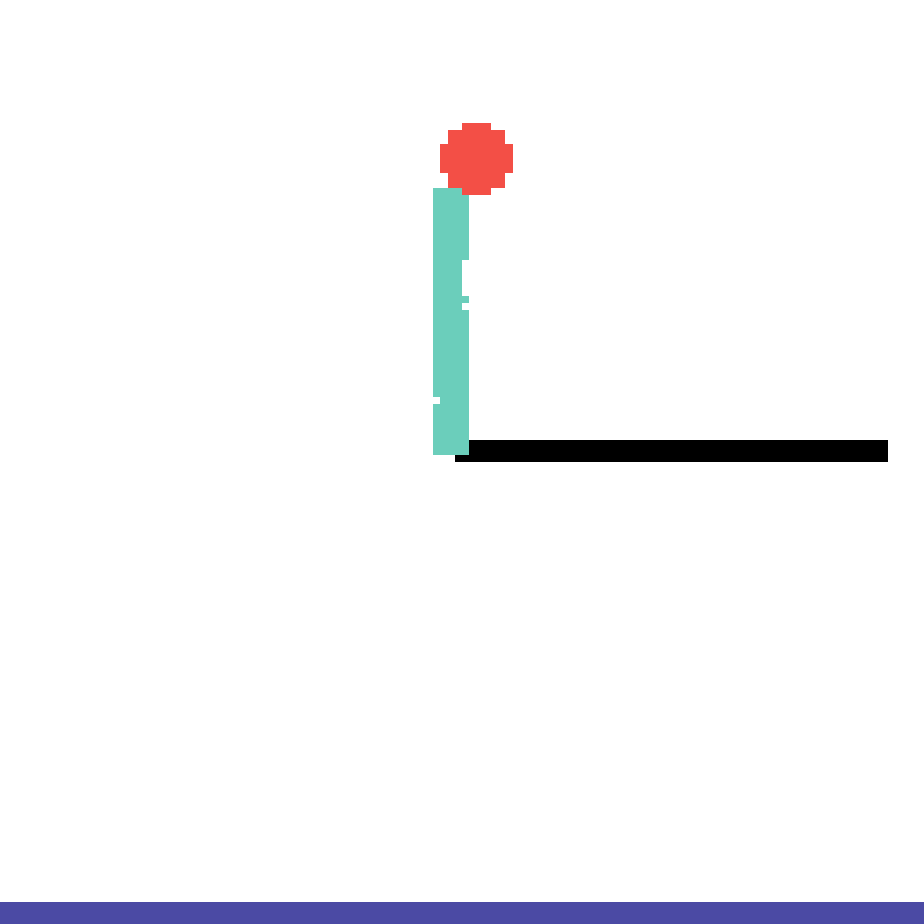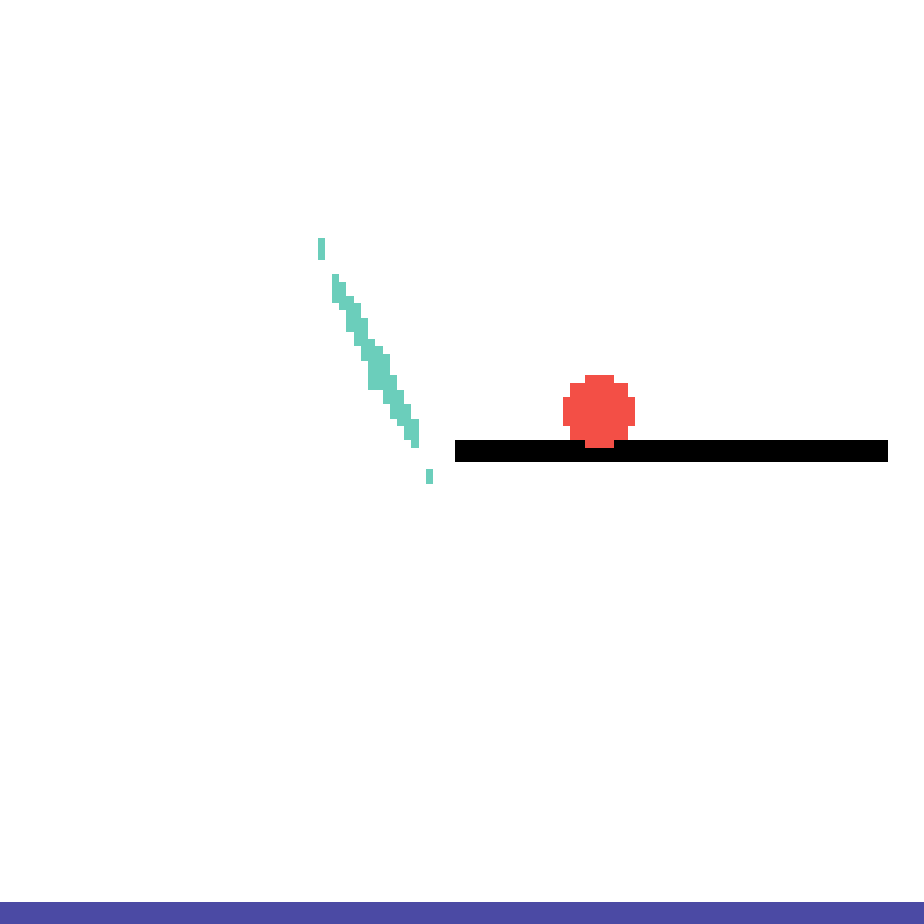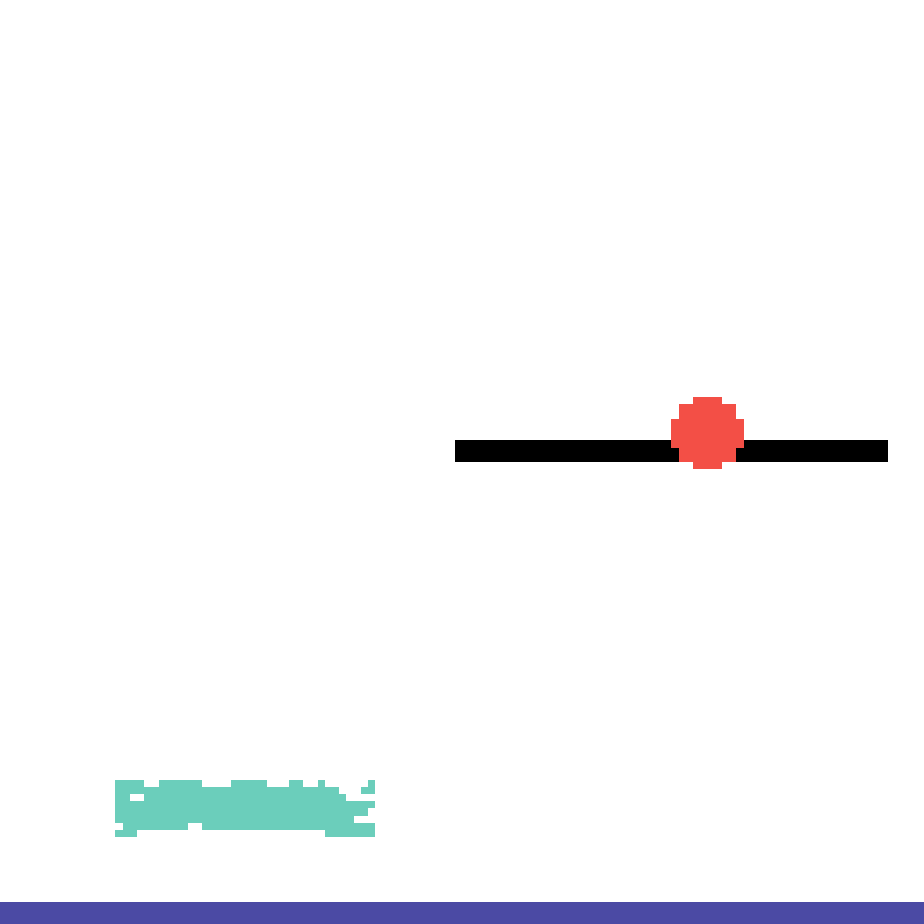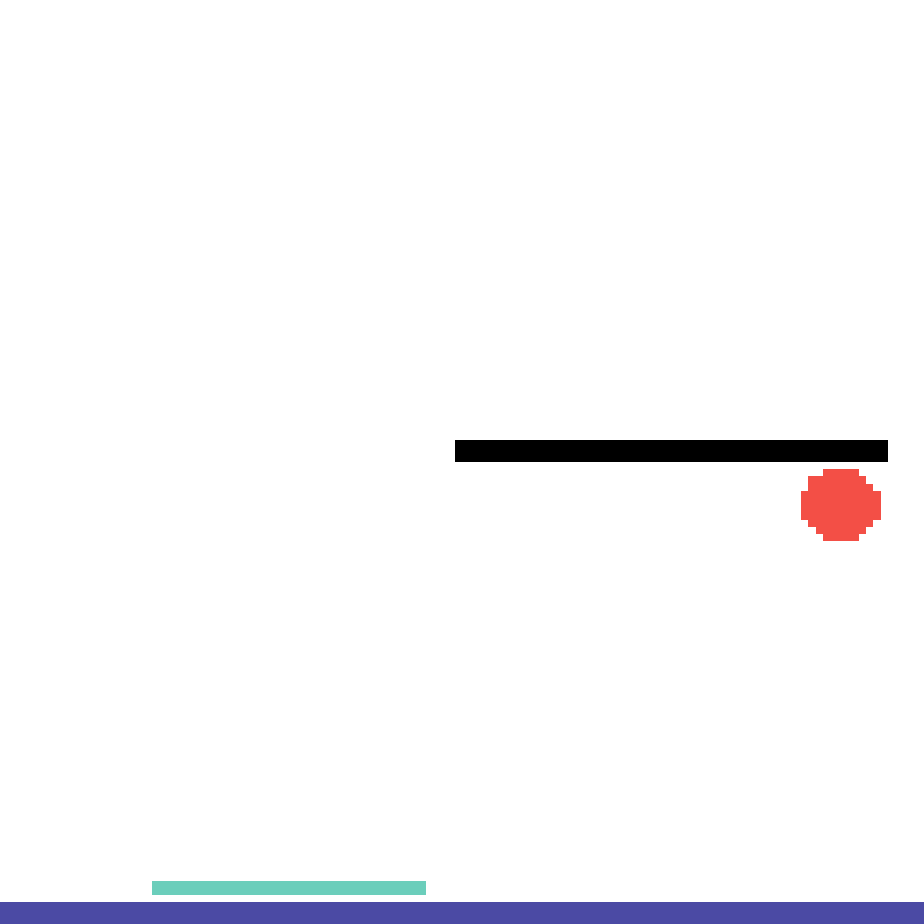
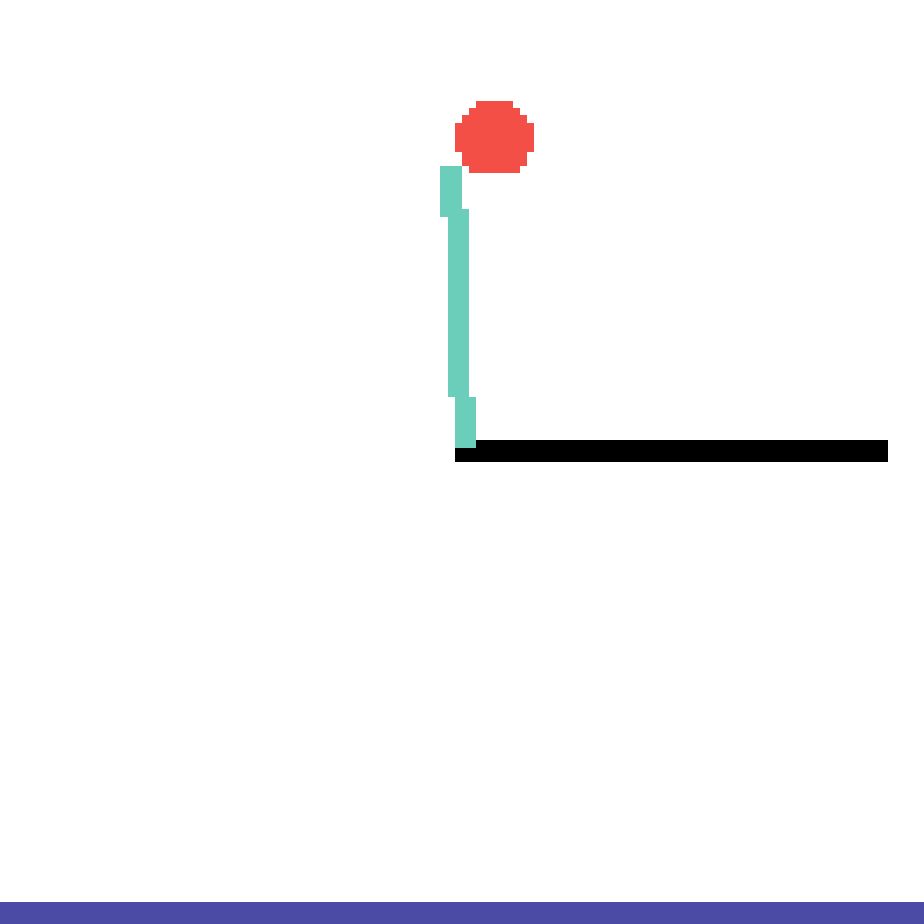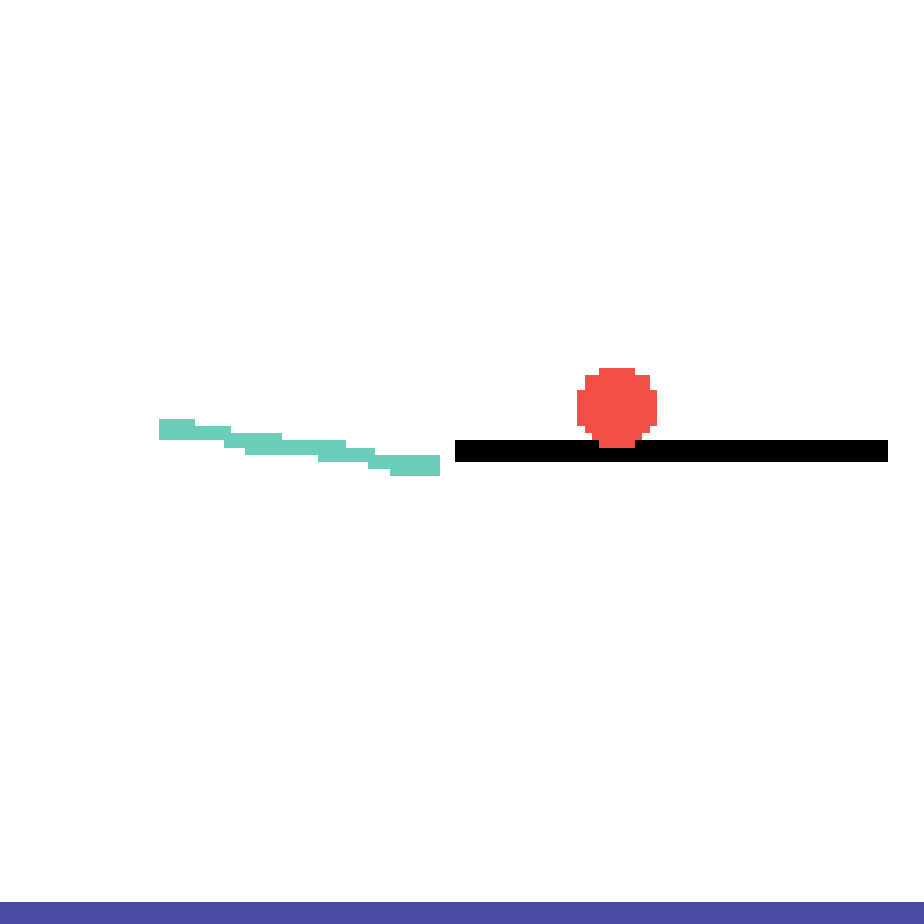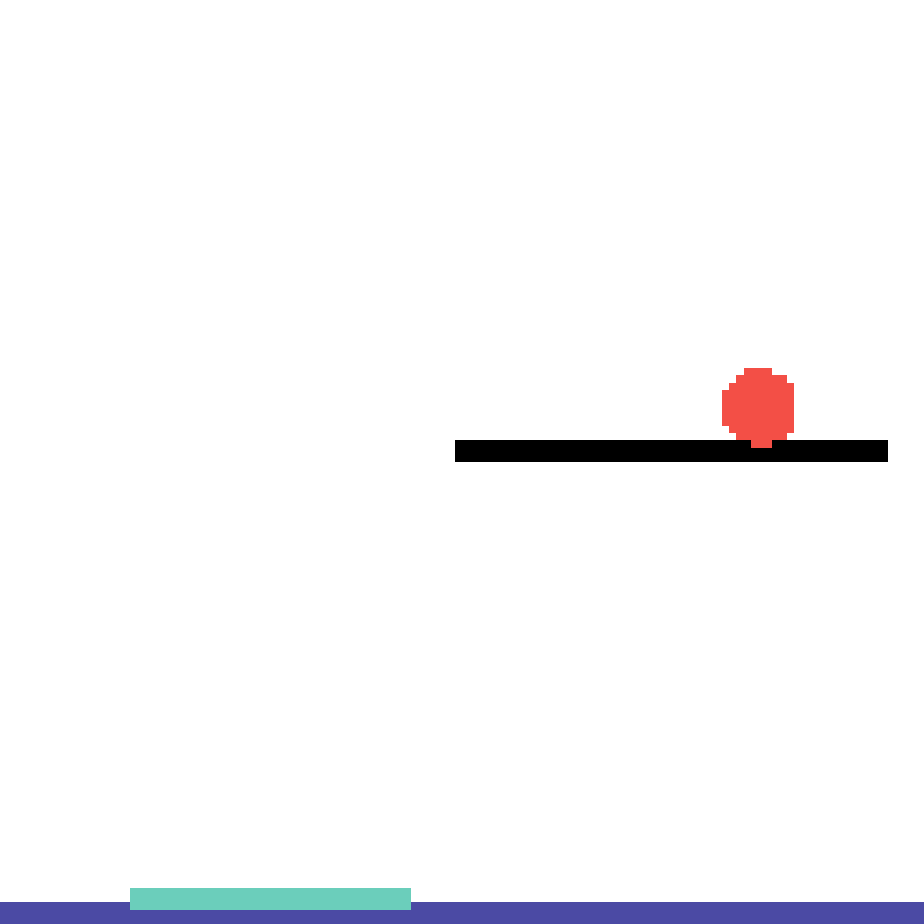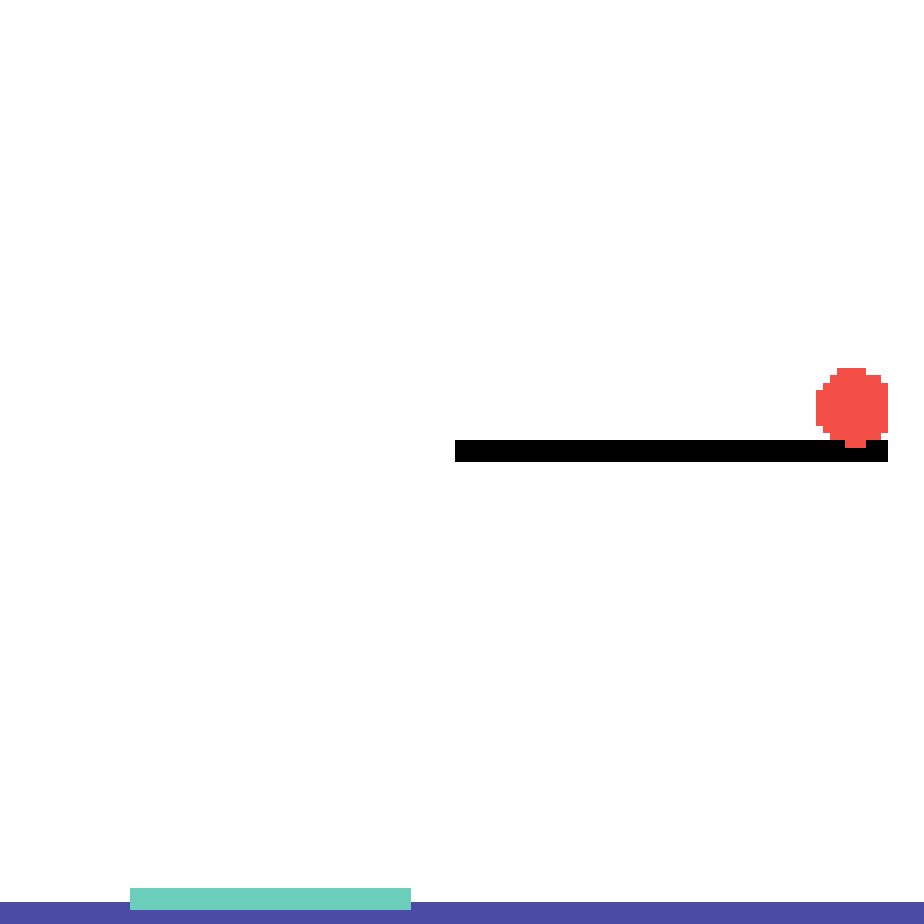
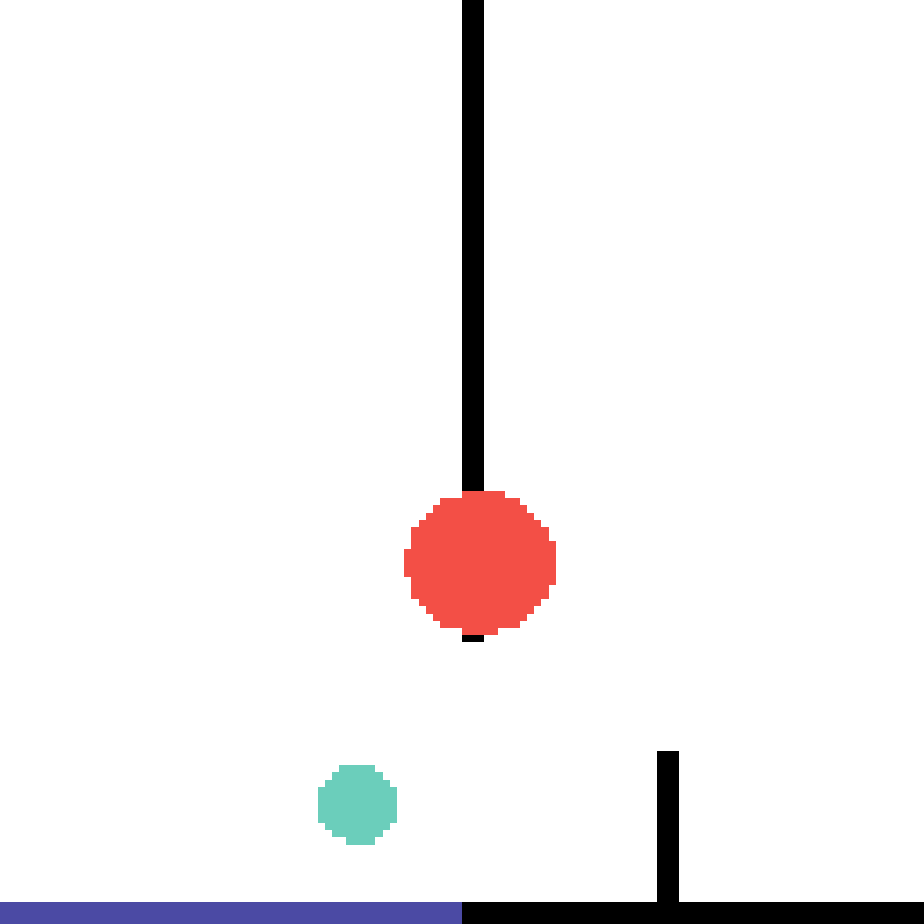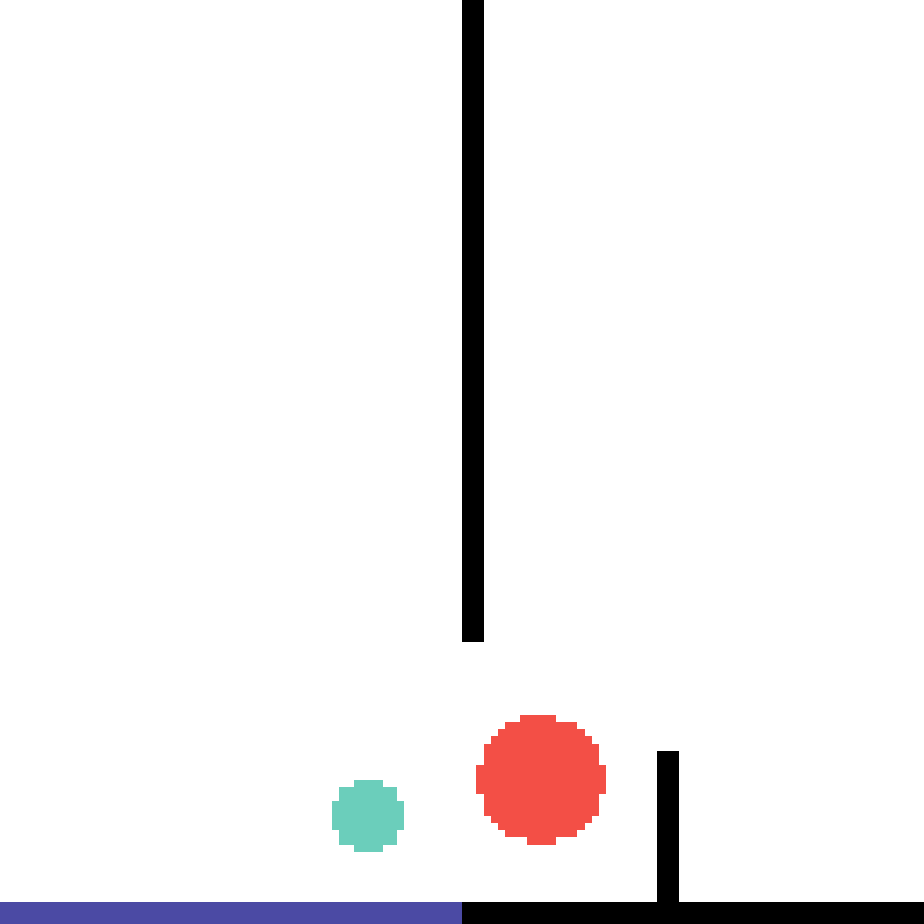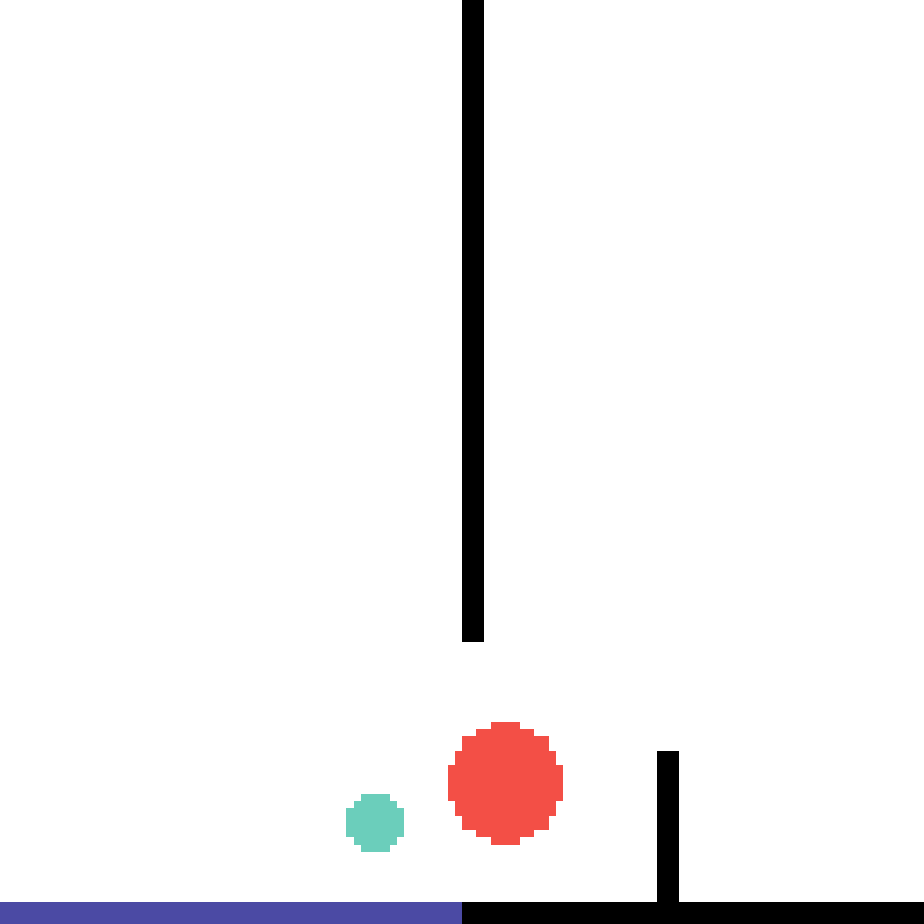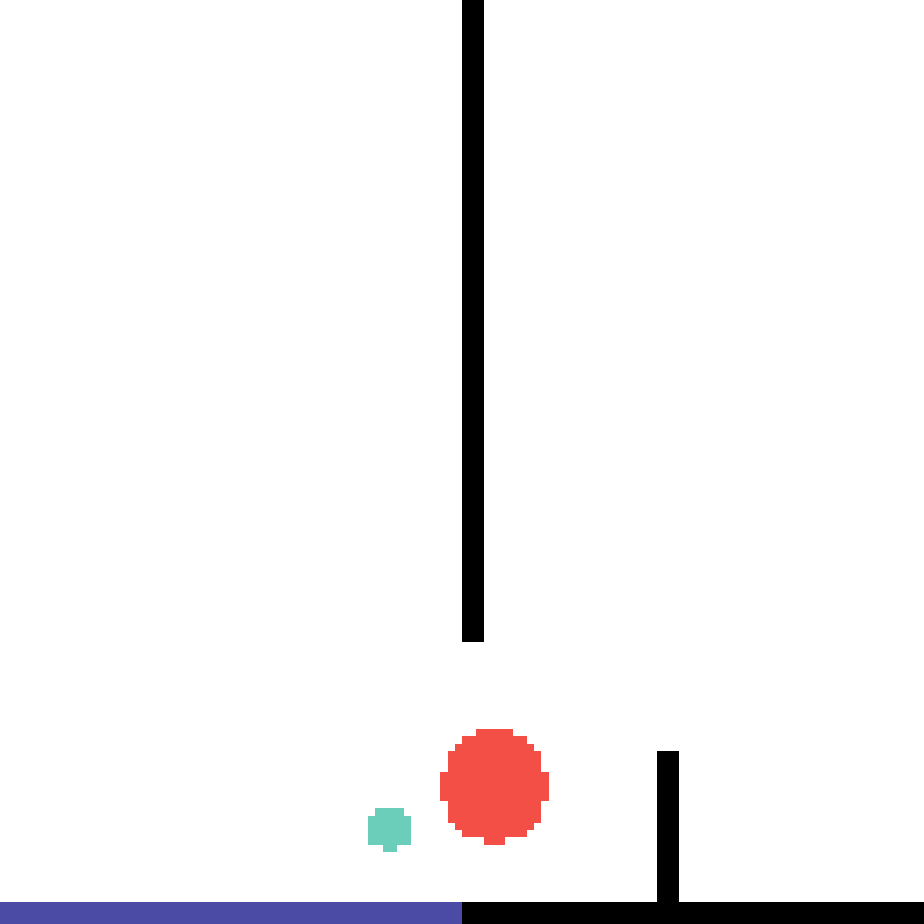
We show our prediction results and baseline prediction results on the test set of PHYRE (cross-task generalization, fold 0). Given the first image and the objects' bounding boxes, we predict the future bounding boxes and masks for each moving objects. The backgrounds (colored purple and black) is taken from the input image. The environments shown here is not seen during training.
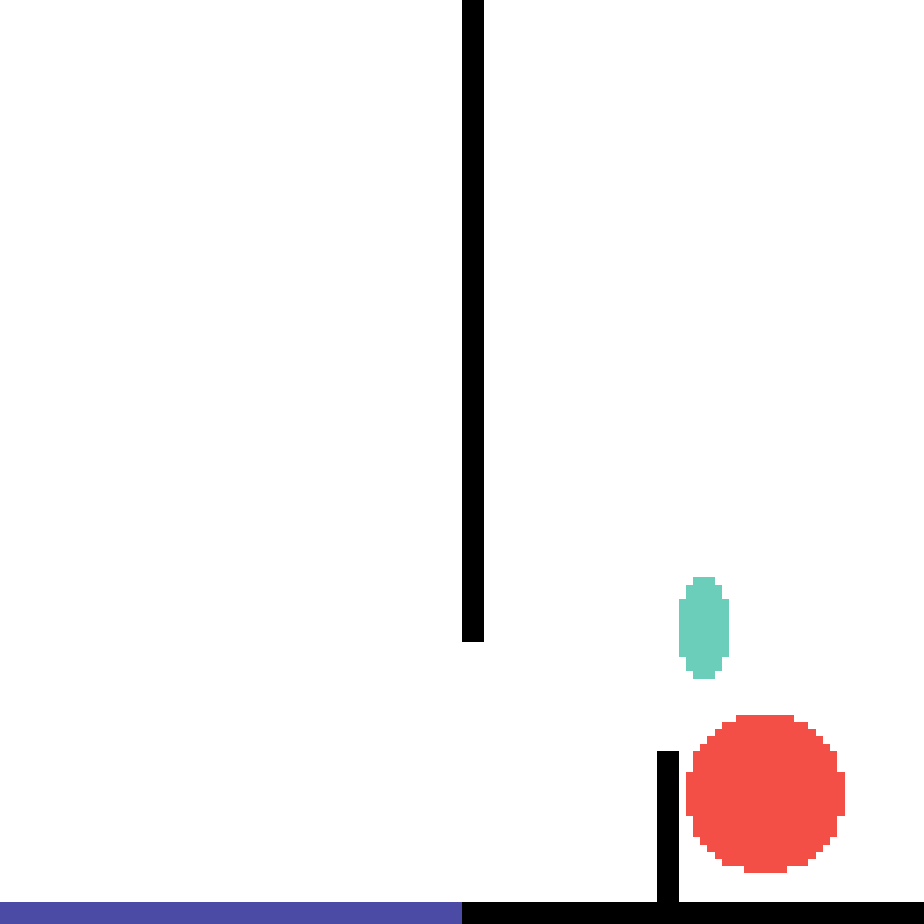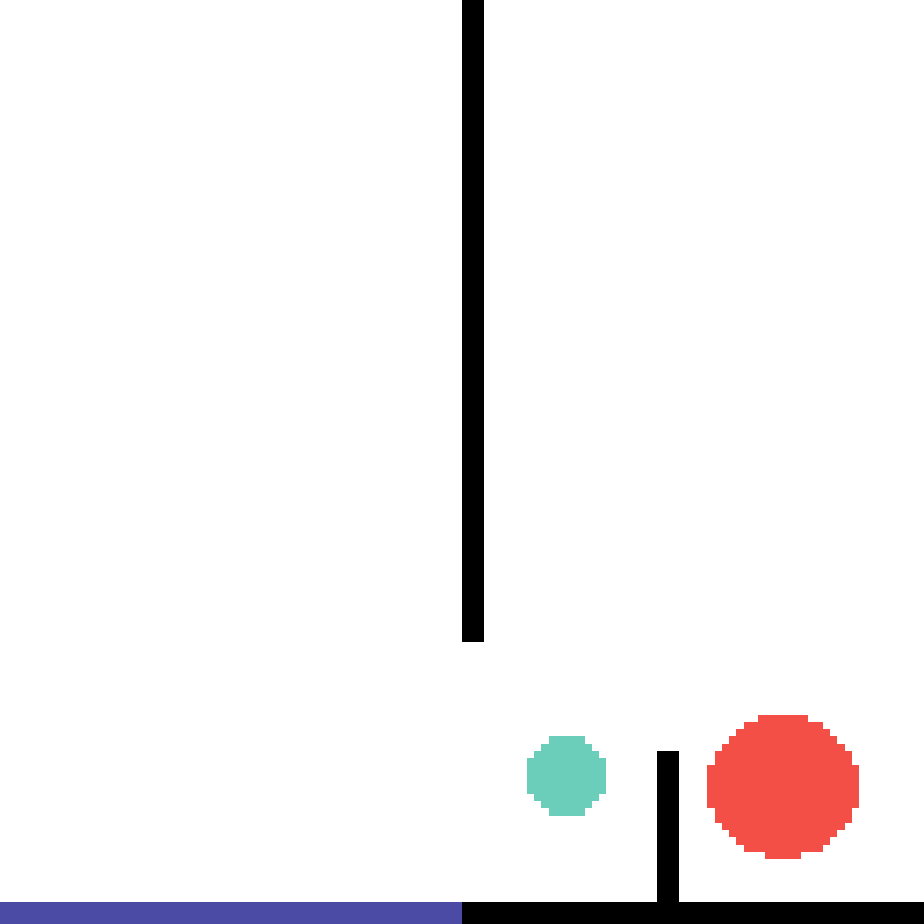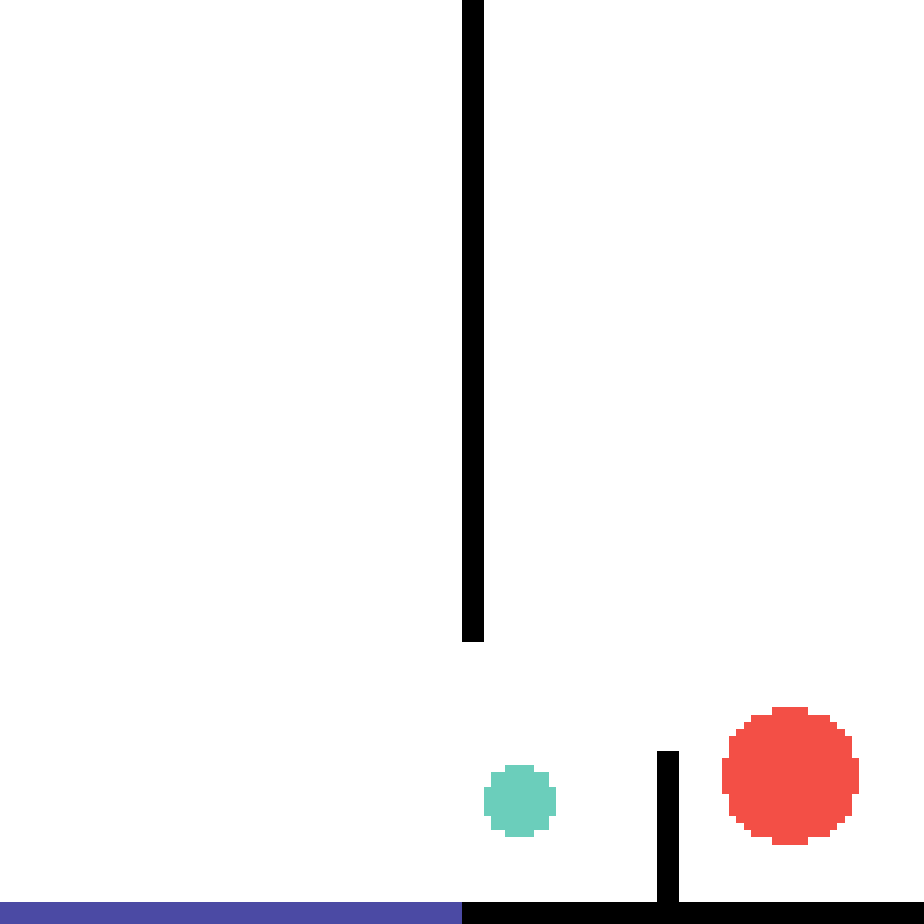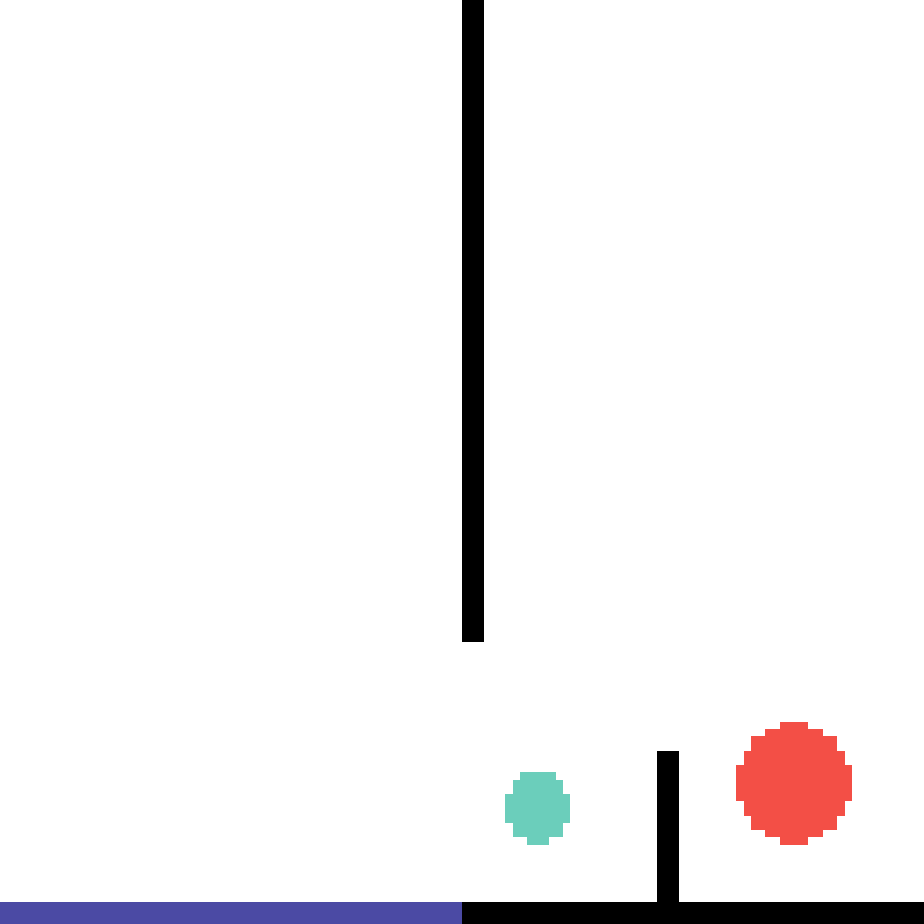

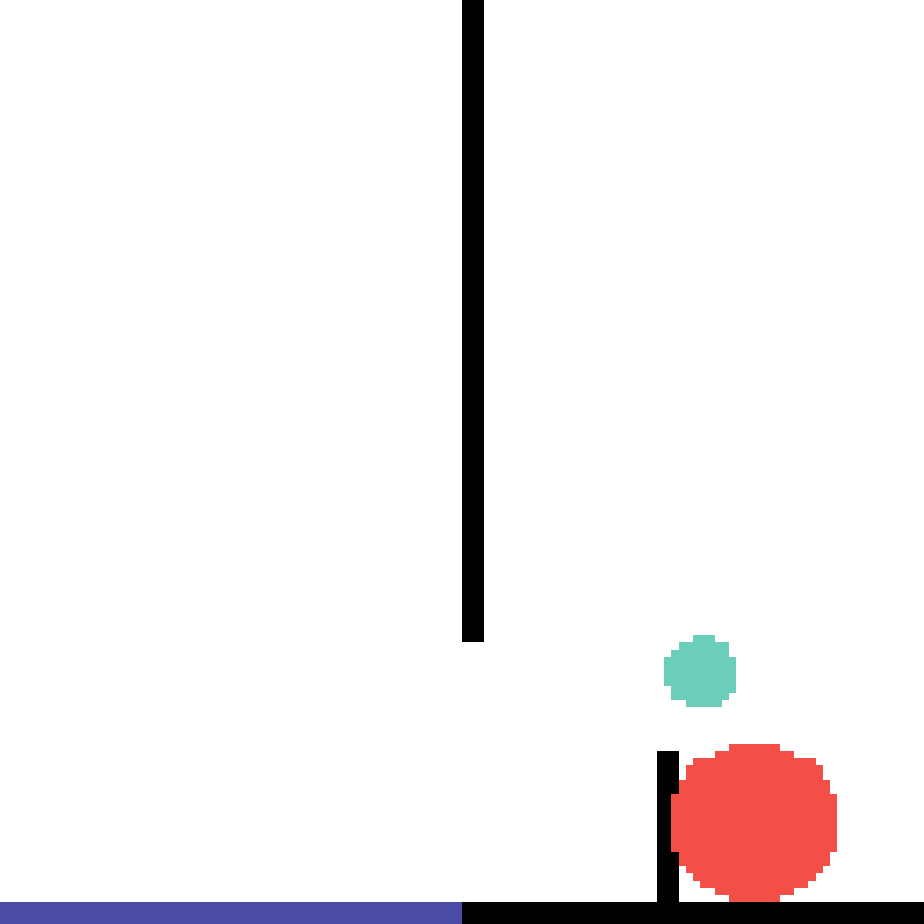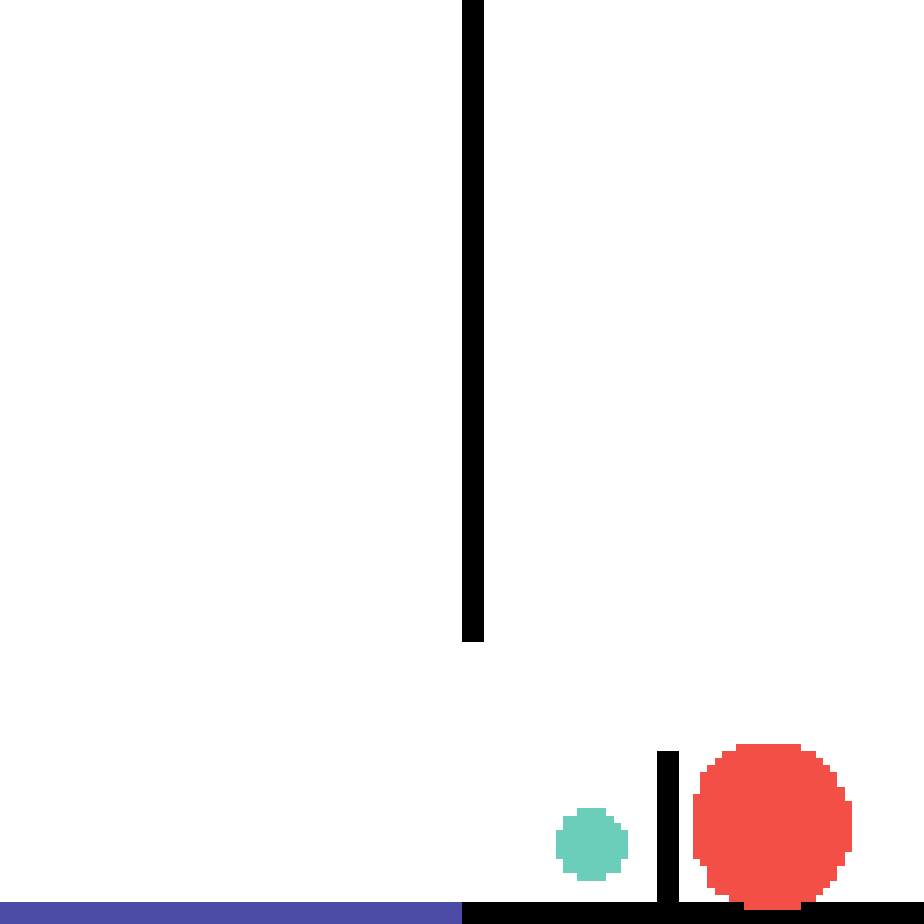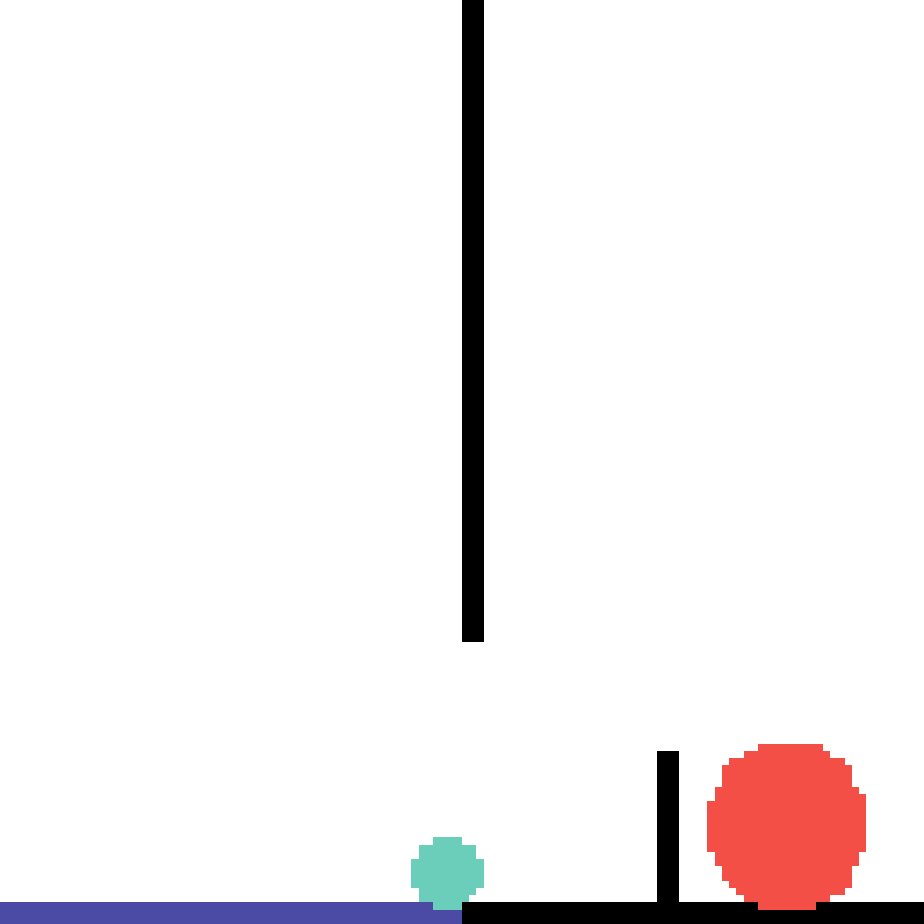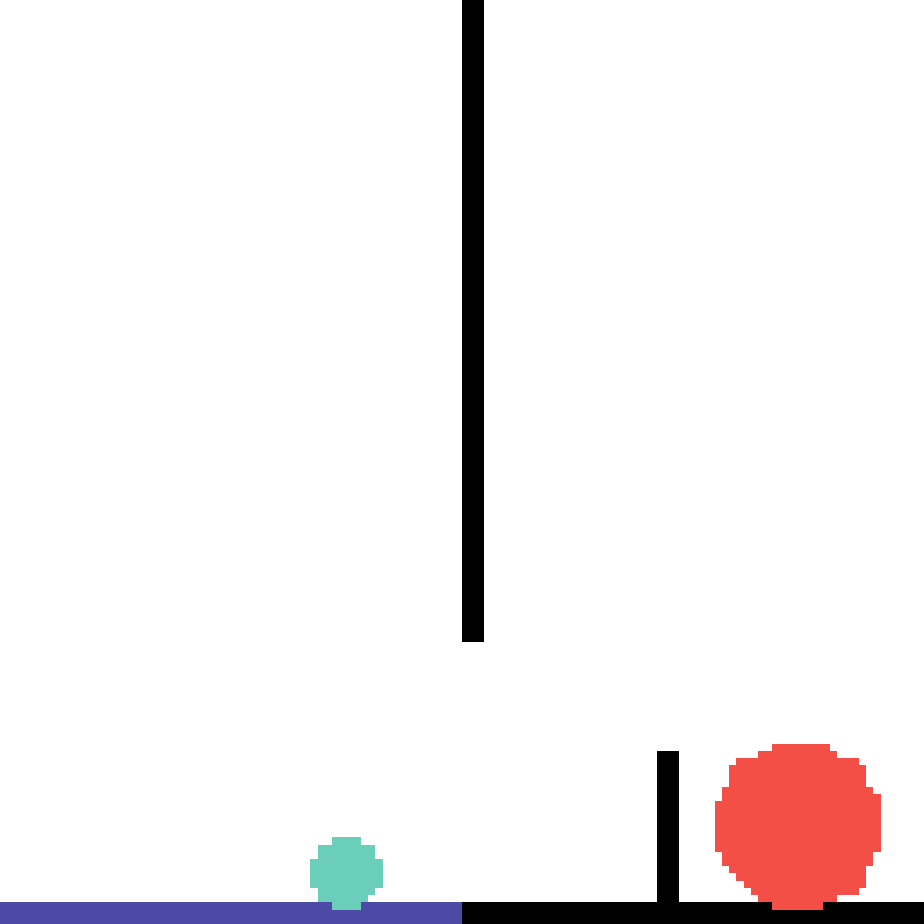


















































Paper

Bibtex
@InProceedings{qi2021learning,
author={Qi, Haozhi and Wang, Xiaolong and Pathak, Deepak and Ma, Yi and Malik, Jitendra},
title={Learning Long-term Visual Dynamics with Region Proposal Interaction Networks},
booktitle={ICLR},
year={2021}
}
Acknowledgements:
This work is supported in part by DARPA MCS and DARPA LwLL. We would like to thank the members of BAIR for fruitful discussions and comments.